인텔 프로세서 - 준비 및 기본 원칙. 프로세서. 프로세서 종류 및 차이점
MP 개발 단계, 관련 업적, 주요 아키텍처 및 기타 특성은 인텔 인텔사 (INTegrated ELectronics)의 MP를 기반으로 자연스럽게 고려됩니다. 또한 AMD (Advanced Micro Devices), Cyrix, Texas Instruments 및 기타 회사에서 인텔 제품과 경쟁을 벌일 수 있습니다.
MP의 주요 매개 변수는 다음과 같습니다.
- 클록 주파수;
- 칩의 집적도 (얼마나 많은 트랜지스터가 칩에 포함되어 있는가);
- 내부 데이터 폭 (MP가 동시에 처리 할 수있는 비트 수).
- 외부 데이터 폭 (다른 요소와 CPU 데이터를 교환하는 과정에서 동시에 전송되는 비트의 수).
- 주소 가능 메모리 (주소 비트 수에 따라 다름).
인텔 프로세서
(1993 년 3 월 22 일). 펜티엄은  32 비트 주소 버스 및 64 비트 데이터 버스가있는 수퍼 스칼라 프로세서로, 310 만개의 트랜지스터 (16.25cm2 영역)로 구성된 호환 가능한 MOS 구조의 서브 마이크론 기술을 사용하여 제조되었습니다. 프로세서에는 다음과 같은 장치가 포함됩니다.
32 비트 주소 버스 및 64 비트 데이터 버스가있는 수퍼 스칼라 프로세서로, 310 만개의 트랜지스터 (16.25cm2 영역)로 구성된 호환 가능한 MOS 구조의 서브 마이크론 기술을 사용하여 제조되었습니다. 프로세서에는 다음과 같은 장치가 포함됩니다.
- 코어 (코어). 주 액츄에이터. 66MHz의 클록 주파수에서의 MP 성능은 약 1 억 2 천만 팀 (MIPS)입니다. 80486 DX 프로세서와 비교할 때 여러 명령을 동시에 실행할 수있는 두 개의 파이프 라인 덕분에 성능이 5 배 향상되었습니다.
- Branch Predictor는 프로그램 브랜치의 방향을 추측하고 프리 페치 및 디코드 명령 블록에 정보를 미리로드하려고 시도합니다.
- 점프 주소 버퍼 (지점 대상 버퍼 BTB)는 동적 점프 예측을 제공합니다. 행동의 원칙 : "예측이 사실이라면 효율은 증가하고, 그렇지 않다면 컨베이어를 완전히 떨어 뜨려야합니다." 인텔에 따르면 펜티엄 프로세서의 전환 예상 정확도는 75-80 %입니다.
- 부동 소수점 처리는 부동 소수점 처리를 수행합니다. 그래픽 정보 처리, 멀티미디어 응용 프로그램 및 계산 문제 해결을위한 PC의 집중적 인 사용은 부동 소수점 연산을 수행 할 때 높은 성능이 필요합니다.
- 레벨 1 캐시. 프로세서에는 각각 8KB의 메모리 뱅크가 2 개 있습니다. 첫 번째는 명령 용이고 두 번째는 더 큰 외부 메모리 캐시 (L2 캐시)보다 빠른 데이터 용입니다.
- 버스 인터페이스. 명령 및 데이터 스트림을 CPU로 전송하고 CPU에서 데이터를 전송합니다.
펜티엄 프로세서는 시스템 관리 모드 SMM (System Management Mode)을 도입했습니다. 이 모드를 사용하면 전원 관리 또는 보호, OS 및 실행중인 응용 프로그램에 대한 투명성을 포함하여 매우 높은 수준의 시스템 기능을 구현할 수 있습니다.
60MHz 이상의 클럭 주파수로의 전환은 중요한 업적이었으며, 따라서 냉각 문제가 해결되었습니다 (프로세서 표면은 최대 85 ° C까지 가열 됨).
(1995 년 11 월 1 일). 성능을 향상시키기 위해 Pentium Pro는 2 차 수준의 버퍼 메모리 (캐시)를 사용하여 256KB 용량을 별도의 칩에 배치하고 CPU 패키지에 탑재했습니다. 결과적으로 5 개의 액추에이터를 효율적으로 언로드 할 수있게되었습니다. 두 개의 정수 연산 블록, 로드 블록; 기록 유닛; FPU (부동 소수점 연산 - 부동 소수점 연산을위한 장치).
펜티엄 P55 (펜티엄 MMX), January 8, 1997. 펜티엄 MMX - 추가 기능이있는 펜티엄 버전. MMX 기술은 컴퓨터의 멀티미디어 기능을 추가 / 확장해야했습니다. 멀티미디어 소프트웨어의 특징 인 알고리즘 및 데이터 유형에 초점을 맞춘 SIMD 기술이 구현되었습니다. MMH 1997 년 1 월, 166과 200 MHz의 클럭 주파수, 같은 해 6 월에 발표 된 버전은 233 MHz로 나타났다. 기술적 인 프로세스 0.35 미크론, 4.5 백만개의 트랜지스터.
(1997 년 5 월 7 일). 이 프로세서는 Pentium Pro에서 MMX 기능을 수정 한 것입니다. 첫 번째 PII는 데스크탑 하이 엔드 (하이 엔드) 컴퓨터 용 프로세서로 발표됩니다. 케이스 디자인이 변경되었습니다. 접촉이있는 실리콘 웨이퍼를 카트리지로 교체하고 버스 주파수와 클럭 주파수를 높이고 MMX 명령을 확장했습니다.
또한 노트북을위한 모델이 있습니다 - Pentium II PE 및 워크 스테이션 - Pentium II Heon 450 MHz.
셀러론 (1998 년 4 월 15 일). Celeron은 저렴한 컴퓨터를위한 P2의 단순화 된 버전입니다. 제 2 수준 캐시 주파수 버스의 양에있는이 가공업 자의 주요 다름. 이 모든 프로세서는 0.25 미크론 기술로 제조되었으며 7.5-19 백만개의 트랜지스터를 갖추고 있습니다.
(1999 년 2 월 26 일). P3은 가장 생산적인 인텔 프로세서 중 하나이지만 설계 상 P2와 거의 다르지 않지만 주파수가 증가하고 약 70 개의 새로운 명령이 추가됩니다. 1999 년 10 월, 모바일 컴퓨터 용 버전도 출시되었으며, 400 ~ 733 MHz의 주파수를 갖는 0.18 미크론 기술을 사용하여 구현되었습니다. 워크 스테이션과 서버의 경우, RH Heon이 있으며 GX 시스템 논리에 중점을두고 두 번째 레벨 캐시 크기는 512KB, 1 또는 2MB입니다. 기술적 인 과정은 0.25 미크론, 시스템 버스는 100 MHz의 주파수에서 작동하며 버스 주파수가 133 MHz 인 0.18 미크론 버전과 600, 666 및 733 MHz 모델이 있습니다.
(Willamette, 2000; Northwood, 2002). 당연히 PIII의 아키텍처가 조만간 구식이되어야합니다. 사실, 1GHz 주파수에 도달 한 인텔은 프로세서의 빈도를 더 높이는 데 어려움을 겪었습니다. 1.13GHz의 펜티엄 III는 불안정성 때문에 철수해야했습니다. 기존 프로세서의 빈도를 늘리면 성능이 조금씩 향상됩니다. 문제는 P6에서 특정 프로세서 노드에 액세스 할 때 발생하는 지연 (지연)이 이미 너무 큰 것입니다.
따라서 Intel NetBurst 아키텍처라는 아키텍처를 기반으로하는 Pentium IV가 나타났습니다. 인텔은이 제목을 통해 빠르게 발전하는 인터넷 및 멀티미디어 기술과 직접 관련이있는 스트림 처리 작업의 실행 속도를 높이는 것이 새 프로세서의 주요 목표임을 강조했습니다.
NetBurst의 아키텍처는 펜티엄 IV 제품군의 프로세서에 속도와 미래의 확장 성을 제공하는 궁극적 인 목표를 달성하기위한 복잡한 여러 혁신을 기반으로합니다. 주요 기술은 다음과 같습니다.
- 하이퍼 파이프 라인 기술 - 펜티엄 IV의 파이프 라인은 20 단계를 포함합니다.
- 고급 동적 실행 - 전환 순서 변경 (명령 실행 불능)으로 전환 및 명령 실행 예측 향상.
- 추적 캐시 - 특수 캐시는 Pentium IV에서 디코딩 된 명령을 캐시하는 데 사용됩니다.
- 신속한 실행 엔진 - Pentium IV 프로세서 ALU는 프로세서 자체 속도의 두 배로 실행됩니다.
- SSE2 - 스트리밍 데이터를 처리하기위한 확장 명령 세트.
- 400 MHz 시스템 버스 - 새로운 시스템 버스.
펜티엄 IV 프레스콧 (2004 년 2 월). 2004 년 2 월 초 인텔은 프레스콧 코어 기반의 새로운 펜티엄 4 프로세서 4 종 (2.8, 3.0, 3.2 및 3.4 GHz)을 발표했다. 인텔은 4 개의 새로운 프로세서가 출시됨에 따라 Northwood 코어를 기반으로 2MB의 L3 캐시를 갖춘 Pentium IV 3.4 EE 프로세서 (Extreme Edition)와 제한된 버스 주파수를 사용하는 Prescott 코어 기반의 Pentium IV 2.8 A 버전을 간소화했습니다 533 MHz).
새로운 프로세서는 Northwood 코어를 기반으로 한 디자인과 동일한 디자인을 갖기 때문에 인텔은 프로세서 이름에 새로운 인덱스를 도입했습니다. 예를 들어, Pentium IV 3.2 C 프로세서는 Northwood 코어를 기반으로하며 800 MHz 버스 및 NT 기술을 지원하며, Pentium IV 3.2 E는 Prescott 코어를 기반으로하며 800 MHz 버스 및 NT 기술을 지원합니다.
Prescott은 90nm 기술을 사용하여 제작되었으므로 크리스탈 자체의 면적을 줄일 수 있었고 총 트랜지스터 수는 2 배 이상 증가했습니다. Northwood 코어의 면적은 145 mm2이고 트랜지스터는 5,500 만 개가 포함되어 있지만 Prescott 코어는 122 mm2의 면적을 가지며 1 억 2 천 5 백만개의 트랜지스터를 포함합니다.
Cyrix 프로세서
1995 년 10 월에 공개 된 6x86  시장에 진출하고 IBM 마이크로 일렉트로닉스 사업부와의 협력을 달성 한 최초의 펜티엄 호환 프로세서. Cyrix가 가격을 너무 높게 책정했기 때문에 6x86의 채택은 초기에 느 렸습니다. 프로세서의 효율성이 인텔과 비슷했기 때문에 가격이 같을 수 있다고 생각했습니다. 사이릭스 (Cyrix)가 포지션을 수정하자마자, 칩은 펜티엄 시리즈에 대한 매우 효율적인 대안으로 관련 시장 분야에서 상당한 영향력을 갖기 시작했다.
시장에 진출하고 IBM 마이크로 일렉트로닉스 사업부와의 협력을 달성 한 최초의 펜티엄 호환 프로세서. Cyrix가 가격을 너무 높게 책정했기 때문에 6x86의 채택은 초기에 느 렸습니다. 프로세서의 효율성이 인텔과 비슷했기 때문에 가격이 같을 수 있다고 생각했습니다. 사이릭스 (Cyrix)가 포지션을 수정하자마자, 칩은 펜티엄 시리즈에 대한 매우 효율적인 대안으로 관련 시장 분야에서 상당한 영향력을 갖기 시작했다.
Cyrix 프로세서는 6x86부터 Pentium 칩과 동일한 성능 수준 이었지만 주파수는 더 낮습니다. 성능 평가를 위해 프로세서 성능 등급이 사용됩니다. P 등급 (예 : Р100 +이라는 기호는 주파수가 100MHz 인 Pentium과 동일한 성능을 나타냅니다). Cyrix 프로세서 (AMD와 같은)는 전통적으로 성능 저하가 거의없이 P 등급의 수치보다 낮은 주파수에서 작동합니다. 예를 들어, Р133 + (Р-rating)은 110MHz에서 작동하고, Р150 + 및 Р166 +는 각각 120 및 133MHz에서 작동합니다.
6x86의 우수성은 6x86이 내부 캐시 및 레지스터를 단일 주파수 사이클 (Pentium은 일반적으로 캐시에 액세스하기 위해 두 개 이상의 사이클을 사용함)로 액세스 할 수있게 해주는 칩 아키텍처의 개선에서 비롯되었습니다. 또한 명령과 데이터를위한 두 개의 별도 8KB 섹션을 포함하는 대신 6x86 기본 캐시가 병합되었습니다. 이 결합 된 모델은 어떤 점에서든 명령과 데이터를 저장할 수 있었으며 캐시의 가능성은 90 % 이내였습니다. CPU에는 원래 5 개의 0.5 미크론 레이어 기술을 사용하여 제조 된 350 만 개의 트랜지스터가 포함되어 있습니다. 인터페이스 - 소켓 7. 코어 전원 공급 장치 - 3.3 V. 특성 6x86은 펜티엄과 유사합니다. 그러나 데이터 종속성 제거, 전환 예측, 자연 순서를 벗어나는 명령 실행 (프로그램 실행 프로세스를 방해하지 않으면 서 빠른 명령이 파이프 라인 큐를 떠날 수있는 가능성) 등의 새로운 기능도 포함됩니다. 이 모든 것은 같은 주파수를 가진 펜티엄과 달리 6x86의 성능을 향상시킵니다.
그러나 6x86 프로세서는 부동 소수점으로 작업 할 때 과열 및 Windows NT와의 비 호환성으로 인해 많은 문제에 직면했습니다. 이것은 프로세서의 성공에 부정적인 영향을 주었고, 펜티엄과의 경쟁은 일시적이었고 인텔 펜티엄 MMX 출시와 함께 끝났다.
Cyrix MediaGX. 1997 년 2 월에 MediaGX 프로세서가 도입됨에 따라 10 년 만에 처음으로 PC 아키텍처가 확인되었고 저렴한 "기본 PC"인 새로운 시장이 발견되었습니다. 이 시장의 성장은 호황을 누리고 Cyrix 프로세서 기술과 시스템 수준의 혁신이 핵심 요소였습니다.
중앙 처리 장치 PC에서 직접 처리되는 프로세스가 많을수록 전체 시스템 성능이 높아집니다. 전통적인 컴퓨터 개발에서 중앙 프로세서는 메가 헤르쯔의 주파수로 데이터를 처리하지만, 다른 구성 요소로 데이터를 이동하는 버스는 다른 구성 요소와 반 속도로만 작동합니다. 즉, 중앙 처리 장치 (및 중앙 처리 장치) 로의 데이터 이동에는 더 많은 시간이 소요됩니다. Cyrix는 MediaGX 기술 도입으로 이러한 병목 현상을 제거했습니다. MediaGX 아키텍처는 그래픽 및 사운드 기능, PCI 인터페이스 및 메모리 관리자를 프로세서 유닛에 통합함으로써 잠재적 인 시스템 충돌 및 최종 사용자 구성 문제를 제거합니다. MediaGX 프로세서와 MediaGX Cx5510 코 프로세서의 두 칩으로 구성됩니다. 프로세서는 특수 설계된 마더 보드가 필요한 특수 소켓을 사용합니다. MediaGX는 전용 64 비트 데이터 버스를 통해 PCI 버스와 EDO DRAM 메모리를 직접 연결하는 x86 호환 프로세서입니다. Cyrix는 데이터 버스에 사용 된 압축 기술이 두 번째 수준의 캐시가 필요 없다고 주장합니다. 중앙 프로세서에는 기본 펜티엄 칩과 동일한 볼륨 (16KB) 캐시가 있습니다. 그래픽은 중앙 프로세서 자체의 특수 파이프 라인에 의해 처리되며 모니터 컨트롤러는 주 프로세서에도 위치합니다. 자체 메모리 (Cyrix Display Compression Technology) (DCT)를 사용하는 대신 메인 메모리 (전통적인 UMA (Unified Memory Architecture))에 비디오 메모리, 프레임 버퍼가 저장되어 있지 않습니다. VGA 데이터 작업은 컴퓨터 하드웨어에 의해 수행되지만 VGA 레지스터는 Cyrix 프로그램 인 VSA (Virtual System Architecture)로 제어됩니다. 함께 제공되는 MediaGX Cx5510 칩에는 오디오 컨트롤러가 포함되어 있으며 VSA 프로그램을 사용하여 표준 사운드 카드의 기능을 에뮬레이션합니다. 이 칩은 PCI 버스를 통해 MediaGX 프로세서를 ISA 버스뿐만 아니라 IDE 및 I / O 포트에 연결합니다. 즉, 칩셋의 전통적인 기능을 수행합니다.
Cyrix의 Intel MMX 기술에 대한 대답은 National Semiconductor가 인수하기 직전 인 1997 년 중반에 출시 된 6x86MX였습니다. 이 회사는 시스템 제조업체와 궁극적으로 소비자의 비용을 적절한 수준으로 유지하면서 기존 칩 및 마더 보드의 수명을 연장하는 새로운 칩을위한 소켓 7 형식에 충실했습니다.
새로운 칩의 아키텍처는 MMX 명령 추가, 부동 소수점 유닛의 개선, 대형 (64KB) 범용 1 차 레벨 캐시 및 확장 메모리 관리 장치를 통해 전임자의 아키텍처와 본질적으로 동일하게 유지되었습니다.
6x86MX 프로세서는 6x86MX / PR233 (187MHz에서 작동)이 Pentium II (233MHz) 및 AMD Kb보다 빠르기 때문에 시장에서 호평을 받았습니다. 또한 MX는 외부 75 MHz 버스에서 실행 가능한 최초의 프로세서 였으므로 명백한 대역폭 이점과 향상된 전체 성능을 제공합니다. 그러나 6x86MX는 경쟁사보다 훨씬 더 나쁜 부동 소수점을 사용하여 3 차원 그래픽 처리에 나쁜 영향을 미쳤습니다.
Cyrix MII. 프로세서 MII - 높은 주파수에서 작동하는 6h86MH 개발. 1998 년 여름까지 0.25 마이크론 MII-300 및 MII-333 프로세서는 내셔널 세미 컨덕터 회사의 새로운 생산 설비에서 제조되었습니다. 메인, 기술의 개발을 목표로 0.22 미크론, 궁극적 인 목표로 이동 - 0.18 미크론 1999 년
AMD 프로세서
오랜 시간 Advanced Micro Devices,  cyrix와 마찬가지로 Intel의 개발을 기반으로 한 286, 386 및 486 CPU를 제조했습니다. K5는 AMD가 높은 기대를 걸고 처음으로 독립적으로 만든 x86 프로세서였습니다. 그러나 AMD가 1996 년 봄에 캘리포니아에 본사를 둔 라이벌을 인수 한 것은 인텔에 대한 다음 공격에 대비할 수있는 기회를 창출 한 것으로 보인다. K6는 NextGen을 인수 한 후 Nx686으로 개명되었습니다. 일련의 MMX 호환 KB 프로세서는 Cyrix 6x86MX보다 몇 주 전에 1997 년 중반에 출시되어 비평가의 승인을 받았습니다.
cyrix와 마찬가지로 Intel의 개발을 기반으로 한 286, 386 및 486 CPU를 제조했습니다. K5는 AMD가 높은 기대를 걸고 처음으로 독립적으로 만든 x86 프로세서였습니다. 그러나 AMD가 1996 년 봄에 캘리포니아에 본사를 둔 라이벌을 인수 한 것은 인텔에 대한 다음 공격에 대비할 수있는 기회를 창출 한 것으로 보인다. K6는 NextGen을 인수 한 후 Nx686으로 개명되었습니다. 일련의 MMX 호환 KB 프로세서는 Cyrix 6x86MX보다 몇 주 전에 1997 년 중반에 출시되어 비평가의 승인을 받았습니다.
K6는 펜티엄 프로보다 거의 20 % 적 었으며 동시에 330 만개의 트랜지스터가 더 많이 포함되었습니다 (8.8 대 550 만). K6 CPU는 멀티미디어 소프트웨어 개발을 위해 설계된 57 개의 새로운 x86 팀을 포함하여 인텔의 MMX 기술을 지원했습니다. K6의 성능 레벨은 해당 주파수의 Pentium Pro와 매우 유사하며 두 번째 레벨에서 최대 512KB 캐시를가집니다. 부동 소수점으로 작업하는 Cyrix MX 칩 (일반적으로 다소 적지 만)은 펜티엄 프로 또는 펜티엄 II에 비해 상대적인 약점이있었습니다.
AMD K6-2. 930 만개의 트랜지스터를 가진 AMD K6-2 프로세서는 0.25 미크론 AMD 기술을 사용하여 제조되었습니다. 이 프로세서는 100MHz Super7 호환 321 핀 세라믹 보드 (세라믹 핀 어레이 어레이 (CPGA) 패키지)로 패키징되었습니다. K6-2는 혁신적이고 효율적인 R1SC86 마이크로 아키텍처, 대형 (64KB) 1 차 레벨 캐시 (32KB 이중 데이터 데이터 캐시, 추가 20KB 프리 코딩 캐시가있는 32KB 명령어 캐시) 및 개선 된 부동 소수점 모듈을 포함합니다.
1998 년 중반에 출시 된 효과적인 성능은 300MHz로 추산되었는데, 1999 년 초 가장 빠른 프로세서는 450MHz였습니다. K6-2의 3 차원 기능은 또 다른 중요한 업적을 나타냅니다. 3D 기술은 3D 기술을 사용하여 3D 기술을 가속화하는 KB 아키텍처에 이미 포함되어있는 표준 MMX 명령을 보완 한 새로운 21 개 팀으로 구성되었습니다. 2001 년 초에 발표 된 K6-2 프로세서 (550MHz)는 유망한 시장 부문의 데스크탑 컴퓨터에서 Duron 프로세서로 대체 된 오래된 소켓 7 폼 팩터를위한 가장 빠르고 가장 최종적인 AMD 프로세서였습니다.
AMD K6-III. AMD는 1999 년 2 월에 코드 명 narptooth 인 400MHz AMD K6-III 프로세서를 출시하고 450MHz 버전을 테스트했다. 이 새로운 프로세서의 핵심 기능은 혁신적인 개발 - 3 단계 캐시였습니다.
전통적으로 PC 프로세서는 두 가지 캐시 레벨을 사용했습니다.
- 칩 상에 일반적으로 위치하는 제 1 레벨 (L1)의 캐시;
- 두 번째 레벨 캐시 (L2)는 CPU 외부, 마더 보드 또는 슬롯 또는 CPU 칩에 직접 위치 할 수 있습니다.
캐시 하위 시스템을 설계 할 때는 일반적으로 캐시가 클수록 성능이 뛰어납니다 (CPU 코어가 명령과 데이터에 빠르게 액세스 할 수 있음).
AMD의 "Three-Tier Cache"는 PC 성능을 점점 더 요구하는 애플리케이션의 요구를 충족시키기 위해 크고 빠른 캐시의 이점을 인식하여 Super7 플랫폼을 기반으로 PC 성능을 향상 시키도록 설계된 아키텍처 캐시 혁신을 도입했습니다.
- 전체 AMD-K6 프로세서 제품군의 표준이었던 AMD-K6-III 프로세서 및 보완 적 L1 캐시 (64KB)의 최고 속도로 실행되는 내부 K2 캐시 (256KB)
- 멀티 포트 내부 캐시는 L1 및 L2 캐시 모두에 동시 64 비트 읽기 및 쓰기를 허용합니다.
- 기본 프로세서 버스 (100 MHz)로, 512에서 2048 KB까지 확장 가능한 마더 보드의 상주 캐시 메모리에 대한 연결을 제공합니다.
AMD-K6-III 다중 포트 내부 캐시 프로젝트는 L1 캐시 (64 Kbytes)와 L2 캐시 (256 Kbytes)가 프로세서 클럭 사이클 당 동시에 64 비트 읽기 및 쓰기 작업을 수행 할 수있게했습니다. 이 멀티 포트 캐시 프로젝트 외에도 AMD-K6-III 프로세서 코어는 L1 캐시와 L2 캐시를 동시에 액세스 할 수 있었기 때문에 CPU의 전체 처리량이 증가했습니다.
AMD는 완전히 조정 된 3 단계 캐시를 사용하여 K6-III가 Pentium III에 비해 435 %의 캐시 우위를 가지므로 상당한 성능 이점이 있다고 주장했습니다. 그러나 그는 궁극적으로 데스크톱 컴퓨터 분야에서 상대적으로 짧은 수명을 유지할 예정이었으며 몇 달 만에보다 효율적인 AMD Athlon 프로세서에 열중하여 일했습니다.
1999 년 여름에 애슬론 프로세서를 출시 한 것이 AMD의 가장 성공적인 움직임이었다. 이것은 그들이 그들이 생산 한 것을 자랑스럽게 여겼다.  일곱 번째 세대의 첫 번째 프로세서 (그는 차세대 프로세서의 이름을 얻기 위해 Pentium II / III 및 K6-III와 급진적 인 아키텍처 차이가 많았 음) 또한 인텔의 기술 리더십을 뺏어갔습니다.
일곱 번째 세대의 첫 번째 프로세서 (그는 차세대 프로세서의 이름을 얻기 위해 Pentium II / III 및 K6-III와 급진적 인 아키텍처 차이가 많았 음) 또한 인텔의 기술 리더십을 뺏어갔습니다.
고대 그리스 단어 Athlon은 "트로피"또는 "게임"을 의미합니다. Athlon은 AMD가 소비자 시장 및 3D 게임 시장에서 전통적으로 얻은 장점 외에도 기업 부문에서 진정한 경쟁력을 확보하기를 원했던 프로세서입니다. 코어는 102mm2의 크리스털에 위치하고 약 2200 만 개의 트랜지스터를 포함합니다.
듀론. 2000 년 중반에 가정과 사무실 용으로 설계된 Duron 프로세서가 출시되었습니다. 이름은 라틴어 "durare"- "영원한", "긴"에서 온다. L1 캐시 (128KB) 및 L2 (64KB)는 보드에 있습니다. 기본 시스템 버스는 200MHz에서 실행됩니다. 개선 된 기술로 지원되는 3DNow! 기술 0.18 미크론, 주파수 600, 650 및 700 MHz. 인터페이스 - 462 핀 소켓 A.
애슬론 64 2003 년 가을 2 명이 나왔습니다.  AMD 프로세서 모델 - 주류 시장은 Athlon 64, 멀티미디어 및 전문 애플리케이션 (K8 아키텍처)은 Athlon 64 FX-51. 표기법에서 AMD Athlon 64는 3200+의 등가 주파수를 가지며 물리적 주파수는 2GHz이며 FX-51은 2.2GHz보다 약간 더 높습니다. 중요한 아키텍처 혁신은 시스템 메모리 컨트롤러 (시스템 메모리 컨트롤러 허브 -MCH)를 프로세서에 직접 통합하는 것입니다. 즉, 마더 보드 (더 정확하게는 칩셋)에는 더 이상 별도의 노스 브리지 컨트롤러 칩이 포함되어서는 안됩니다. 또한 도입 된 모든 지연과 함께 주 시스템 버스 (FSB)가 필요하지 않습니다. 대신 K8은 Southbridge, AGP 또는 다른 CPU에 연결하기 위해 HyperTransport (시스템 버스 대역폭 최대 6.4GB / s)를 사용합니다. 이를 통해 메모리는 전체 프로세서 주파수에서 작동 할 수 있으며 대기 시간 (대기 시간)을 줄이고 메모리 효율성을 향상시킵니다. 이 프로세서는 32 비트 및 64 비트 애플리케이션에 모두 적용됩니다.
AMD 프로세서 모델 - 주류 시장은 Athlon 64, 멀티미디어 및 전문 애플리케이션 (K8 아키텍처)은 Athlon 64 FX-51. 표기법에서 AMD Athlon 64는 3200+의 등가 주파수를 가지며 물리적 주파수는 2GHz이며 FX-51은 2.2GHz보다 약간 더 높습니다. 중요한 아키텍처 혁신은 시스템 메모리 컨트롤러 (시스템 메모리 컨트롤러 허브 -MCH)를 프로세서에 직접 통합하는 것입니다. 즉, 마더 보드 (더 정확하게는 칩셋)에는 더 이상 별도의 노스 브리지 컨트롤러 칩이 포함되어서는 안됩니다. 또한 도입 된 모든 지연과 함께 주 시스템 버스 (FSB)가 필요하지 않습니다. 대신 K8은 Southbridge, AGP 또는 다른 CPU에 연결하기 위해 HyperTransport (시스템 버스 대역폭 최대 6.4GB / s)를 사용합니다. 이를 통해 메모리는 전체 프로세서 주파수에서 작동 할 수 있으며 대기 시간 (대기 시간)을 줄이고 메모리 효율성을 향상시킵니다. 이 프로세서는 32 비트 및 64 비트 애플리케이션에 모두 적용됩니다.
동시에 AMD는 Athlon 64를 발표하면서 AMD Athlon 64 (PC) 및 AMD Opteron 프로세서에서 자연스럽게 작동 할 수있는 64 비트 프로세서 용 Windows XP 64-Bit Edition의 베타 버전을 발표했습니다 워크 스테이션).
가격표 작업
마이크로 프로세서를 선택할 때 몇 가지 특성을 고려해야합니다. 예를 들어
- 인텔 프로세서.
- AMD 및 Cyrix 프로세서.
- Intel 및 AMD 프로세서의 최신 버전 (이전 버전과 달리).
- 마이크로 프로세서의 대체 제조업체.
- 가격 목록에서 구성 요소 특성화
- AMD ATHLON-64 X2 6000+ BOX (ADV6000) 1Mb / 2000MHz 소켓 AM2
- AMD ATHLON-64 2800+ (ADA2800) 512K / 800MHz 소켓 -754
- Intel Core 2 Duo E6550 2.33GHz / 4MB / 1333MHz 775-LGA
- Intel Pentium 4 1.5GHz / 256K / 400MHz 423-PGA
프로세서는 다음 기능을 수행합니다.
1) 명령 및 피연산자의 주소를 계산하는 단계;
2) RAM으로부터의 명령의 선택 및 디코딩;
3) RAM, 마이크로 프로세서 메모리 및 외부 장치 어댑터의 레지스터로부터의 데이터 선택;
4) 외부 장치로부터 요청 및 명령을 수신 및 처리하는 것;
5) 데이터 처리 및 RAM, 마이크로 프로세서 레지스터 및 외부 장치 어댑터 레지스터에 쓰기;
6) 컴퓨터의 다른 모든 유닛 및 유닛에 대한 제어 신호의 개발
7) 다음 팀으로 가라.
/ 4 /에 따르면 마이크로 프로세서의 주요 매개 변수는 다음과 같습니다. 비트 깊이, 작동 클럭 주파수, 캐시 크기, 명령 구성, 건설적인.
1) 내부 레지스터의 자릿수 - 프로세서가 한 단계에서 처리 할 수있는 비트 수입니다. 데이터 버스 폭 동시에 작업을 수행 할 수있는 비트 수를 결정합니다. 어드레스 버스 폭 프로세서가 작동 할 수있는 메모리 (주소 공간)의 양을 결정합니다. 주소 공간 - 이것은 마이크로 프로세서가 직접 지정할 수있는 최대 메모리 셀 수입니다.
2) 작동 클록 주파수 (MHz) 각 명령이 특정 수의 사이클 동안 실행되기 때문에 대부분 프로세서의 속도를 결정합니다. 시스템 클록주기가 짧을수록 프로세서 성능이 향상됩니다. 컴퓨터 속도는 프로세서가 작동하는 마더 보드의 버스 클록 주파수에 따라 달라집니다.
3) 캐시 메모리마이크로 프로세서 보드에 설치된 두 가지 레벨 :
3.1) L 1 - 프로세서의 주 칩 (코어) 내부에 위치하며 항상 전체 프로세서 주파수 (Intel 386SLC 및 486 마이크로 프로세서에 처음 등장)에서 실행되는 첫 번째 레벨의 메모리.
3.2) L 2 - 두 번째 레벨의 메모리, 마이크로 프로세서 보드에 놓여 있고 내부 버스에 의해 코어에 연결된 칩 (펜티엄 II 마이크로 프로세서에서 처음 도입 된). 이 메모리는 전체 또는 절반 프로세서 주파수에서 작동 할 수 있습니다.
4) 지침 구성 - 마이크로 프로세서에 의해 자동으로 실행되는 명령의 목록, 유형 및 유형. 데이터 및 이러한 프로 시저를 수행 할 수있는 데이터 범주에서 수행 할 수있는 프로 시저를 직접 정의합니다. 명령 구성의 중요한 변화는 마이크로 프로세서 인 Intel 80386 (이 구성이 기본으로 사용됨), Pentium MMX, Pentium III, Pentium 4에서 발생했습니다.
5) 건설적인 마이크로 프로세서가 설치된 실제 플러그 - 인 연결을 의미합니다. 다른 커넥터는 서로 다른 디자인 (슬롯 커넥터 - 슬롯, 소켓 커넥터 - Soket)을 가지며 다른 수의 접점을가집니다.
프로세서는 다양한 기준에 따라 분류됩니다. / 4, 13 /에 따라 다음 주요 특징을 구별 할 수 있습니다.
1) 목적 마이크로 프로세서는 보편적 인 및 전문화 된. 첫 번째는 광범위한 작업을 해결하기 위해 설계되었으며 알고리즘의 보편성은 명령 시스템에 배치됩니다. 따라서 프로세서 성능은 해결할 작업의 세부 사항에 약하게 의존합니다. 특수화 된 프로세서는 특정 범위의 작업 또는 단일 태스크를 해결하도록 설계되었으며 제한된 명령 집합을 가지고 있습니다. 그들 중에 서다. 데이터 프로세서, 수학 프로세서 및 마이크로 컨트롤러.
2) 실행중인 프로그램의 수 프로세서는 단일 프로그램 (다음 프로그램의 실행으로의 전환은 현재 프로그램이 완료된 후에 만 발생한다) 다중 프로그램 (여러 프로그램이 동시에 실행되고 있음).
3) 구조의 마이크로 프로세서는 구별된다. 고정 비트 (엄격하게 특정 디지트 용량 보유) 및 마이크로 프로세서 증분 비트 깊이 포함 (섹션에서 자릿수를 늘릴 수 있음).
4) 마이크로 프로세서 세트 내의 LSI (VLSI)의 수 강조 표시 할 수있다. 단일 칩, 멀티 칩 및 멀티 칩 섹션 프로세서. 첫 번째 경우, 모든 프로세서 하드웨어 구성 요소는 하나의 LSI (VLSI)로 구현됩니다. 그러한 프로세서의 기능은 크리스탈 및 케이스의 리소스에 의해 제한됩니다. 멀티 칩 프로세서는 프로세서의 논리적 구조를 LSI 또는 VLSI의 형태로 구현되는 기능적으로 완벽한 부품으로 분할 한 결과입니다. 후자의 경우, 프로세서의 논리적 구조의 기능적으로 완전한 부분은 LSI로 구현되는 섹션으로 나뉩니다.
5) By 처리 된 정보의 자릿수 마이크로 프로세서는 4, 8, 12, 16, 24, 32 및 64 비트가 될 수 있습니다. 실제로는 32 비트 프로세서가 가장 일반적입니다. 64 비트 프로세서가 점차 보편화되고 있습니다.
6) 유형별 제조 기술 LSI (VLSI) 마이크로 프로세서는 크게 두 가지 그룹으로 나뉘어집니다 : LSI에 내장 된 프로세서, 유니 폴라 기술, BIS 기반 프로세서, 양극 기술. 첫 번째 그룹의 대표자들 : 피채널피-MOP), n채널n-MOP), 상보 형 (CMOS) BIS. (MOS- 금속 - 산화물 - 도체). 두 번째 그룹에는 LSI 기반 트랜지스터 - 트랜지스터 로직 (TTL), 에미 터 - 커플 링 로직 (ECL) 및 통합 분사 로직 (AND 2 L). LSI 제조 기술의 유형은 칩 집적도, 속도, 전력 소비, 잡음 내성 및 프로세서 비용을 결정합니다. 이러한 특징의 복합체에 따르면 레이아웃의 고밀도, 고속 및 상대적으로 낮은 비용을 보장하는 n-MOS 및 CMOS 기술을 사용하여 만들어진 마이크로 프로세서를 선호 할 수 있습니다. ECL은 가장 빠른 프로세서 성능을 제공하지만 낮은 레이아웃 밀도와 높은 전력 소모를 제공합니다. 기술 및 2 L은 마이크로 프로세서의 평균 특성을 나타냅니다.
7) 문자 명령 시스템 방출하다 전체 명령어 프로세서또는 CISC가공업자 (복합 명령 세트 명령), 약식 프로세서 또는 RISC가공업자 (사형 집행 명령 감소), 슈퍼 큰 명령 단어와 프로세서 또는 브리가공업자(매우 긴 명령 단어). CISC 프로세서는 문제를 해결하기 위해 효과적인 알고리즘을 사용할 수 있지만 동시에 프로세서 회로를 복잡하게 만들고 일반적으로 최대 성능을 제공하지 못하는 다중 포맷 명령 세트가 많습니다. CISC의 아키텍처는 고전적인 프로세서에 내재되어 있습니다. RISC 프로세서에는 프로그램 지침에서 자주 볼 수있는 단순한 세트가 포함되어 있습니다. 마이크로 프로세서에서 더 복잡한 명령을 실행해야하는 경우 간단한 명령으로 자동으로 어셈블됩니다. 모든 간단한 명령은 동일한 크기를 가지며 하나의 기계주기가 실행에 소비됩니다 (CISC 시스템에서 가장 짧은 명령을 실행하는 데 보통 4주기가 소요됩니다). 최신 64 비트 RISC 프로세서는 Apple (PowerPC), IBM (PPC) 등 많은 회사에서 제조합니다. VLIW 프로세서에서 하나의 명령은 병렬로 실행되어야하는 몇 가지 연산을 포함합니다. 프로세서의 여러 컴퓨팅 장치간에 작업을 분산시키는 작업은 프로그램을 컴파일 할 때 해결됩니다. 이러한 접근 방식을 통해 프로세서 및 전력 소비의 크기를 줄일 수있었습니다. VLIW 프로세서의 예로는 Intel의 Itanium, Hewlett-Packard의 McKinley 등이 있습니다.
8) By 내부 레지스터 사용 수와 방법 구별하다 충전식, 다중 누적 기 및 쌓다 프로세서. 배터리 프로세서 - 하나의 결과 레지스터가있는 프로세서입니다. 이들의 특징은 하드웨어 구현의 상대적 단순성뿐 아니라 간소화 된 명령 형식 (다음 강의에서 논의 할 것입니다.)입니다. 명령에서 배터리의 피연산자 주소는 지정되지 않지만 두 번째 피연산자 만 처리됩니다. 이러한 프로세서의 단점은 연산을 수행하기 전에 피연산자를 배터리에 미리로드하고 명령 실행 결과를 임의의 메모리 셀 또는 레지스터에 직접 쓸 수 없다는 점입니다. 있음 다중 배터리레지스터는 현대 프로세서의 대다수이며, 결과 레지스터의 기능은 범용 레지스터 또는 메모리 셀을 수행 할 수 있습니다. 명령에서 두 피연산자는 명시 적으로 지정되며 연산 결과는 대부분 피연산자 중 하나의 자리에 배치됩니다. 있음 쌓을 수있는 프로세서는 대개 메모리에 대형 하드웨어 스택과 추가 외부 스택을 사용합니다 (하드웨어가 부족함). 스택에 피연산자를 특수하게 배치하므로 주소 지정되지 않은 명령어로 정보 처리를 수행 할 수 있으므로 프로세서 성능이 향상되고 메모리가 절약됩니다. 이러한 명령은 스택에서 하나 또는 두 개의 피연산자를 추출하고 해당 연산 또는 논리 연산을 수행 한 다음 그 결과를 스택의 맨 위에 놓습니다. 단점은 주소 명령을 사용하여 데이터를 사전 준비해야한다는 것입니다.
프로세서 개발의 역사와 그 비교 특성은 / 4, 13 /에 자세히 나와 있습니다. 다음으로, 우리는 프로세서의 물리적 및 기능적 구조를 고려합니다.
CPU의 물리적 기능적 구성 (예 : CPU 인텔 8086). 쉬.
프로세서의 물리적 구조는 상당히 복잡합니다. / 4 /에 따라 프로세서 코어에는 주 제어 및 실행 모듈 (정수 데이터에 대한 연산을 수행하는 블록)이 포함됩니다. 로컬 제어 회로에는 부동 소수점이있는 블록, 분기 예측 모듈, 마이크로 프로세서 메모리 레지스터, 1 차 레벨의 캐시 레지스터, 버스 인터페이스 등이 포함됩니다.
참고 : 논리적 코어는 프로세서를 구성하는 체계입니다. 물리적으로, 코어는 회로 다이어그램이 로직 요소를 사용하여 구현되는 크리스탈입니다.
가장 일반적인 경우, 프로세서의 기능적 구조는 두 부분으로 구성된 하나의 소스 / 4, 5 /에 따라 컴포지션으로 표현 될 수 있습니다. 조작 장치 (OU) 및 버스 인터페이스 (시), 다른 사람에 따르면 / 2 /, - 3 블록 : 조작부 (회사 소개), 제어 장치 (Ub) 및 인터페이스 유닛 (IB). 블록의 수와 이름에 약간의 불일치가 있어도 프로세서 구성 요소의 수와 작동 원리를 위반하지 않습니다. 따라서 소스 / 4 /에서 첫 번째 (더 시각적 인) 버전을 고려합니다.
단순화 된 일반적인 프로세서 구조가 그림 4.1에 나와 있습니다.
OU 제어 유닛 (CU), 산술 논리 장치 (ALU), 플래그 레지스터, 범용 레지스터 (RON), 레지스터 포인터, 인덱스 레지스터를 포함합니다. 시 어드레스 레지스터, 명령의 레지스터 블록 (버퍼), 어드레스 생성 노드, 버스 및 포트 제어 회로를 포함한다. 마이크로 프로세서의 두 부분은 병렬로 동작하며 IC는 op 앰프보다 빠르다. 이 프로세서 유닛을보다 자세히 고려하십시오.
시이것은 마이크로 프로세서와 컴퓨터 시스템 버스의 통신 및 조정뿐만 아니라, 실행되는 프로그램의 명령의 예비 분석 및 피연산자 및 명령의 전체 주소 생성을 수신하기위한 것입니다.
분절 (주소) 레지스터와 주소 형성 노드 메모리 분할을 구현하십시오. 명령과 데이터는 셀에 저장되며 해당 메모리 위치는 해당 셀의 주소에 의해 결정됩니다. 코드 레벨의 명령과 데이터는 서로 구별 할 수 없으므로 명령과 데이터를 구분하기 위해 서로 다른 메모리 영역 (세그먼트)에 배치됩니다. 세그먼트 - 이것은 시작 주소와 길이로 특징 지어지는 직사각형의 메모리 영역입니다. 시작 주소 (세그먼트 시작 주소) 세그먼트가 시작되는 메모리 셀의 번호 (주소)입니다. 세그먼트 길이 – 이것은 그 안에있는 메모리 셀의 수입니다. 세그먼트의 길이가 다를 수 있습니다. 세그먼트 내에있는 모든 셀의 번호가 0부터 시작하여 번호가 매겨집니다. 세그먼트 내의 셀 주소 지정은 세그먼트 시작과 관련이 있습니다. 세그먼트의 셀 주소가 호출됩니다. 상쇄 된또는 유효 주소 -EA(세그먼트의 시작 주소를 기준으로 함). 현재 세그먼트는 해당 세그먼트 레지스터를로드하여 지정할 수 있습니다.
1) 연사 (코드 세그먼트) - 프로그램 명령이있는 현재 코드 세그먼트의 시작 부분을 결정합니다. 레지스터 내용을 유효 주소로 사용하여 명령이 선택됩니다. IP (지시 사항 포인터) , 그리고 세그먼트의 주소로 - CS의 내용. 현재 프로그램 명령의 주소 오프셋을 저장하는 것은 IP 레지스터입니다.
2) DS (데이터 세그먼트) - 현재 데이터 세그먼트의 시작 부분을 정의합니다. 데이터에 대한 참조 (일부 예외가 있음)는이 레지스터의 내용과 관련하여 작성됩니다.
3) SS (스택 세그먼트) - 현재 스택 세그먼트의 시작을 결정합니다. 일반적으로 스택과 관련된 데이터의 모든 주소는이 레지스터의 내용과 관련이 있습니다.
4) ES (확장 세그먼트) - 일반적으로 보조 데이터 세그먼트 (세그먼트 간 전송의 경우)로 간주되는 추가 현재 세그먼트의 시작을 정의합니다.
노드 형성 주소 및 명령 레지스터 기능적으로 SU의 일부이며 위에 논의되었다.
입력 / 출력 장치 (I / V) 세그먼트 레지스터 주소 지정을 사용하지 않을 때. 프로세서는 특별한 주소 공간 (포트)을 통해 상호 작용합니다. 각 포트에는 연결된 포트 번호에 해당하는 번호가 있습니다. 장치 포트는 인터페이스 장비와 데이터 교환 및 제어 정보를위한 두 개의 레지스터에 해당합니다. 버스 및 포트 제어 체계 다음 기능을 수행합니다.
1) 그것에 대한 포트 주소 및 제어 정보의 형성;
2) 포트로부터 제어 정보, 포트의 준비 상태 및 그 상태에 관한 정보를 수신하는 단계;
3) 에어 블래스트 포트와 프로세서 간의 데이터 전송을위한 시스템 인터페이스의 엔드 투 엔드 채널 구성
버스 및 포트 제어 체계는 주소 버스, 데이터 버스 및 명령 버스와 같은 포트와 통신하기 위해 시스템 버스를 사용합니다.
CPU의 물리적 기능적 구성 (예 : Intel 8086 CPU). OU.
일반적으로 OU는 팀이 정의한 작업을 수행하고 실제 주소를 생성합니다.
우 컴퓨터의 모든 장치에 제어 신호를 생성합니다. CU의 일부로 다음과 같은 기능 블록을 구별 할 수 있습니다.
1) 명령 레지스터 - 명령 코드가 저장되는 메모리 레지스터 : 피연산자의 연산 코드 및 주소 (프로세서의 인터페이스 부분에 위치).
2) 디 스크램블러 동작 - 명령의 레지스터로부터 수신 된 연산 코드에 따라 자신이 가지고있는 많은 출력 중 하나를 선택하는 논리 블록.
3) 읽기 전용 메모리 (ROM) 펌웨어 정보 처리 절차를 수행하기위한 제어 펄스를 컴퓨터 유닛에 저장하고; 펄스는 동작의 디코더에 의해 선택된 와이어를 사용하여 펌웨어 ROM으로부터 필요한 제어 신호 시퀀스를 판독하고;
4) 주소 생성 노드 (ShI에 위치 함) - 마이크로 프로세서 메모리 또는 명령 레지스터로부터 수신 된 세부 사항을 사용하여 메모리 셀 (레지스터)의 전체 주소를 계산하는 장치.
5) 코드 버스 데이터 주소 및 명령어 - 프로세서의 내부 인터페이스 버스의 일부.
따라서, CU는 프로세서가 전술 한 기능을 수행하기위한 제어 신호를 생성한다.
그림 4.1 - 단순화 된 일반적인 프로세서 구조
ALU 정보 변환의 산술 및 논리 연산을 수행하도록 설계되었습니다. 기능상 가장 간단한 버전의 ALU는 다음과 같은 구성 요소로 이루어져 있습니다.
1) 가산기 이진 코드의 추가 절차를 수행하고 더블 머신 워드 (32 비트)의 너비를가집니다.
2) 레지스터들 - 다양한 길이의 고속 메모리 셀 : 레지스터 1은 32 비트 폭이고, 레지스터 2는 16 비트입니다. 추가 할 때 첫 번째 항목은 레지스터 1에 배치되고 결과는 두 번째 항목이 레지스터 2에 저장됩니다.
3) 제어 회로 명령의 코드 버스를 통해 제어 유닛으로부터 제어 신호를 수신하고 레지스터 및 가산기의 동작을 제어하기위한 신호로 변환한다.
ALU는 고정 소수점이있는 숫자에 대해서만 산술 연산을 수행합니다. 수치 연산 보조 프로세서 또는 특별히 컴파일 된 프로그램이 부동 소수점 숫자를 처리하는 데 사용됩니다.
SU 및 ALU의 장치 및 작동에 대한 자세한 내용은 / 3-5 /를 참조하십시오.
OU 레지스터 - 마이크로 프로세서 메모리의 일부. 총 14 개의 2 바이트 레지스터를 포함하는 기본 프로세서 Intel 8086의 예제에서 레지스터를 고려하십시오. 현대의 프로세서에는 훨씬 더 많은 숫자가 있습니다. 그러나 14 레지스터 프로세서 메모리는 기본 모델, 특히 어셈블리 언어로 사용됩니다.
OS에는 다음 레지스터가 포함됩니다.
1) 범용 레지스터 (RON) 또는 보편적 인: AX - (AH, AL), BX- (BH, BL), CX- (CH, CL), DX- (DH, DL)은 모든 데이터를 일시적으로 저장하는 데 사용할 수 있지만 각 레지스터마다 전체적으로 작업 할 수 있습니다. 그것의 각 절반으로, 따로 따로 가능하다; 각 RON은 특정 명령을 실행할 때 특별하게 사용할 수도 있습니다.
2) 오프셋 레지스터: SP, BP, SI, DI는 분할 할 수 없으며 세그먼트 내의 메모리 셀의 상대 주소를 저장하기위한 것이다 (세그먼트 시작과 관련된 오프셋).
2.1) SP (스택 포인터) - 스택 맨 윗부분의 이동.
2.2) 혈압 (기지 포인터) - 스택에 직접 할당 된 메모리 필드의 시작 주소의 오프셋.
2.3) SI (출처 색인) , DI (목적지 색인) 이들은 스트링들상의 동작 동안 데이터의 소스 및 목적지 인덱스들의 어드레스 등을 저장하기위한 것이다.
프로세서 상태 워드 (Psw – 프로세서 주 단어) 또는 등록 깃발들 - 2 바이트 크기이며 단일 비트 부호 또는 플래그를 포함합니다. 레지스터에는 9 개의 플래그가 있습니다 : 6 개 조건부의 또는 상태, OS에 의해 수행 된 연산 결과를 반영하고, 나머지 3- 총재, 프로그램의 실행 모드를 결정합니다.
1) 상태 플래그.
1.1) CF (캐리 깃발) - 캐리 플래그. 산술 및 일부 시프트 연산을 수행 할 때 최상위 자릿수에서 "전송"이 발생하면 1로 설정됩니다.
1.2) PF (패리티 플래그) - 패리티 플래그. 결과보다 하위 8 비트 결과를 확인합니다. 짝수 개의 단위를 사용하면이 플래그가 1로 설정되고 홀수는 0으로 설정됩니다.
1.3) AF (보조 캐리 깃발) - 이진 십진법 산법에있는 논리 전송의 깃발. 산술 연산이 단일 바이트 피연산자의 네 번째 오른쪽 비트를 전송하거나 차용하는 경우 1로 설정하십시오. 2 진 10 진수 코드 및 ASCII 코드의 산술 연산에 사용됩니다.
1.4) Zf (제로 깃발) - 0의 플래그. 연산 결과가 0이면 1로 설정되고, 그렇지 않으면 ZF가 재설정됩니다.
1.5) SF (Sign Flag) - 플래그 기호. 산술 연산의 결과가 음수이면 1로 설정하고 결과가 양수이면 0으로 설정합니다.
1.6) ~ 중 (오버플로 깃발) - 플래그 오버플로. 결과가 방전 그리드의 한계를 초과하면 연산 오버플로에서 1로 설정됩니다.
2) 제어 플래그.
2.1) Tf (함정 깃발) - 추적 플래그. 이 플래그의 단일 상태는 프로세서를 단계별 프로그램 실행 모드로 만듭니다.
2.2) IF (인터럽트 플래그) - 인터럽트 플래그. 이 플래그가 0 인 상태에서는 인터럽트가 금지되어 단일 플래그의 경우 허용됩니다 (인터럽트 메커니즘은 다음 강의에서 논의됩니다).
2.3) Df (방향 깃발) - 깃발 방향. 문자열 처리에서 데이터 처리 방향을 지정하는 데 사용됩니다. 단일 상태의 경우 라인은 "오른쪽에서 왼쪽으로"처리되고 0에서는 "왼쪽에서 오른쪽으로"처리됩니다.
PSW 레지스터의 플래그 위치는 그림 4.2에 나와 있습니다. 프리 비트는 추후 사용을 위해 예약되어 있습니다.
그림 4.2 - 레지스터 PSW의 플래그 레이아웃
RISC 프로세서 조직의 아키텍처 원칙.
/ 2, 14, 15 /에서 언급했듯이, 최신 마이크로 프로세서의 명령 목록에는 상당히 많은 명령이 포함될 수 있습니다. 그러나 이들 모두가 동등하게 자주 그리고 정기적으로 사용되는 것은 아닙니다. 이 명령어 세트의 기능은 RISC 아키텍처를 사용하는 프로세서 개발을위한 전제 조건이었습니다. 주된 아이디어는 사용 된 명령 목록을 줄이고 결과적으로 프로세서 제어 장치를 단순화하고 해방 된 수정 리소스를 희생시키면서 나머지 명령을 빠르게 실행하도록 구성하는 것이 었습니다.
명령어 세트가 축소 된 최초의 프로세서는 20 세기 초반 / 2 /에 구현되었습니다.
1) 1980 년 University of California, Berkeley에서 David Patterson 교수와 Carlo Sequin 교수의지도하에 RISC라는 프로세서가 개발되었습니다. RISC-I, RISC-II, SOLAR 모델이 개발되었습니다.
2) 1981 년 John Hennessy (Dohn Hennesy)의지도 아래 Stanford 대학에서 MIPS (Interlocked Pipeline Stages가없는 마이크로 프로세서 - 컨베이어를 막지 않는 마이크로 프로세서)라는 프로세서가 설계되었습니다. 파이프 라이닝의 본질에 대해 더 자세히 설명하면 다음 강의에서 논의 될 것입니다.
나중에 단축 된 명령어 세트를 가진 두 모델을 RISC 프로세서라고 부릅니다. 이 프로세서의 특징은 RON (약 256 개)이 많다는 것입니다.
우리는 RISC 아키텍처 / 2, 15 /의 기본 원리를 간략하게 설명합니다.
1) 동일한 명령 길이. 이렇게하면 주 메모리에서 쉽게 선택할 수 있습니다. 모든 명령은 1 클럭 주기로 판독되므로 컨베이어 원리를 따라 명령 명령의 흐름을 처리 할 수 있습니다. 즉, 한 하드웨어 장치에서 다른 하드웨어 장치로 제어를 순차적으로 전송하는 것을 고려하여 프로세서의 하드웨어 부분을 동기화합니다. 최신 RISC 프로세서에서 명령 길이는 32 비트입니다.
2) 메모리에 배치 된 피연산자에 대한 약식 동작 세트. 메모리 어드레싱의 간단한 방법은 메모리의 피연산자에 대한 빠른 액세스를 제공합니다. RISC 명령을 실행할 때 구현되는 데이터 처리는 메모리 읽기 (쓰기) 작업과 결합되지 않습니다 (많은 CISC 명령과 달리). 메모리와 레지스터 사이의 피연산자 교환은 특수로드 (LOAD) 및 메모리 (STORE) 명령에 의해 수행됩니다. 많은 수의 RON 블록 레지스터는 메모리 액세스 횟수를 줄여줍니다.
3) RON에만 배치 된 데이터에 대해 모든 계산 작업을 수행합니다. 레지스터가 많으므로 모든 스칼라 변수와 변수 배열이 레지스터에 가장 자주 배치되므로 데이터 처리 속도가 빨라집니다. 간단한 명령을 사용하면 파이프 라이닝 구현이 단순 해집니다. 평균적으로 RISC 명령은 한 주기로 실행됩니다.
4) 상대적으로 간단한 제어 체계. 단순한 조작만을 구현하는 명령을 사용하여 명령 목록을 줄이고 메모리 액세스에서 데이터를 처리하는 명령을 제외하면 제어를위한 수정 자원의 소비를 줄일 수있었습니다. 이로 인해 크리스탈의 넓은 영역이 프로세서의 전체 성능을 향상시킬 수있는 장치를 수용하도록 할당됩니다. 추가 파이프 라인, 1 차 수준의 캐시 메모리 증가, 더 많은 RHE.
동일한 생산 기술을 사용하는 RISC 프로세서는 CISC 프로세서에 비해 작동 주파수가 높다는 점에 유의해야합니다. 이는 RISC 프로세서의 중요한 장점입니다.
/ 15 /에 따르면 컨베이어의 계단을 형성하는 RISC 프로세서의 아키텍처에서 다음 하드웨어 블록을 구별 할 수 있습니다.
1) 명령어 로딩 블록 그것은 다음과 같은 구성 요소를 포함합니다 : 메모리로부터 명령을 가져 오는 블록, 선택 후 명령이 위치하는 명령의 레지스터, 명령을 디코딩하는 블록. 이 단계를 명령 선택 레벨이라고합니다.
2) 레지스터 제어 장치가있는 RON 명령의 피연산자를 읽는 책임이있는 파이프 라인의 두 번째 단계를 구성합니다. 피연산자는 명령 자체 또는 RON 중 하나에 저장 될 수 있습니다. 이 단계를 피연산자 선택 단계라고합니다.
3) ALU 및 배터리가이 아키텍처에서 구현되는 경우 제어 로직이는 명령어의 레지스터의 내용에 기초하여 수행되는 마이크로 동작의 유형을 결정한다. 조건부 및 무조건 점프 작업을 수행 할 때 명령 카운터는 데이터 소스 일 수도 있습니다. 이 단계를 컨베이어의 실행 단계라고합니다.
4) RON 및 쓰기 논리 세트 데이터 저장 단계를 형성합니다. 여기서 명령 실행 결과는 RHONE 또는 주 메모리에 기록됩니다.
마이크로 프로세서 MIPS Technologies Inc.의 MIPS R4000, R8000, R100000, UltraSPARC I, UltraSPARC II, Sun UltraSPARC III, IBM Motorola의 PowerPC, DEC의 Alpha AXP, Hewlett Packard의 PA-RISC, Microchip의 마이크로 컨트롤러는 RISC 프로세서로 분류됩니다. .
명백한 장점에도 불구하고 "순수한 형태의"RISC 프로세서는 PC 시장에서 널리 사용되지 않고 대부분 워크 스테이션의 중앙 프로세서로 사용됩니다. 그러나 대부분의 최신 CISC 프로세서 (예 : Pentium)는 RISC 아키텍처의 업적, 특히 RISC 코어를 사용하여 컴퓨터 작업을 수행합니다.
RISC 프로세서 모델이 활발하게 개발되고 개선되었습니다. 현재 상업적으로 중요한 제품이 SPARC 및 MIPS 시스템을 기반으로 구현되고 있습니다.
RISC 프로세서에 대한보다 완벽한 정보, 아키텍처 및 기능의 특징은 / 2 /, 특수 문헌 및 인터넷상의 오픈 소스에서 찾을 수 있습니다.
프로세서 성능을 향상시키는 아키텍처 방식. 컨베이어 정보 처리.
성능은 프로세서의 가장 중요한 특징 중 하나입니다. / 2 /에 따르면, 일반적으로 단위 시간당 수행되는 계산 작업의 양에 의해 결정됩니다. 성능에 영향을 미치는 가장 중요한 요소는 클록 주파수, 프로그램 명령 수 및 개별 명령의 평균 실행 시간을 포함합니다. 프로세서 성능을 단순하게 평가하기 위해 종종 초당 실행되는 명령의 수를 나타내는 표시기가 사용됩니다. 이는 별도의 명령으로 프로세서의 평균 실행 시간으로 클럭 주파수를 나눈 몫으로 정의되며 정수 작업의 경우 MIPS (Meg Insruction Per Second)로, 부동 소수점 계산의 경우 MFLOPS (Meg Floating Point Operations Per Second)로 측정됩니다. 이 경우 초당 수행되는 명령의 수를 결정하는 표시기의 추정은 주 메모리의 성능에 묶이지 않고 레지스터 피연산자를 사용하는 연산에 대해 수행됩니다. 그러나이 수치는 특정 프로세서의 특정 아키텍처를 고려하지 않았습니다. 따라서 서로 다른 프로세서의 비교 특성을 비교하기 위해 특수한 성능 테스트가 사용되는 상대적 성능 평가가 사용됩니다.
/ 2 /에 따라 대부분의 경우 프로세서 성능의 향상은 특수한 기술 및 아키텍처 솔루션을 사용하여 달성됩니다. 두 번째 장에서는 기술 접근법 (IP 생산 기술의 향상, 통합 정도의 향상)이 먼저 고려되었다. 따라서 우리는 프로세서의 성능을 향상시키는 아키텍처 방식에 대해 중점적으로 다룰 것입니다. 성능을 향상시키는 프로세서 아키텍처의 개선은 현재 주로 병렬 데이터 처리 도구의 개발과 관련되어 있습니다. 여기에서 다음 영역을 강조 표시 할 수 있습니다.
1) "자연스러운"병렬 처리 증가 - 처리 및 데이터 전송 비트 수 증가 (프로세서의 비트 수가 4에서 32 및 64 비트로 증가)
2) 컨베이어 (다단계) 데이터 처리 - 계산 프로세스는 여러 단계로 나뉘며 각 단계는 고유 한 수단과 결과를 저장하는 버퍼 (파이프 라인 단계)를 사용합니다.
3) 다중 데이터 처리 - 프로세서의 여러 운영 블록 (OA)에서 병렬 데이터 처리.
병렬 처리 방법을 결합 할 수 있습니다. 예를 들어, 한 프로세서에서 파이프 라이닝을 사용하는 여러 개의 작동 블록을 구성 할 수 있습니다.
마지막 두 가지 방향을 더 자세히 살펴 보겠습니다.
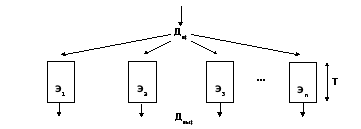
와 다단계 그림 4.3에서와 같이 데이터 처리는 여러 단계 (단계)로 나누어 져 순차적으로 수행됩니다.
그림 4.3 - 다중 위상 데이터 처리
단계 사이에는 중간 결과를 저장하기위한 버퍼가 있습니다. 첫 번째 단계가 완료된 후 결과가 버퍼에 저장되고 두 번째 단계 처리가 시작됩니다. 첫 번째 단계를 실행하기위한 도구가 해제되고 다음 데이터가 도착합니다. 처리 단계의 기간이 동일하고 T/ n,이 방법을 사용하면 시스템 성능이 n 시대 이 방법은 파이프 라인 처리에 해당합니다.
기계 명령 / 2 / 실행의 수준에서 파이프 라인의 구성을 고려하십시오. 컨베이어 체인의 각 블록은 명령 실행의 한 단계 만 수행합니다. 명령의 전체 처리에는 여러주기가 소요됩니다.
명령 실행의 일반적인 단계 : 1) IF 명령의 샘플링 (명령 페치), 2) 명령 ID 해독 (명령 디코드), 3) 피연산자 RD 읽기 (메모리 읽기), 4) 명령 EX (실행)에 지정된 작업 실행, 5) 쓰기 WB (Write Back) 결과. 팀이 실행되는 동안 파이프 라인을 통해 다음 팀의 다음 단계를 해제합니다. 컨베이어의 단계를 따라 전송 된 정보를 저장하는 데 사용되는 버퍼의 내용은 다음 명령의 실행 완료 후에 매번 업데이트됩니다. 중간 버퍼는 컨베이어 체인 블록을 독립적으로 독립적으로 작동시킵니다. 다음 블록이 다음 명령 단계를 수행하기 시작하는 동안 이전 블록은 그림 4.4와 같이 다음 명령 처리를 시작할 수 있습니다.
|
CPU주기 |
||||||||||
|
팀 나는 | ||||||||||
|
팀 i + 1 | ||||||||||
|
팀 i + 2 | ||||||||||
|
팀 i + 3 | ||||||||||
|
팀 i + 4 | ||||||||||
|
팀 i + 5 | ||||||||||
그림 4.4 - 파이프 라인 명령 처리
커맨드의 파이프 라인 처리는 별도의 커맨드의 실행 시간을 감소시키지 않으며, 이는 파이프 라인 프로세서에서 통상의 비 파이프 라인 프로세서와 동일하게 유지된다는 점에 유의해야한다. 그러나, 파이프 라인 처리 중에 커맨드의 동시 실행 모드에서 계산 프로세스의 대부분을 처리하는 동안, 순차적으로 실행되는 커맨드의 결과를 발행하는 속도는 컨베이어의 스테이지 수에 비례하여 증가한다는 사실로 인해, 명령 실행의 개별 단계 실행 기간은 일반적으로 명령 유형과 피연산자의 위치에 따라 다릅니다. 명령의 파이프 라인 처리는 명령 실행의 모든 단계가 거의 동일하면 가장 효과적입니다. 불행히도, 다양한 충돌 때문에 파이프 라인의 지속적인 작동을 보장하는 것이 항상 가능하지는 않습니다 : 자원, 데이터, 관리. 충돌에 대한 자세한 내용 - in / 2, 7 /.
명령 실행 프로세스가 5-6 단계로 나누어 진 프로세서를 보통이라고합니다. 파이프 라인 프로세서. 컨베이어의 단계 수를 늘리면 각 스테이지의 작업량이 줄어들며 하드웨어 로직이 적어집니다. 컨베이어의 각 단계에서 더 짧은 신호 전파 지연으로 인해 작동 주파수의 증가와 이에 상응하는 프로세서 성능의 향상이 달성됩니다. 프로세서는 5-6 단계보다 훨씬 더 깊은 컨베이어를 가지고 있습니다. 초 컨베이어. 예를 들어, Pentium II에는 12 단계, UltraSPARC III - 14 레벨, Pentium 4 - 20 레벨이 있습니다.
다중 요소
T 시스템에서 사용됩니다. n T/ n
A = B + C; D = 전자 + F.
수퍼 스칼라스칼라스칼라
프로세서 성능을 향상시키는 아키텍처 방식. 다중 정보 처리.
그림 4.5 / 2 /에서 볼 수 있듯이, 다중 요소 여러 병렬 OS에서 처리가 수행됩니다. 각 요소는 처음부터 끝까지 데이터의 일부를 처리하여 작업을 수행합니다.
그림 4.5 - 다중 병렬 데이터 처리
별도 항목의 실행 시간이 T 시스템에서 사용됩니다. n 그런 다음 특정 이상화를 통해 이러한 작업을 완료하는 평균 시간은 T/ n (정말로 - 덜). 최신 프로세서에서이 처리 방법은 수퍼 스칼라 아키텍처의 개념과 관련됩니다.
연산 병렬 처리의 가장 간단한 예는 피연산자가 서로 관련이없는 두 개의 명령어를 실행하는 것입니다.
A = B + C; D = 전자 + F.
따라서 두 명령을 동시에 실행할 수 있습니다. 관련없는 연산을 수행하기 위해 프로세서에는 일련의 산술 장치가 포함되어 있으며 각 산술 장치에는 보통 파이프 라인 구성이 있습니다.
둘 이상의 스칼라 명령을 동시에 실행할 수 있도록 여러 OU가 포함 된 프로세서를 호출합니다. 수퍼 스칼라 프로세서. 팀이 호출됩니다. 스칼라입력 피연산자와 결과가 숫자 (스칼라) 인 경우 하나의 opamp와 함께 전통적인 프로세서가 호출됩니다. 스칼라. 수퍼 스칼라 프로세서에서 명령 처리는 시간 (파이프 라인)뿐만 아니라 공간 (여러 파이프 라인)에서도 병렬화됩니다. 이러한 프로세서의 성능은 모든 파이프 라인에서 실행 된 명령의 강하 속도로 추정됩니다.
현재 수퍼 스칼라 처리의 두 가지 방법이 사용됩니다. 첫 번째 방법은 관련없는 프로그램 명령을 메모리 (캐시 메모리, 프리 페치 버퍼)에서 가져 와서 실행을 위해 병렬 실행하는 순수한 하드웨어 메커니즘을 기반으로합니다. 병렬 기능 파이프 라인을로드하는 효율성에 대한 책임은 프로세서 하드웨어에 달려 있으며, 이는 수퍼 스칼라 처리 방법의 주요 이점입니다. 이 경우 수퍼 스칼라 프로세서 용 프로그램을 변환하는 프로세스는 기존 스칼라 프로세서 용 프로그램을 변환하는 프로세스와 다르지 않습니다. 이 방법에 따르면, 다양한 패밀리의 수퍼 스칼라 마이크로 프로세서는 프로그램 적으로 서로 호환 가능하다. 이 경우 이전에 작성한 소프트웨어를 사용할 때 아무런 문제가 없습니다. 펜티엄 제품군의 모든 프로세서는이 방법을 사용하여 구현됩니다.
슈퍼 스칼라 처리의 제 2 방법을 구현하는 프로세서에서, 몇몇 명령의 병렬 실행 계획은 병렬 컴파일러에 의존한다. 그는 먼저 동시에 실행될 수있는 명령을 식별하기 위해 소스 프로그램을 분석합니다. 그런 다음 컴파일러는 이러한 명령을 명령 패키지 - 긴 명령어 (VLIW)로 그룹화하고 VLIW 명령의 단순 명령 수는 프로세서의 실행 단위 수와 동일하게 취합니다. 컴파일러는 VLIW 명령의 실행을 준비하는 모든 작업을 수행하기 때문에 충돌 상황은 실행시 제외됩니다. 수퍼 스칼라 처리 방법은 정적 sperscaler 아키텍처를 가진 VLIW 프로세서에서 구현됩니다. 불행히도 이러한 프로세서에는 특별한 소프트웨어가 필요합니다. 또한 한 세대의 마이크로 프로세서에 대해 컴파일 된 프로그램은 차세대 프로세서에서 재 컴파일하지 않으면 비효율적으로 실행될 수 있습니다. 이를 위해서는 소프트웨어 개발자가 여러 세대의 프로세서에 대해 제품 실행 파일의 수정 된 버전을 개발해야합니다. VLIW 아이디어는 B.A. 교수가 이끄는 러시아 엔지니어와 과학자들에 의해 제안되었습니다. Babayan은 국내 슈퍼 컴퓨터 "Elbrus-3"(1990) 개발에 참여했습니다. 현재 VLIW 기술은 국내 회사 인 Elbrus International의 Elbrus E2K 프로세서, Transmeta의 Crusoe 프로세서 및 Texas Instruments의 TMS320C60xx에 의한 신호 처리기 제품군에서 구현됩니다.
프로세서의 분류 및 명령 구조.
기능상 모든 프로세서 명령은 다음 그룹으로 나눌 수 있습니다.
1) 데이터 전송 및 I / O 명령;
2) 산술 및 비트 논리 연산 팀;
3) 전송 명령을 제어합니다.
데이터 전송 명령 메모리 또는 입력 장치로부터 프로세서로 그리고 프로세서로부터 메모리 또는 출력 장치로 프로세서로 전송하는 동안 외부 데이터 교환뿐만 아니라 마이크로 프로세서 레지스터간에 정보 교환을 제공한다. 이러한 명령은 대개 전송 방향, 데이터의 소스 및 / 또는 수신자를 나타냅니다. 예를 들어 어셈블리 언어에서이 그룹의 명령에는 transfer 명령 Mov시동 명령 LOAD포트에 쓰고 포트에서 읽는 명령 UVV, IN 및 밖으로각각 또한 종종 스택에 데이터를 저장하는 명령을 포함합니다. 푸시 스택에서 데이터를 추출한다. 대중 음악.
번호 있음 산술 및 비트 논리 연산 명령 대부분의 경우 명령에 ADD (추가), SUB (빼기) 및 논리 연산 (예 : AND ( "AND"), OR ( "OR") 등)과 같은 간단한 산술 연산이 포함됩니다. 산술 및 논리 시프트 명령은 산술 명령이라고도하며 비교 (비파괴 뺄셈) 비교 명령은 논리 연산 명령이라고도합니다. 이 그룹의 명령 수에는 곱셈, 나눗셈 (모든 프로세서에서 사용할 수 없음), 부동 소수점 데이터 처리 명령, 멀티미디어 처리 명령과 같은 복잡한 산술 연산에 대한 명령이 포함될 수 있습니다.
전송 명령 제어 프로그램 분기가있을 때 조건부 및 무조건 부 (JMP) 점프, 서브 루틴 호출 (CALL) 및 종료 (RETURN) 명령 실행 순서를 변경하는 데 사용됩니다. 조건 점프 명령은 PSW 레지스터의 플래그 값에 따라 제어 전송을 구현합니다. 그들의 도움으로 프로세서는 프로그램 계속의 가능한 부분 중 하나입니다. 일반적으로 명령 시스템에는 몇 가지 조건부 점프 명령이 있습니다.
현대 프로세서에서 명령 시스템은 위에 열거 된 전통적인 명령과 함께 마이크로 프로세서의 정보 처리 기능을 확장하고 작업을 제어하며 멀티 태스킹 보호 작업의 구현을 보장하는 팀 팀을 포함합니다.
특정 프로세서의 명령 시스템에는 제안 된 분류에 맞지 않는 명령이 포함될 수 있습니다. 이러한 명령은 프로그램 작성의 일반 원칙을 반영하지 않으며 추가로 간주됩니다.
명령 (기계 작동)의 실행은 미세 동작 (마이크로 명령)의 작은 단계로 나뉘며, 그 동안 특정 기본 동작이 수행됩니다. 미세 조작의 구체적인 구성은 명령 시스템과 컴퓨터의 논리적 구조에 의해 결정됩니다. 이 조작 (명령)을 구현하는 마이크로 명령어의 순서는 조작 펌웨어를 형성합니다. 하나 또는 여러 개의 미세 작업이 동시에 수행되는 시간 간격을 기계 촉지 (machine tact)라고합니다. 사이클의 경계는 클록 발생기에 의해 생성 된 클럭 신호에 의해 설정됩니다.
일반적으로 마이크로 프로세서 명령은 작동 및 주소라는 두 부분으로 구성됩니다. / 1 /에 따라 명령의 이러한 부분 들간의 비트 분배에 대한 합의와 정보 인코딩 방법에 따라 명령의 구조 (형식)가 결정됩니다. 명령의 조작 부분은 조작 코드를 제공하는 조작 코드를 포함합니다 (여기서, n - 명령의 조작 부분에 대해 할당 된 2 진수의 수)를 결정하고 프로세서에서 또는 어떤 장치를 사용할 것인지 결정합니다. 있음 k명령의 비트 주소 부분은 조작과 관련된 피연산자의 주소에 대한 정보를 포함합니다. 일반적으로 명령의 주소 부분에는 네 개의 주소 필드가 있어야합니다. A1 , A2 , A3 , A4 . 이들은 피연산자의 주소 (A1, A2), 결과의 주소 (A3) 및 다음 명령의 주소 (A4)를 지정하도록 설계되었습니다. 어드레스 (A1, ..., A3)로서, 메모리 셀의 어드레스 및 마이크로 프로세서 메모리 레지스터의 어드레스가 어드레스 (A4)로서 메모리 셀의 어드레스 만 사용될 수있다. 전체 주소 세트를 사용할 때 명령 형식은 번거 롭습니다. 모든 작업이 A1-A4의 전체 주소 세트를 필요로하는 것은 아니라는 점에 유의해야합니다. 표시된 주소 수에 따라 명령이 다음과 같이 나뉩니다. 0- 어드레스 (어드레스없는), 1- 주소, 2 주소, 3- 주소 및 4- 주소.
거의 모든 마이크로 프로세서에서 A4 주소는 제외됩니다. 이는 대부분의 명령이 알고리즘의 선형 부분에 속하고 이러한 명령을 주소가 연속적으로 증가하는 메모리 셀에 배치 할 수 있기 때문입니다. 이 경우 다음 명령의 주소를 가져 오려면 코드 세그먼트의 오프셋을 코드 세그먼트의 시작 주소에 추가하면 충분합니다. 이는 명령 포인터로 구현하는 것이 편리합니다. 명령을 처리하는이 방법은 자연의, 그것을 구현하는 프로세서가 호출된다. 명령어를 다루는 자연스러운 방식의 프로세서. 명령의 자연 순서 (브랜치, 사이클)를 위반하는 경우, 전환 제어 주소를 포함하지만 피연산자의 주소를 사용하지 않는 특수 제어 전송 명령이 사용됩니다. 프로세서는 주소 A4를 사용하는 명령의 주소 필드에 호출됩니다. 강제 명령 주소 지정 기능이있는 프로세서.
대부분의 경우 결과 A3의 주소를 사용하면 중복되는 것으로 판명됩니다. 이것은 두 개의 피연산자에 대한 산술 및 논리 연산의 결과가 피연산자 중 하나의 위치에 배치 될 수 있다는 사실에 의해 정당화됩니다. 피연산자는 나중에 사용되지 않을 가능성이 높습니다. 동시에 2 주소 명령에서 주소 필드에 추가 자릿수를 입력하여 소스 중 어느 것이고 정보의 수신자인지 표시해야합니다. 배터리 아키텍처를 사용하는 프로세서에서는 명령의 주소 부분에있는 주소 수가 1로 줄어 듭니다. 그것들에서 누산기에 놓인 피연산자 중 하나는 명령 코드에 의해 암시 적으로 주어지며 결과는 누산기에 저장됩니다.
주소 지정되지 않은 명령어에서는 피연산자의 암시 적 사양이 수행됩니다. 이러한 명령에는 프로세서 제어 명령 (예 : 시작, 중지 등), 스택 작업을위한 명령 (SP 포인터로 주소 지정된 피연산자가 명령 코드에 의해 암시 적으로 지정됨)이 포함됩니다. 명령되지 않은 명령은 매우 축약 된 형식이지만 기능적으로 완전한 명령 시스템을 독립적으로 구성 할 수 없으며 주소와 함께 사용됩니다.
명령 형식은 문제 해결 시간, 메모리 비용, 프로세서 복잡성에 영향을 미치며 해결할 작업 클래스에 따라 달라집니다. 특히 다단계 계산으로 많은 양을 차지하는 과학 및 기술 계산의 경우 1- 주소 명령이 더 효과적이며 스택 프로세서를 사용하는 경우 비 주소 명령도 사용됩니다. 관리 작업의 경우 많은 양의 출하 및 논리적 작업이 2 주소 명령 인 경우 효과적입니다. 위의 내용을 토대로, 현대 프로세서는 보통 주소없는 1 주소 및 2 주소 명령을 사용합니다. 3 주소 명령은 거의 사용되지 않으며 4 주소 명령은 전혀 사용되지 않습니다.
명령 및 데이터 형식 (숫자, 기호, 구조 등)의 다양한 형식과 위치에 따라 여러 가지 방법의 주소 지정 명령어와 피연산자가 만들어 졌으므로 아래에서 설명합니다.
데이터 주소 지정 방법. 직접, 직접, 간접, 등록 상대 주소 지정 모드.
데이터 어드레싱 방법은 메모리에서 피연산자의 유효 주소를 계산하고 피연산자에 액세스하는 메커니즘을 결정합니다. / 2, 6 /을 주소 지정하는 다음 방법 (모드)을 할당하십시오.
1) 즉시 - 명령의 주소 부분에 직접 피연산자의 고정 값을 설정할 수 있습니다. 즉 명령의 일부입니다 (그림 5.1). 이 주소 지정 모드는 상수로 작업 할 때 편리합니다.
그림 5.1 - 직접 주소 지정
예 : mov ax, 5564h
1101001100b 추가
직접 피연산자는 소스 피연산자로만 지정할 수 있다는 점을 기억해야합니다. 직접 주소 지정의 단점은 명령의 주소 필드에 피연산자 자체를 지정하여 명령 형식을 확장해야한다는 점입니다.
2) 직접 - 피연산자의 주소는 명령 코드에 포함됩니다 (그림 5.2). 작업 실행 중 메모리의 위치가 변경되지 않는 변수 및 상수로 작업 할 때 사용됩니다.
![]()
그림 5.2 - 직접 주소 지정
따라서 명령 코드는 메모리에있는 피연산자의 오프셋을 나타냅니다.
예 : d_s 세그먼트
가정 ds : d_s, cs : c_s
mov 도끼 , mm ; 주소 mm 보낸 3154h
레지스터에서 세 번째 명령을 실행 한 후 도끼 값이 다음에 기록됩니다. mm 즉, 번호 3154h에 저장된다.
3) 등록 - 이는 명령에 의해 정의 된 레지스터에 포함된다. 즉, 레지스터의 어드레스는 명령의 어드레스 필드에 표시된다.
예 : mov ax, cx
레지스터 어드레싱은 명령어의 모든 피연산자가 레지스터라는 사실로 다른 모든 레지스터와 쉽게 구별됩니다. 이러한 명령은 메모리 액세스가 없기 때문에 가장 작고 다른 명령 유형보다 빠르게 실행됩니다.
4) 간접 등록 - 명령에 지정된 주소가 메모리의 피연산자 오프셋을 포함하는 셀에 대한 포인터 일 때 간접 주소 지정의 특별한 경우입니다 (그림 5.3).
사실, 명령은 주소의 주소를 지정하고 기본 레지스터는 주소 레지스터로 사용할 수 있습니다 혈압 또는 인덱스 레지스터 SI 또는 DI.
직접 주소 지정보다 간접 주소 지정이 더 효율적입니다. 명령의 주소 필드에서 메모리의 피연산자의 전체 주소보다 짧은 레지스터 주소 만 표시되기 때문입니다. 그러나이 어드레싱 모드에서는 간접 메모리 주소로 레지스터 사전로드가 필요하므로 추가 시간이 필요합니다.
예 : mov ax,
등록부에있는 경우 시 10이 포함되면 레지스터 도끼 이것은 데이터 세그먼트의 오프셋 10에 값을 넣습니다.
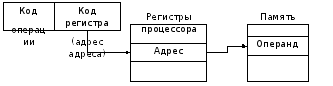
그림 5.3 - 간접 주소 지정
간접 주소 지정은 명령에서 레지스터의 주소를 변경하지 않고 그대로두면 문제를 해결할 때 편리합니다.이 주소로 셀 내용을 변경할 수 있습니다.
5) 등록 친척 - 실제 주소의 계산을 제공하는 주소 지정 방법의 일반화입니다 ( EA) 피연산자를 주소의 기본 값과 명령 (그림 5.4)과 (수식 5.1)에 지정된 disp의 "변위"의 합으로 계산합니다.
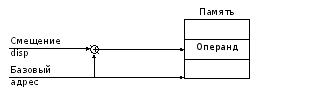
그림 5.4 - 효과적인 주소를 형성 할 때
상대 주소 지정
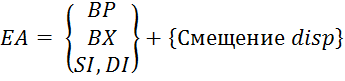 (5.1)
(5.1)
상대 주소 지정은 블록 (예 : 세그먼트)으로 표시된 메모리를 지정하고 특수 데이터 구조 (주소, 배열, 레코드 등)를 처리하는 데 널리 사용됩니다. 레지스터 인 명령 레지스터의 사용법에 따라 기본 및 인덱스 주소 지정 모드가 구분됩니다.
5.1) 색인 - 정렬 된 데이터 배열을 처리하는 데 사용되며, 각 배열은 자체 번호에 의해 결정됩니다. 그런 다음 배열의 기본 주소는 명령에 지정된 오프셋 disp에 의해 지정되고 인덱스 값 (배열 요소의 수)은 인덱스 레지스터의 내용에 의해 결정됩니다 (수식 5.2).
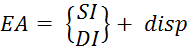 (5.2)
(5.2)
예 : d_s 세그먼트
mas db 3,5,1,8,9, '$'
가정 ds : d_s, cs : c_s
mov si, 0; 배열 요소의 si 번호에
m1 : mov 아, mas mas 오프셋
ah - mas 배열 요소의 값
; si의 숫자
인덱싱은 행에없는 연속적인 메모리 셀의 데이터 목록을 쓰거나 읽을 필요가 있지만 색인에 표시된 일부 단계를 사용하면 편리합니다.
5.2) 기본 - 가변 길이 데이터 구조에 액세스하는 데 사용됩니다. 그런 다음 요소 집합의 시작을 결정하는 기본 주소가 기본 레지스터에 저장되고 명령의 오프셋은 특정 요소 (수식 5.3)까지의 거리를 결정합니다.
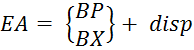 (5.3)
(5.3)
이 어드레싱 모드는 길이가 다르며 가능하면 다른 유형의 필드를 포함하는 데이터 구조에 유용합니다.
특정 부서의 직원 기록과 그 부서 및 해당 필드에 대한 액세스를 구성하는 예를 고려해보십시오. 우리는 모든 분야가 상징적이라는 것에 동의합니다.
직원 구조 정보, 직원 정보
이름 db 30 dup ( ""); 성, 이름, patronymic
위치 db 30 dup ( ""); 위치
나이 db 2 dup ( ''); 나이
대기 db 2 dup ( '');
salary db 5 dup ( ''); 루블의 급여
직원 한 명에 대한 설명
sotr1 작업자<‘Иванов Пётр Сергеевич’,
'프로그래머', '30', '8', '15000'\u003e
가정 ds : d_s, cs : c_s
우리는 bx에 기록을 시작할 주소 (기본 주소)를로드하고,
레아 bx , sotr 1
; ax에서 - 주소 bx + 오프셋 필드 에이지의 값
즉, 기록의 시작부터, 우리는 세포를 발견하고,
mov 도끼 , 단어 태평양 표준시 [ bx ]. 나이
길이가 다른 필드가있는 레코드의 경우 주소 지정이 가능한 레지스터의 내용은 레코드의 시작 부분에 해당하며 명령의 오프셋은 레코드의 거리와 일치합니다.
데이터 주소 지정 방법. 레지스터,베이스 인덱스, 상대베이스 인덱스 어드레싱 모드.
6) 기본 인덱스 - 배열 요소를 액세스하는 데 사용되며 포인터로 주소가 지정됩니다. 배열의 기본 주소는 기본 포인터 (기본 레지스터)에 의해 지정되고 배열 요소의 수는 인덱스 레지스터 (수식 5.4)의 내용에 의해 지정됩니다.
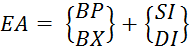 (5.4)
(5.4)
예 : mov ax, bx
에서 bx 100 포함 시 52이면, 데이터 세그먼트의 어드레스 (오프셋) (152)에서 원하는 데이터가된다.
이 어드레싱 모드는 두 개의 주소 구성 요소를 변경할 수 있기 때문에 복잡한 데이터 구조로 작업 할 때 유용합니다.
7) 상대베이스 인덱스 - 지정된 레코드 배열의 요소를 주소 지정하는 데 사용됩니다. 배열의 기본 주소는 기본 포인터에 의해 지정되고 레코드 번호 (즉, 배열 요소)는 인덱스 레지스터의 내용에 의해 결정되며 명령의 오프셋은 레코드와의 거리 (수식 5.5)를 나타냅니다.
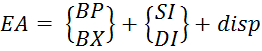 (5.5)
(5.5)
우리는 값이있는 5 명의 직원 배열을 설명합니다.
기본값
mas_sotr worker 5 dup (<>)
가정 ds : d_s, cs : c_s
bx - 직원 배열 시작 부분의 주소
레아 bx , 매스 _ sotr
; in si - 두 번째 레코드의 오프셋
mov 시 , ( 유형 노동자 )*2
; 도끼 - 두 번째 직원의 경험
mov ax, .standing
따라서 레코드 배열의 특정 필드에 대한 액세스 권한을 얻으려면 먼저 배열의 시작 부분을 확인하고 필요한 레코드를 찾은 다음 필요한 필드를 찾아야합니다.
어드레싱 모드의 선택은 특정 작업에 의해 결정되며 많은 경우에 분명합니다. 그러나 동일한 데이터 요소에 액세스하기 위해 여러 가지 주소 지정 방법을 사용할 수있는 경우가 있습니다. 마지막으로, 프로그램을 작성할 때 사용자 자신이 특정 주소 지정 모드를 선택합니다.
명령어를 어드레싱하는 방법.
필요한 명령이있는 코드 세그먼트와 주소가 명시 적으로 표시되는지 여부에 따라 다음 명령 주소 지정 모드가 구분됩니다.
1) 인트라 세그먼트 스트레이트- 유효 전환 주소는 IP 명령 포인터의 현재 내용과 8 또는 16 비트 상대 오프셋의 합계로 계산됩니다. 이 모드는 조건부 및 무조건 부 전환에서 유효합니다. 예를 들어
레지스터의 내용 아 및 알 평등하지 않다 (팀 jne), 레이블이있는 명령으로 이동하십시오 만났다.
2) 직 접 상호 - 팀은 세그먼트와 오프셋을 표시합니다. 세그먼트는 CS 세그먼트 레지스터에로드되고 오프셋은 IP 레지스터에로드됩니다. 이 모드는 무조건 점프 명령에서만 허용됩니다. 예를 들어 far ptr quickSort (다른 코드 세그먼트에있는 quickSort 프로 시저 호출)를 호출합니다.
따라서 직접 주소 지정을 사용하면 명령의 주소에 전환의 주소 (실행중인 다음 명령이있는 주소)가 포함됩니다.
3) Intrasegment indirect - 전이 어드레스 오프셋은 모든 데이터 어드레싱 모드에서 지정된 레지스터 또는 메모리 위치의 내용입니다 (즉, 즉시 제외). IP 명령 포인터의 내용은 레지스터 또는 메모리 셀의 해당 내용으로 대체됩니다. 이 방법은 무조건 부 분기 명령에서만 유효합니다. 예를 들어 jmp (레지스터에 지정된 주소의 셀에 주소가있는 명령으로 이동) bx).
4) 세그먼트 간접 - CS 레지스터와 IP 레지스터의 내용은 직접 데이터와 레지스터 데이터를 제외한 모든 데이터 어드레싱 모드로 지정된 두 개의 인접한 메모리 워드의 내용으로 대체됩니다. 하위 워드는 IP 레지스터에로드되고 상위 워드는 CS 레지스터에로드됩니다. 이 모드는 무조건 분기 명령에서만 유효합니다. 예를 들어, far ptr (BP 레지스터에 지정된 주소에있는 프로 시저 호출 + 4 바이트 더)을 호출하십시오.
명령을 처리하는 데 고려되는 방법은 거의 모든 명령 시스템에서 사용되며 특정 마이크로 프로세서에 대한 명령 목록을 확장하거나 축소합니다.
앞서 언급했듯이, 프로세서의 중요한 특징 중 하나는 내부 레지스터의 폭과 외부 주소 및 데이터 버스뿐입니다. 예를 들어 Intel 8086 프로세서는 16 비트 아키텍처와 동일한 데이터 버스 너비를 가지고 있습니다. 따라서 프로세서가 처리 할 수있는 최대 개수는 ![]() . 그러나 Intel 8086 프로세서의 주소 버스에는 MB의 주소 공간에 해당하는 20 개의 라인이 있습니다. 메모리 셀의 20 비트 물리적 주소를 얻으려면이 셀이 위치한 메모리 세그먼트의 시작 주소와 세그먼트 시작 부분에 대한이 셀의 오프셋을 추가해야합니다 (그림 5.5).
. 그러나 Intel 8086 프로세서의 주소 버스에는 MB의 주소 공간에 해당하는 20 개의 라인이 있습니다. 메모리 셀의 20 비트 물리적 주소를 얻으려면이 셀이 위치한 메모리 세그먼트의 시작 주소와 세그먼트 시작 부분에 대한이 셀의 오프셋을 추가해야합니다 (그림 5.5).
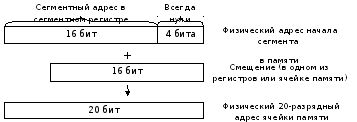
그림 5.5 - 메모리 셀의 물리적 주소 형성
4 개의 하위 비트가없는 (즉, 16으로 나뉘어 진) 세그먼트 어드레스는 세그먼트 레지스터 (SS, DS, CS, ES) 중 하나에 저장된다.
물리적 주소를 계산할 때 프로세서는 세그먼트 레지스터의 내용에 16을 곱하고 결과로 나오는 20 비트 주소에 오프셋을 추가합니다.
현대의 32 비트 프로세서는 32 비트 주소 버스를 가지며 GB의 주소 공간에 해당합니다. 그러나, 상술 한 물리 어드레스를 형성하는 방법은 1 Mbyte를 넘는 것을 허용하지 않는다. 32 비트 프로세서에서 이러한 한계를 극복하기 위해 실제 및 보호의 두 가지 작동 모드가 사용됩니다. 있음 진짜 모드 프로세서는 실제로 인텔 8086과 동일한 방식으로 작동하며 속도가 향상되고 1MB의 주소 공간 만 액세스 할 수 있습니다. 나머지 메모리는 컴퓨터에 설치되어 있어도 사용할 수 없습니다. 있음 보호 모드 세그먼트 및 오프셋도 사용되지만 세그먼트의 물리적 시작 주소는 동일한 세그먼트 레지스터를 사용하여 인덱싱 된 세그먼트 설명 자의 테이블에서 추출됩니다. 각 세그먼트 디스크립터는 8 바이트를 차지하며 그 중 4 바이트 (32 비트)가 세그먼트 주소에 할당됩니다. 이 메커니즘을 통해 32 비트 주소 공간을 완전히 사용할 수 있습니다. 64 비트 프로세서에서 메모리의 세그먼트 구성도 사용되며 세그먼트 / 페이지 / 1 / 메모리 구성을 사용할 수 있습니다. 40, 44, 48, 64 비트가 물리 주소에 할당됩니다. 따라서 64 비트 마이크로 프로세서의 주소 공간은 1TB (1 테라 바이트)에서부터 수 Ebyte (1Exabyte-byte)까지 다양합니다.
이전 장에서는 프로세서가 컴퓨터의 개별 장치의 기능을 조정하는 반면, 사용자 프로그램 (프로그램 관리 원칙)에 따라 계산을 수행한다고 언급했습니다. 다음으로, 우리는 프로세서가 어떻게 명령을 실행하고 다른 장치와 상호 작용 하는지를 고려합니다.
통제권 이전. 전환과 절차.
/ 8 /에 따르면, 제어 흐름 - 명령이 프로그램 실행 중에 동적으로 실행되는 순서입니다. 대부분의 명령은 제어 흐름을 변경하지 않습니다. 하나의 명령을 실행 한 후 그 명령을 메모리에서 실행합니다. 각 명령 실행 후 명령 카운터 (IP)는 명령의 길이에 해당하는 숫자만큼 증가합니다. 제어 흐름의 변경은 예외 및 인터럽트가 발생할 때뿐만 아니라 전환 명령 (조건부 및 무조건 부), 호출 프로 시저, 동시 루틴이있을 때 발생합니다.
1) 전환 팀. 명령을 실행하여 IP 명령의 카운터로 가면 새로운 값이 강제로 기록됩니다 - 명령이 실행될 메모리의 새 주소.
팀 무조건적인 전이 조건을 확인하지 않고 주어진 주소로 전환을 제공합니다. 예를 들어, jmp met는 주소로 시작하는 명령으로 이동합니다. 만났다 이 프로그램의 텍스트에 동시에 모든 이전 명령은 건너 뜁니다.
조건부 천이 (분기)는 특정 조건이 충족 될 경우에만 발생하고, 그렇지 않으면 다음 프로그램 명령이 실행됩니다. 전이가 수행되는 조건은 대개 앞의 산술 또는 논리 명령을 실행 한 결과의 부호입니다. 각 부호는 PSW 플래그 레지스터의 자체 비트로 고정됩니다. 이러한 접근법은 전이에 대한 결정이 비교 연산 / 3 /의 결과가 이전에 배치 된 범용 레지스터 중 하나의 상태에 따라 이루어지는 경우에도 가능합니다. 예제를 고려해보십시오.
|
jz m1 m1 : 추가, 2 |
cmp 아, 알 제이 m1 m1 : 추가, 2 |
왼쪽 조각은 플래그, 특히 제로 플래그 ZF를 사용하여 등호에 대한 레지스터 AH와 AL의 내용 검증을 보여줍니다. 레지스터 내용의 미리 수행 된 뺄셈 : 값이 같으면 결과는 0이고 ZF 플래그의 값이 변경됩니다. JZ 명령은 ZF 플래그가 1인지 확인한 다음 주소가 M1 (add al, 2) 인 명령으로 전환합니다. 그렇지 않으면 추가 명령이 add ah, 3 실행됩니다. 임의의 경우에 어드레스 M2를 갖는 명령이 실행된다. 오른쪽 단편은 비교 명령 (cmp ah, al)과 같음 전이 명령 (je m1)을 사용하지만 동일한 검사를 수행합니다.
2) 절차. / 3.8 /에 따르면, 프로그램을 구성하는 중요한 방법은 절차입니다. 프로그램의 어느 지점에서나 호출 할 수 있습니다. 그러나 전환 명령과는 달리, 프로 시저 실행 후 제어는 프로 시저 호출 명령 다음의 명령으로 돌아갑니다.
절차 메커니즘은 프로그램의 현재 지점에서 초기 프로 시저 명령으로의 전환을 제공하는 프로 시저 호출 명령을 기반으로하며 호출 명령 바로 뒤에있는 지점으로 돌아가려면 프로 시저에서 명령을 반환합니다. 절차를 사용하기 위해 호출 명령이 intrasegment 전이 (또는 intersegment 전이를위한 IP 및 CS 레지스터)를 위해 프로그램 카운터 (IP)의 현재 값을 배치하는 스택이 사용됩니다 (대기열로 구성된 추가 메모리). 프로 시저를 종료 할 때 해당 레지스터의 이전 값이 스택에서 복원됩니다. 절차는 PROC 및 ENDP 연산자로 제한됩니다.
특히 직접적으로 또는 다른 프로 시저 체인을 통해 스스로를 호출하는 프로 시저 인 재귀 프로 시저가 특히 중요합니다. 이러한 절차의 경우 반환 주소 외에도 각 호출에 대한 매개 변수 및 로컬 변수가 저장되는 스택이 사용됩니다.
프로 시저 호출을 사용하는 프로그램의 예를 생각해보십시오. 프로 시저가 주 프로그램과 동일한 코드 세그먼트에 있으며 단거리 프로 시저 (NEAR 지시문)로 설명되기 때문에 전환은 내재적입니다.
s_s 세그먼트 스택 "스택"
ss : s_s, ds : d_s, cs : c_s로 가정합니다.
전화하다 홍보 1 서브 루틴 호출
mov 아 ,4 ch
홍보1 proc가까운 ; 시작 서브 루틴 (중간 호출)
push ax; 레지스터 AX의 내용을 스택에 쓴다.
pop ax; 레지스터 AX의 내용을 스택에서 선택
ret 후 다음 명령으로 명령을 반환
호출 절차
홍보1 끝내다 ; 서브 프로그램의 끝
PR1 프로 시저 (pr1 명령 호출)를 호출하면 반환 주소가 스택에 배치됩니다. 현재 주소 다음에 실행해야하는 명령 주소가 들어있는 IP 명령 카운터의 내용 (mov ah, 4ch)입니다. IP 레지스터의 값은 프로 시저의 첫 번째 명령 주소 인 새 값으로 대체됩니다. 스택에서 프로 시저 (ret)의 return 명령에 도달하면 이전 값이 IP 레지스터에 기록되어 프로 시저 호출 명령 바로 다음에 오는 mov ah, 4ch 명령의 주 프로그램으로 반환됩니다.
호출자와 수신자 절차의 상호 작용은 그림 5.6 / 8 /에 나와있다.
통제권 이전. 코 루틴. 예외 및 인터럽트
코 루틴. 일반적인 호출 순서에서는 호출 된 프로 시저와 호출하는 프로 시저간에 명확한 구분이 있습니다. 호출 된 프로시 저는 호출 된 횟수와 상관없이 다시 시작됩니다. 호출 된 프로 시저를 종료하려면 이전 단락에서 설명한대로 RET return 명령을 사용하십시오. 프로 시저로서 각각을 호출하는 두 개의 프로 시저 A와 B가 있다고 가정합니다. B에서 A로 돌아갈 때, 프로시 듀어 B는 프로시 듀어 B의 호출 명령 다음에 해당 연 j 자로 전이합니다. 프로시 듀어 A가 프로시 듀어 B로 제어를 넘길 때, 처음부터 제외하고는 B의 맨 처음이 아닌, 이전 호출 A.이 방법으로 작동하는 절차가 호출됩니다. 코 루틴.
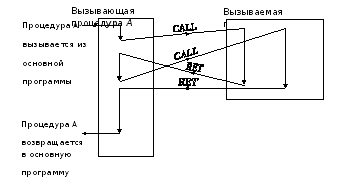
그림 5.6 - 발신자와 수신자 간의 상호 작용
절차
코 루틴은 일반적으로 단일 프로세서에서 데이터의 병렬 처리를 수행하는 데 사용됩니다. 일반적인 CALL과 RET 명령은 콜론을 호출하는 데는 적합하지 않습니다. 왜냐하면 반환 할 때와 마찬가지로 전환 주소가 스택에서 가져 오기 때문에 반환과 달리 콜 루틴을 호출 할 때 반환 주소는 나중에 다시 반환하기 위해 특정 위치에 배치됩니다. 이렇게하려면 먼저 스택에서 이전 반환 주소를 푸시하고 내부 레지스터에 배치 한 다음 IP 명령 카운터를 스택에 놓고 마지막으로 내부 레지스터의 내용을 명령 카운터에 복사해야합니다. 한 단어가 스택에서 푸시되고 다른 단어가 스택으로 푸시되기 때문에 스택 포인터의 상태는 변경되지 않습니다. 코 루틴의 상호 작용 패턴은 그림 5.7 / 8 /에 나와 있습니다.
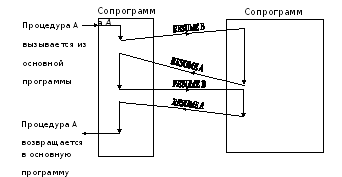
그림 5.7 - 상호 작용 (Corouting Interactions)
4) 예외 및 인터럽트 특별한 절차에 대한 통제의 강제적 인 이전 제공 - 트랩 처리기특정 작업을 수행합니다. 작업을 완료 한 후 인터럽트 처리기는 중단 된 프로그램에 제어를 반환합니다. 인터럽트가 발생했을 때와 동일한 상태에서 인터럽트 된 프로세스를 계속 실행해야합니다. 인터럽트 처리기는 특정 프로그램에 연결되는 대신 고정 된 메모리 영역에 위치한다는 점에서 일반적인 절차와 다릅니다.
예외- 특정 조건에서 발생하는 특수한 유형의 프로 시저 호출입니다. 중요하지만 드물게 발생합니다. 예외를 일으킬 수있는 가장 일반적인 조건은 부동 소수점 연산, 정수 연산 중 오버플로, 보안 위반, opcode, 스택 오버플로, 존재하지 않는 UHF 시작 시도, 홀수 셀에서 단어 호출 시도시 유효 숫자 오버플로 및 실종입니다 주소, 0으로 나눈 값. 결과가 허용 범위 내에 있으면 예외가 발생하지 않습니다. 이러한 종류의 중단은 프로그램 자체 및 감지 된 하드웨어 또는 펌웨어로 인한 일부 예외적 인 조건으로 인해 발생한다는 점에 유의해야합니다. 예외는 차례로 실패, 함정 및 비상 정지.
실패 이것은 예외이며,이 예외의 원인이 된 명령 앞에있는 명령의 경계에서 발행되는 메시지입니다. 오류를보고 한 후 컴퓨터 상태가 복원되어 명령을 다시 시작할 수 있습니다. 실패의 예는 존재하지 않는 공습에 호소하는 것입니다.
함정 - 이것은 예외이며,이 예외가 발견 된 명령 바로 다음에있는 명령의 경계에서 발행되는 메시지입니다. 예를 들어, 정수 처리시 오버 플로우가 발생합니다.
비상 종료 - 예외를 일으킨 명령을 정확하게 판별하거나이 예외가 발생한 프로그램을 다시 시작할 수 없도록하는 예외입니다. 비정상 종료는 심각한 오류를보고하는 데 사용됩니다. 시스템 오류는 하드웨어 오류, 충돌 또는 유효하지 않은 값입니다.
중단 - 이것은 프로그램 자체가 아닌 제어 흐름의 변화이지만, 일반적으로 입출력 프로세스와 관련된 일부 비동기 이벤트에 의해 발생합니다. 인터럽트를 통해 프로세서와 독립적으로 I / O 작업을 수행 할 수 있습니다. 마이크로 프로세서의 속도가 에어 블라스트의 속도보다 높기 때문에 프로세서는 연결된 주변 장치의 상태를 지속적으로 모니터링하는 대신 다른 프로그램을 실행하거나 다른 기능을 수행 할 수 있습니다. UVV가 프로세서에 의한 유지 보수를 요구할 때, 프로세서가 현재 프로그램의 실행을 방해 할 수있는 적절한 요청 (신호)을 형성함으로써이를 알려줍니다. 인터럽트 제어는 프로세서에 연결되어 있으며 구조적으로 프로세서의 일부인 인터럽트 컨트롤러에 의해 제어됩니다.
예외와 인터럽트의 차이점은 예외가 프로그램과 동기적이고 인터럽트가 비동기라는 점입니다. 예외는 프로그램에 의해 직접적으로 발생하며 간접은 간접적입니다. 동일한 입력 데이터로 프로그램을 반복적으로 다시 시작하면 동일한 프로그램 위치에서 매번 예외가 발생하지만 인터럽트는 발생하지 않습니다.
인터럽트 신호의 존재는 실행중인 프로그램의 인터럽트를 유발할 필요가 없으며, 프로세서는 인터럽트 보호 시스템을 가질 수 있습니다 : 인터럽트 시스템을 비활성화하거나 개별 인터럽트 신호를 금지하거나 마스킹합니다. 이러한 도구의 소프트웨어 관리를 통해 운영 체제는 인터럽트 신호 처리를 조절할 수 있습니다. 프로세서는 인터럽트가 도착하자 마자 즉시 처리 할 수 있으며, 처리를 얼마 동안 연기하고 완전히 무시할 수 있습니다. 예를 들어, TF 추적 플래그가 1로 설정된 경우 프로세서는 하나의 프로그램 명령을 실행 한 다음 유형 1 인터럽트를 생성합니다. 즉, 프로그램이 단계적으로 실행됩니다. IF 인터럽트 플래그가 지워지면 프로세서는 외부 인터럽트에 응답하지 않습니다 (마스크 불가능). 특정 유형의 인터럽트를 마스크하기 위해 마스크 레지스터가 사용됩니다. 이것은 CLI (인터럽트 사용 불가능) 및 STI (인터럽트 사용 가능) 명령에 의해 제어됩니다.
각 개별 인터럽트 유형 또는 예외는 0에서 255 사이의 식별 번호와 해당 처리기와 연관됩니다. 예외 및 마스크되지 않은 인터럽트는 0에서 31 사이의 간격에서 할당 된 숫자이며 마스크 된 인터럽트는 32에서 255 사이입니다. 현재 모든 값이 프로세서에서 사용되는 것은 아닙니다. 할당되지 않은 번호는 추후 사용을 위해 예약되어 있습니다. 해당 핸들러의 인터럽트, 예외 및 주소 (벡터) 수는 특수 테이블에 저장됩니다. 인터럽트 벡터 테이블메모리에 있습니다. 인터럽트 또는 예외가 발생하면 인터럽트 벡터 테이블의 해당 주소는 해당 인터럽트 또는 예외 처리 절차의 주소로 결정됩니다. 호출이 인터럽트 또는 예외 처리기에서 생성되고 반환되는 방법을 자세히 살펴보십시오.
인터럽트 및 예외를 처리하는 메커니즘은 여러면에서 유사하지만 처리기에서 반환하는 것과 관련된 몇 가지 차이점이 있습니다. 인터럽트 처리 메커니즘에는 다음 단계가 포함됩니다.
1) 중단의 사실 수립.
2) PSW 플래그 레지스터, IP 명령 카운터, CS 세그먼트 레지스터의 내용에 의해 결정되는 스택에서 인터럽트 된 프로세스의 상태를 암기한다. 필요하다면, 인터럽트 절차에서 사용되어 결과적으로 변경 될 레지스터의 내용도 기억됩니다. 예외 및 인터럽트의 일부 유형은 예외의 원인을 진단하기 위해 스택에 오류 코드를 푸시합니다.
3) 인터럽트 벡터 테이블의 인터럽트 번호로 인터럽트 처리 프로 시저의 주소를 결정하고 CS 및 IP 레지스터에 주소를로드하여이 처리기로 전환합니다.
4) 인터럽트 처리. 인터럽트 처리 루틴은 명령을 실행합니다.
5) 중단 된 프로그램의 상태를 복원하십시오. 인터럽트 처리 절차가 성공적으로 완료되면 IRET 명령에 도달하면 (이 명령으로 인터럽트 핸들러가 완료 됨) 레지스터에 저장된 이전 내용이 복원되고 (이전 상태), 및 반송 주소 - CS 및 IP 레지스터의 값.
6) 중단 된 프로그램으로 돌아갑니다. 반환 주소에 따라 인터럽트 된 프로세스로 전환됩니다. 인터럽트가 발생하기 전에 실행 된 명령 다음의 명령으로 복귀해야합니다. 이 속성을 사용하는 인터럽트 처리 프로 시저가 호출됩니다. 투명하다.
실패가 발생하면 리턴 주소는 실패의 원인이 된 명령의 주소이므로이 명령을 다시 실행하여 재실행을 시도합니다 (재시작). 트랩 처리는 인터럽트 처리와 유사합니다. 비상 종료의 경우, 계산 프로세스는이 예외가 발생한 프로그램의 초기 상태를 복원 할 가능성없이 종료됩니다.
인터럽트 신호는 임의의 시점에서 발생하기 때문에 인터럽트 시간에 순차적으로 처리 할 수있는 인터럽트 신호가 여러 개있을 수 있습니다. 이를 위해 인터럽트에 우선 순위가 할당됩니다. 우선 순위가 높은 인터럽트 서비스 분야가 있습니다. 우선 순위가 높은 인터럽트는 우선 순위가 낮은 인터럽트를 인터럽트하고, 2) 우선 순위가 낮은 인터럽트가 처리 된 후 우선 순위가 더 높은 인터럽트가 처리됩니다.
다음 장에서는 VM 메모리 구성과 관련된 문제를 살펴 보겠습니다.
펜티엄 프로세서의 아키텍처 기능.
/ 2 /에 따라 Pentium 마이크로 프로세서 (1993)는 개인용 컴퓨터에서 최초로 수퍼 스칼라 프로세서입니다. 여기에는 다음 기능 블록이 포함됩니다.
1) ShI 블록;
2) 정수 계산을위한 명령의 실행을위한 두 개의 5 단계 파이프 라인 (U 및 V)
3) 각각 8KB의 L1 레벨의 명령어 및 데이터 캐시를 분리한다.
4) 컨베이어로 구성된 부동 소수점 FPU 컴퓨팅 유닛.
5) 분기 예측 유닛;
6) 메모리 관리 장치.
대부분의 명령은 한 번의 조치로 실행됩니다. 복잡한 명령을 실행하는 경우 복잡한 명령의 펌웨어 ROM에서 확장 된 마이크로 코드가 사용됩니다.
펜티엄 컨베이어는 전통적인 5 단계 명령 실행 (샘플링, 디코딩 작업, 피연산자 읽기, 결과 기록)을 구현합니다. 부동 소수점 연산을 계산할 때 X1 - 고급 복잡도 형식의 데이터 변환, X2 - FPU 명령 실행, WF - 결과 반올림 및 FPU 레지스터 파일에 쓰는 세 단계가 추가됩니다. 파이프 라인 U는 정수 명령과 부동 소수점 명령을 모두 실행할 수 있습니다. 동시에 부동 소수점 연산 명령은 정수 명령과 함께 실행할 수 없습니다. 또한 파이프 라인 U는 산술, 논리, 순환 시프트, 곱셈 및 나눗셈 연산을 수행 할 때 사용되는 다중 비트 시프터를 포함합니다. 파이프 라인 V는 정수 명령 만 실행합니다.
독립 캐시를 사용하면 캐시에 동시 액세스 할 수 있습니다. 명령 캐시는 256 비트 버스가있는 프리 페치 버퍼와 연관됩니다. 캐시에서 선택된 명령이 누락 된 경우 필요한 명령이 주 메모리에서 읽히고 명령 캐시에 동시에 쓰는 동시에 프리 페치 버퍼에로드됩니다.
데이터 캐시는 두 개의 32 비트 버스를 사용하여 U 및 V 파이프 라인에 연결되므로 각 파이프 라인의 측면에서 동시에 액세스 할 수 있습니다.
메모리 제어 유닛은 메모리 셀의 물리적 어드레스의 2 단계 형성을 세그먼트 내에서 수행 한 후 페이지 내에서 수행한다. 특수 하드웨어는 외부 캐시의 작동을 제어하는 데 사용됩니다.
아키텍처 혁신 Pentium은 시스템을 저전력 소모 상태로 만들기 위해 설계된 특수 시스템 관리 모드 (SMM - 시스템 관리 모드)입니다. 이 모드는 응용 프로그램에서 사용할 수 없으며 프로세서 칩의 ROM에서 프로그램에 의해 제어됩니다. SMM 모드에서 Pentium은 다른 모드 인 메모리 공간과 분리 된 다른 모드를 사용합니다.
SI 블록은 64 비트 데이터 버스와 32 비트 주소 버스 및 제어 버스를 포함하는 시스템 버스를 통해 프로세서를 다른 장치에 연결합니다. 펜티엄 프로세서는 최대 4GB의 실제 메모리가있는 시스템을 지원합니다.
펜티엄 프로세서의 개발은 주로 생산 기술의 향상, 명령어 시스템의 확장, 전환 예측 알고리즘의 개선, 파이프 라인로드 방법 및 캐시 메모리와 상호 작용하는 방법과 관련되어 있습니다.
이전 펜티엄 모델의 펜티엄 6 (펜티엄 프로, 펜티엄 II, 펜티엄 III) 및 펜티엄 IV (펜티엄 III) 프로세서의 특징은 멀티 프로세싱 데이터의 원리를 구현하는 다른 접근법입니다. 상당한 하드웨어 비용이 필요한 명령 실행 파이프 라인 수를 늘리는 대신 많은 수의 실행 단위가있는 파이프 라인 하나가 사용된다는 사실에 있습니다. 예를 들어, Pentium IV의 명령 처리는 비교적 독립적 인 3 개의 컨베이어로 나눌 수있는 20 단계 컨베이어 (하이퍼 컨베이어)로 수행됩니다.
1) 메모리로부터 명령의 선택을 제공하고 내부 RISC 명령으로 디코딩하며 잘못된 데이터 및 자원 관계를 제거하는 순서 처리의 입력 처리 파이프 라인.
2) 컨베이어 랜덤 프로세싱 : 명령의 실제 실행을 구현합니다. 프로세싱이 혼란 스러울 때 수퍼 스칼라 프로세서의 파이프 라인이 더 집중적으로로드됩니다. 프로그램의 올바른 실행을 보장하려면 차례로 실행 된 명령의 결과를 소스 프로그램에서 수행하는 순서와 동일한 순서로 대상 주소에 기록해야합니다. 이 작업은 특수 프로세서 장치 (차례로 수행 된 결과에 대한 임시 저장 장치)에 의해 수행됩니다.
3) 명령 실행의 컨베이어 출력. 프로그램에 의해 지정된 방식으로 프로세서 및 메모리의 아키텍처 레지스터에 결과를 기록합니다.
펜티엄 IV 하이퍼 컨베이어의 효율적인 작동은 프로그램 코드에 의해 제공되지 않은 동작이 컨베이어의 연속 적재를 위해 수행 될 때 명령의 추측 실행에 의해 보장됩니다.
분기 예측 블록에서 분기 예측 알고리즘은 이전 모델의 Pentium 프로세서보다 더 복잡합니다. 전환 명령의 어드레스 및 상세한 히스토리를 갖는 브랜치 마크들은 브랜치 예측 블록의 버퍼 (4KB 크기)에 저장된다.
펜티엄 IV 프로세서와 초기 모델 간의 또 다른 중요한 차이점은 구조에서 추적 캐시 명령을 대신 사용한다는 것입니다. 산책로 - 이것은 원래 프로그램의 하나 또는 여러 가지 브랜치에 속하는 x86 명령이 디코딩 된 일련의 마이크로 명령어입니다. 최대 12KB의 마이크로 명령어를 캐시에 둘 수 있습니다. 트랙에는 절대로 사용하지 않을 명령이 없습니다. 샘플링 장치와 함께 트레이스 캐시는 전처리 장치를 형성합니다.
하이퍼 컨베이어, 트레이스 캐시 및보다 효율적인 실행 코어를 사용하여 Pentium IV에서 상당한 성능 향상을 달성 할 수있었습니다.
펜티엄 프로세서의 소프트웨어 모델.
고려 된 펜티엄 마이크로 프로세서의 통일 특성은 아키텍처에 큰 차이가 있음에도 불구하고 모두 동일한 소프트웨어 모델을 가지고 있다는 것입니다. 프로세서의 모든 소프트웨어 액세스 가능 레지스터의 전체가 그것을 형성합니다 프로그래밍 모델 / 2 /. 프로그래머가 사용할 수있는 프로세서 리소스를 보여줍니다.
소프트웨어 모델은 응용 프로그램과 시스템으로 구분됩니다. 조성 응용 소프트웨어 모델 (PPM) 프로세서에는 응용 프로그램 프로그래머가 사용할 수있는 완전한 레지스터 세트가 포함되어 있습니다. 기억 조직의 특징 및 이용 가능한 어드레싱 방법; 데이터 유형 및 명령. 시스템 소프트웨어 모델 프로세서 (PMD)는 내장 된 보호 및 멀티 태스킹 메커니즘에 대한 액세스가 제공되는 소프트웨어 액세스 가능 시스템 리소스를 결합합니다. SPM 프로세서는 주로 시스템 프로그래머가 사용합니다.
현재 존재하는 모든 마이크로 프로세서는 4 개의 그룹으로 나눌 수 있습니다 :CISC (복잡한지시 사항세트명령) - 지시의 가득 차있는 세트에 -;RISC (축소지시 사항세트명령) - 절단 된 명령 세트;브리 (매우길다정수단어) - 아주 큰 명령 어로;기타 (최소지시 사항세트명령) - 최소한의 지침으로
프로세서 유형의 주요 담당자CISC - 회사 MP 인텔 표 3.2.
MP 유형 RISC 프로그램에서 가장 자주 사용되는 명령의 축약 된 집합을 포함합니다. 복잡한 명령을 실행할 필요가있을 때, MP는 간단한 명령에서 그것을 수집합니다. 이 MP의 특징은 모든 간단한 명령이 한 머신 클럭 사이클과 동일한 시간 동안 실행된다는 것입니다.
참고 사항
RISC 프로세서는 IBM (Power PC), DEC (Alpha), HP (PA), Sun (Ultra SPARC) 및 기타 여러 회사에서 제조합니다.
가장 유명한 대표자RISC 프로세서 - MTPowerPC (실적최적화 됨와향상된PC) 회사의 데스크톱 및 전문 솔루션에 사용애플그러나 최근 Yabloko는 아키텍처로의 전환을 발표했습니다.인텔. MP RISC 고속으로 특징 지어 지지만 프로세서와 프로그래밍 방식으로 호환되지 않는CISC. 따라서 개발 된 응용 프로그램을 실행하려면IbmPC 형식 컴퓨터의 호환 컴퓨터애플매킨토시 효율성을 크게 떨어 뜨리는 "에뮬레이터"가 필요합니다.
표 3.2. 인텔의 마이크로 프로세서 특성
|
모델 |
방전 - 데이터 가용성 / 주소 (비트) |
시계 주파수 (MHz) |
주소 공간 (바이트) |
작곡 팀 |
통합 / 공정 기술의 정도 |
긴장감 전원 공급 장치 (V) |
제조 년도 |
|
4004 |
4 /4 |
0,108 |
2,300 / 10 미크론 |
1971 |
|||
|
8080 |
8 /8 |
64K |
10,000 / 6 미크론 |
1974 |
|||
|
8086 |
16 /16 |
4.77 및 8 |
70,000 / 3 미크론 |
1979 |
|||
|
8088 |
8 , 16 /16 |
4.77 및 8 |
70,000 / 3 미크론 |
1978 |
|||
|
80186 |
16/20 |
8 및 10 |
140 000 |
1981 |
|||
|
80286 |
16/24 |
8-20 |
1600 만 |
180 000/ 1.5 미크론 |
1982 |
||
|
80386 |
32/32 |
16-50 |
4G |
275,000 / 1 미크론 |
1985 |
||
|
80486 |
32/23 |
25-100 |
120 만 / 1 미크론 |
1989 |
|||
|
펜티엄 |
64/32 |
60-233 |
330 만 / 0.5 및 0.35 미크론 |
1993 |
|||
|
펜티엄 프로 |
64/32 |
150-200 |
550 만 / 0.5 및 0.35 미크론 |
1995 |
|||
|
펜티엄 MMX |
64/36 |
166-233 |
57 (MMX) |
5 백만 / 0.35 미크론 |
1997 |
||
|
펜티엄 II (Katmai 코어) |
64/36 |
233-600 |
MMX + (MMX2) |
750 만 / 0.25 미크론 |
1997 |
||
|
셀러론 (멘 도시 노 코어) |
64/32 |
300-800 |
MMX2 |
19 백만 / 0.25 및 0.22 미크론 |
1998 |
||
|
펜티엄 III (Coppermine) |
64/36 |
500-1000 |
MMX + 70 |
2800 만 / 0.18 마이크론 |
1,65 |
1999 |
|
|
펜티엄 III 제온 |
64/36 |
500-1000 |
MMX2 |
3 천만 / 0.18 및 0.13 마이크론 |
1,65 |
1999 |
|
|
펜티엄 4 (Willamette) |
64/36 |
1000-3500 |
64G |
MMX 2 + 144 |
4200 만 / 0.13 미크론 |
1,1-1,85 |
2000 |
MP 유형 브리 수퍼 스칼라와는 달리CISC 프로세서는 실질적으로보다 단순한 회로 구현을 가지며 소프트웨어에 의존합니다. 프로그래머는 내부 액세스 권한이 없습니다.브리따라서 모든 응용 프로그램과 운영 체제는 특별한 저수준 소프트웨어를 기반으로 실행됩니다 (코드모핑) 방송 지침CISC프로세서 팀브리. 단순화 된 하드웨어브리 MP의 크기를 크게 줄이고 발열 및 전력 소모를 줄일 수 있습니다.
브리 회사에서 생산 한 프로세서트랜스 메타 - 브랜드 이름 아래 MT크루소첫 번째 MP 브리 ~로부터 인텔 핵심에 머시 전체 지시 사항을 사용했다.IA-64,이 기술은EPIC (명시 적으로평행선지시 사항컴퓨팅 - 지시의 명백한 병렬성을 가진 계산).
참고 사항
~까지 VLIW 프로세서는 2002 년 Elbrus 2000-E 2k MP의 출현으로 인해 러시아 회사 인 Elbrus가 개발 한 것입니다. 그것은 작은 크기 (동전 1 루블 뒤에 완전히 숨겨져 있음)를 가졌습니다. 현재 회사의 모든 발전은 물론 직원들도 인텔의 이익을 위해 일하고 있습니다.
과학적 및 기술적 계산의 중요한 부분은 스칼라 값 대신 벡터를 사용하여 계산을 크게 단순화하는 것입니다. 대규모 과학 프로그램을 계산하는 조직의 두 가지 모델을 고려하십시오.대용량 병렬 프로세서 (배열 프로세서 ) 및 벡터 프로세서 (벡터 프로세서 ). 대용량 병렬 프로세서는 서로 다른 데이터 세트로 동일한 계산을 수행하는 많은 수의 유사 프로세서로 구성됩니다. 격자를 나타내는 여러 섹터로 구성된 구조입니다.NxN 프로세서 / 메모리 소자. 각 부문에는 자체 제어 장치가 있습니다.
참고 사항
세계 최초의 대규모 병렬 프로세서 인 ILLIAC IV (일리노이 대)는 8x8 프로세서 / 메모리 요소 (1 섹터, 4 섹터 구축 예정)의 그리드를 가지고 있으며 초당 5 천만 개의 연산 속도를가집니다. 벡터 프로세서는 유명한 크레이 리서치 (Cray Research)를 출시했으며, 창립자는 시모어 크레이 (Seymour Cray)였습니다.
차이점 벡터 CPU 모든 가산 연산이 컨베이어 구조를 갖는 단일 가산 블록에서 수행된다는 사실에있다. 이 프로세서에는벡터 레지스터 일련의 표준 레지스터로 구성됩니다. 이러한 레지스터는 하나의 명령을 사용하여 메모리에서 순차적으로로드됩니다. 추가 팀은 두 개의 벡터 요소를 쌍으로 추가하여 벡터 요소가 두 벡터 레지스터에서 벡터 구조의 합계 장치로로드합니다. 결과적으로 벡터가 적산계에서 나옵니다.
프로세서 설명 및 용도
정의 1
중앙 처리 장치 (CPU) - 프로그램에 의해 지정된 산술 및 논리 연산을 수행하고 계산 프로세스를 제어하며 모든 PC 장치의 작업을 조정하는 컴퓨터의 주요 구성 요소입니다.
프로세서가 강력할수록 PC의 성능은 빨라집니다.
참고
중앙 프로세서는 흔히 프로세서, CPU (Central Processing Unit) 또는 CPU (Central Processing Unit)라고도하며 크리스탈, 돌, 호스트 프로세서는 적습니다.
최신 프로세서는 마이크로 프로세서입니다.
마이크로 프로세서는 집적 회로 - 수십 억 개의 트랜지스터가있는 회로와 신호 전달을위한 채널이 포함 된 수 평방 밀리미터의 사각형 모양의 결정질 실리콘 박막. 크리스털 플레이트는 플라스틱 또는 세라믹 케이스에 넣고 PC 마더 보드에 연결하기 위해 금선으로 금속 핀에 연결합니다.
그림 1. Intel 4004 마이크로 프로세서 (1971)

그림 2. 마이크로 프로세서 Intel Pentium IV (2001). 왼쪽 상단보기, 오른쪽 하단보기
CPU는 프로그램을 자동으로 실행하도록 설계되었습니다.
프로세서 장치
CPU의 주요 구성 요소는 다음과 같습니다.
- 산술 논리 단위 (ALU)는 기본 수학 및 논리 연산을 수행합니다.
- 제어 장치 (CU)는 CPU의 구성 요소와 다른 장치와의 연결의 일관성을 결정합니다.
- 데이터 버스 및 어드레스 버스;
- 레지스터들현재 명령, 초기, 중간 및 최종 데이터 (ALU의 계산 결과)는 일시적으로 저장된다;
- 명령 카운터;
- 캐시 메모리 자주 사용되는 데이터 및 명령을 저장합니다. 메모리 캐싱은 RAM보다 훨씬 빠르기 때문에 크기가 클수록 CPU 속도가 빨라집니다.
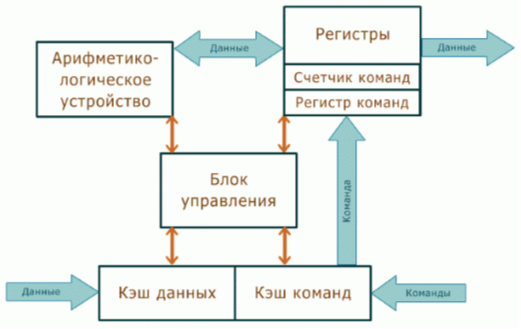
그림 3. 단순화 된 프로세서 회로
프로세서의 원리
CPU가 RAM에있는 프로그램을 실행 중입니다.
ALU는 데이터를 수신하고 지정된 연산을 수행하여 결과를 프리 레지스터 중 하나에 씁니다.
현재 명령은 특수 명령 레지스터에 있습니다. 현재 명령으로 작업 할 때 이른바 명령 카운터의 값이 증가하고 다음 명령을 가리 킵니다 (예외는 전환 명령 일뿐입니다).
명령은 조작의 레코드 (수행되어야하는), 초기 데이터의 셀 주소 W 결과로 구성됩니다. 명령에 지정된 주소에서 데이터를 가져 와서 일반 레지스터 (명령 레지스터가 아닌 의미로)에 배치하고 결과를 레지스터에 저장 한 다음 명령에 지정된 주소로 이동합니다.
CPU 기능
클럭 주파수는 CPU가 작동하는 빈도를 나타냅니다. $ 1 $ tact의 경우 몇 가지 작업이 수행됩니다. 주파수가 높을수록 PC의 속도가 빨라집니다. 최신 프로세서의 클록 주파수는 기가 헤르쯔 (GHz) 단위로 측정됩니다 : 1 달러당 $ 1GHz = 초당 1 억 달러의 클럭 사이클.
CPU의 성능을 향상시키기 위해 여러 개의 코어를 사용하기 시작했습니다. 각 코어는 실제로 별도의 프로세서입니다. 코어가 많을수록 PC의 성능이 향상됩니다.
프로세서는 데이터 버스, 주소 및 컨트롤을 통해 다른 장치 (예 : RAM)에 연결됩니다. 버스 폭은 8의 배수 (바이트를 다루기 때문에)이며 모델마다 다르며 데이터 버스와 주소 버스도 다릅니다.
데이터 버스 너비는 $ 1 $ 시간 ($ 1 $ 시계) 동안 전송할 수있는 정보의 양 (바이트 단위)을 나타냅니다. 주소 버스의 너비는 CPU가 사용할 수있는 최대 RAM 용량에 따라 달라집니다.
시스템 버스의 주파수에서 일정 기간 동안 전송되는 데이터의 양에 따라 달라집니다. 1 달러짜리 최신 PC의 경우 몇 비트를 전송할 수 있습니다. 시스템 버스 주파수와 동일한 버스 대역폭이 $ 1 $로 전송할 수있는 비트 수를 곱한 것도 중요합니다. 시스템 버스 주파수가 $ 100 $ MHz이고 $ 1 $ 클럭 속도가 $ 2 $ 비트 전송 된 경우 대역폭은 $ 200 $ Mbit / s입니다.
최신 PC의 용량은 초당 기가비트 (또는 수십 기가비트)로 계산됩니다. 숫자가 높을수록 좋습니다. CPU의 성능은 캐시 메모리의 양도 영향을받습니다.
CPU에 대한 데이터는 RAM에서 나옵니다. 메모리가 CPU보다 느리면 종종 유휴 상태가 될 수 있습니다. 이를 방지하려면 CPU와 RAM 간의 캐시가 RAM보다 빠릅니다. 그것은 버퍼로 작동합니다. RAM의 데이터는 캐시로 전송 된 다음 CPU로 전송됩니다. CPU가 다음 데이터를 필요로 할 때 캐시에 있으면 데이터를 가져오고 그렇지 않으면 RAM에 액세스합니다. 프로그램이 순차적으로 하나의 명령을 실행하면 하나의 명령이 실행될 때 다음 명령의 코드가 주 메모리에서 캐시로로드됩니다. 이렇게하면 작업 속도가 크게 빨라집니다. CPU 대기 시간이 감소하고 있습니다.
비고 1
캐시 메모리에는 세 가지 유형이 있습니다.
- $ 1 $ 수준의 캐시 메모리가 가장 빠르며 CPU 코어에 위치하므로 작습니다 ($ 8-128 $ KB).
- 캐시 메모리 $ 2 $ 수준은 CPU에는 있지만 커널에는 없습니다. RAM보다 빠르지 만 $ 1 $ 수준 캐시보다 느립니다. 크기는 $ 128 $ Kbytes에서 수 MB입니다.
- $ 3 $ 수준의 캐시는 RAM보다 빠르지 만 $ 2 $ 수준의 캐시는 느립니다.
CPU 및 그에 따라 컴퓨터의 속도는 이러한 유형의 메모리 양에 따라 달라집니다.
CPU는 $ DDR $, $ DDR2 $ 또는 $ DDR3 $과 같은 특정 유형의 RAM 만 지원할 수 있습니다. RAM이 빠를수록 CPU의 성능이 향상됩니다.
다음 특성은 CPU가 삽입되는 소켓 (소켓)입니다. CPU가 특정 유형의 소켓 용으로 설계된 경우에는 다른 유형의 소켓에 설치할 수 없습니다. 그 사이에, 어미판에 CPU를위한 단지 1 개의 소켓이 있고이 가공업 자의 유형과 일치해야한다.
프로세서 유형
PC 용 CPU를 제조하는 주요 회사는 Intel입니다. 최초의 PC 프로세서는 $ 8086 $ 프로세서였습니다. 다음 모델은 시간이 지남에 따라 $ 80286 $, $ 80386 $이었고 $ 80 $ 수치는 낮아졌고 CPU는 $ 286 $, $ 386 $ 등 세 자리 숫자로 불 렸습니다. 세대 프로세서는 종종 $ x86 $ 제품군이라고합니다. Alpha, Power PC 및 다른 제품군과 같은 다른 프로세서 모델도 있으며 CPU 제조업체는 AMD, Cyrix, IBM, Texas Instruments입니다.
프로세서의 이름은 종종 코어의 수를 의미하는 문자 $ X2 $, $ X3 $, $ X4 $에서 찾을 수 있습니다. 예를 들어, Phenom $ X3 $ $ 8600 $이라는 기호는 $ X3 $ 기호가 세 개의 코어가 있음을 나타냅니다.
따라서 CPU의 주요 유형은 $ 8086 $, $ 80286 $, $ 80386 $, $ 80486 $, Pentium, Pentium Pro, Pentium MMX, Pentium II, Pentium III 및 Pentium IV입니다. Celeron은 펜티엄 프로세서의 차용 버전입니다. 이름 뒤에 일반적으로 CPU 클럭 속도가 표시됩니다. 예를 들어, Celeron $ 450 $는 Celeron CPU 유형을 나타내며 클럭 주파수는 $ 450 $ MHz입니다.
프로세서는 프로세서에 해당하는 시스템 버스 주파수로 마더 보드에 설치해야합니다.
CPU의 최신 모델에서는, 과열 보호 메커니즘이 구현된다. 온도가 임계 온도 이상으로 상승하면 CPU는 더 적은 전력이 소비되는 낮은 클럭 주파수로 전환합니다.
정의 2
컴퓨팅 시스템에 여러 개의 병렬 프로세서가있는 경우 이러한 시스템을 호출합니다 다중 처리 .
원래의 IBM PC와 IBM PC XT는 Intel-8088 마이크로 프로세서를 사용했습니다. 80 년대 초, 이러한 마이크로 프로세서는 클럭 주파수 4.77MHz로 제조되었으며, 그 다음 클럭 주파수가 8, 10 및 12MHz 인 모델이 생성되었습니다. 향상된 성능 (클럭 주파수)을 갖춘 모델을 TURBO-XT라고도합니다. 이제 Intel-8088과 같은 마이크로 프로세서는 소량 생산되고 컴퓨터가 아닌 다양한 특수 장치에서 사용됩니다.
IBM PC AT 모델은보다 강력한 Intel-80286 마이크로 프로세서를 사용하며 성능은 IBM PC XT보다 약 4-5 배 높습니다. IBM PC AT의 원래 버전은 클록 주파수가 12 ~ 25 MHz 인 마이크로 프로세서에서 작동했습니다. 즉, 2 ~ 3 배 더 빠르게 작동합니다. Intel-80286 마이크로 프로세서는 Intel-8088보다 약간 더 많은 기능을 가지고 있지만 이러한 추가 기능은 거의 사용되지 않으므로 AT에서 실행되는 대부분의 프로그램은 XT에서 작동합니다. 현재 Intel-80286과 같은 마이크로 프로세서는 폐기되었으며 컴퓨터 용으로 제조되지 않았습니다.
1988-1991 년 제작 된 대부분의 컴퓨터는 1985 년 Intel에서 개발 한 충분히 강력한 Intel-80386 마이크로 프로세서를 기반으로했습니다.이 마이크로 프로세서 (80386DX라고도 함)는 80286이 동일한 클록 주파수로 작동하는 것보다 2 배 빠르게 작동합니다. 일반적인 80386DX 클럭 주파수 범위는 25 ~ 40MHz입니다. 또한 Intel은 Intel-80386SX 마이크로 프로세서를 개발했는데 Intel-80286보다 약간 크지 만 Intel-80386과 동일한 기능을 제공합니다 (빠른 동작은 약 1, 2-2 배).
Intel-80386 마이크로 프로세서는 Intel-80286보다 빠르게 작동 할뿐 아니라 훨씬 더 많은 기능을 갖추고 있습니다. 특히 32 비트 연산을위한 강력한 도구가 포함되어 있습니다 (16 비트 80286 및 8088과 반대).
이러한 도구는 소프트웨어 제조업체에서 활발하게 사용되고 있으므로 현재 출시 된 많은 프로그램은 Intel-80386 모델 이상의 마이크로 프로세서가 장착 된 컴퓨터에서만 사용하도록되어 있습니다.
마이크로 프로세서 인 Intel-80386을 만들 때 인텔은 가장 진보 된 마이크로 프로세서로 간주하여 대부분의 작업에 충분한 성능을 제공했습니다. 그러나 1990-1991 년 이후로 가장 널리 퍼졌다. Microsoft의 Windows 운영 체제 쉘은 컴퓨터 컴퓨팅 리소스에 대한 요구 사항을 극적으로 증가 시켰으며 대부분의 경우 Intel-80386 마이크로 프로세서가 장착 된 컴퓨터에서 Windows 프로그램 작업이 너무 느립니다. 따라서 1991-1992 년. 대부분의 컴퓨터 제조업체는보다 강력한 인텔 -80486 마이크로 프로세서 (또는 80486DX)를 사용하도록 재 지정했습니다. 이 마이크로 프로세서는 Intel-80386과 거의 다르지 않지만 성능은 2-3 배 높습니다. 그 기능 중에는 내장 된 캐시 메모리 및 내장 된 수치 연산 보조 프로세서가 있어야합니다. 인텔은 또한 저렴하면서도 생산성이 떨어지는 -80486SX 버전과 더 비싸고 빠른 옵션 인 -80486DX2 및 DX4를 개발했습니다. 80486의 클럭 주파수는 일반적으로 25-50 MHz, 80486DX2-50-60 MHz 및 DX4- 100 MHz의 범위입니다.
1993 년 인텔은 새로운 펜티엄 마이크로 프로세서 (이전에 80586으로 발표 됨)를 출시했습니다. 이 마이크로 프로세서는 특히 실제 수치를 계산할 때 더욱 강력합니다. Intel-80486과 마찬가지로 내장 된 수치 연산 보조 프로세서가 포함되어 있으며 Intel-80486보다 훨씬 효율적입니다. 펜티엄의 성능을 향상시키기 위해 더 빠르고 넓은 데이터 전송 버스 (데이터 버스), 많은 양의 내부 캐시 메모리, 동시에 두 개의 명령을 실행할 수있는 기능 등이 개선되었습니다. 233 MHz. 동시에 펜티엄 마이크로 프로세서는 클록 주파수가 동일한 80486 유형 마이크로 프로세서보다 5 배 빠른 속도로 작동하며 실수에 대한 집중적 인 계산이 필요한 작업의 경우 3-4 배 빠릅니다.
1996 년 말에서 1997 년 초, 인텔은 향상된 펜티엄 MMX 프로세서 (MMX - 멀티미디어 확장)를 출시했습니다. 외견 상으로 전임자와 조금 다르긴하지만 팀의 아키텍처는 극적인 변화를 겪어 왔습니다. 칩의 명령어 세트에는 57 개의 새로운 명령어가 등장했다. 오디오, 비디오, 그래픽 및 통신 데이터 처리와 관련된 작업을 수행하도록 설계되었습니다.
기존 펜티엄 케이스의 새로운 기능을 수용하기 위해 회사는 몇 가지 타협점을 찾아야했습니다. 즉, MMX가있는 프로세서는 MMX 명령과 부동 소수점 숫자와 같이 MMX 명령어와 부동 소수점 연산을 동시에 실행할 수 없으며 이들은 단독으로 사용됩니다 내장 된 보조 프로세서의 동일한 레지스터. 그리고 이것은 펜티엄 MMX와 기존 소프트웨어의 완벽한 호환성을 유지하기 위해 수행됩니다. 코 프로세서를 사용하는 프로그램이 거의 없기 때문에 큰 문제는 아닙니다. 그러나 프로세서가 부동 소수점과 MMX 연산을 자주 전환해야하는 응용 프로그램이있는 경우에는 동일한 클럭 주파수를 사용하는 일반 프로세서보다 느리게 MMX 프로세서에서 실행됩니다.
인텔은 1997 년 5 월 7 일 공식적으로 펜티엄 II 프로세서를 발표했습니다. 주된 소식은 펜티엄 II가 기존 펜티엄 마더 보드와 호환되지 않는다는 것입니다. 새 프로세서는 S.E.C- 카트리지 (단일 에지 접점)에 장착됩니다. 완전히 밀폐 된 카트리지 하우징은 구성 요소를 보호하고 방열 판을 사용하면 수동 또는 능동 방열판으로 모든 방열기를 사용할 수 있습니다. 이로 인해 클럭 주파수가 233MHz 인 모델의 발열량은 38.2W를 넘지 않습니다 (비교를 위해 펜티엄 200MHz는 37.9W를 할당합니다). S.E.C. 카트리지는 인텔이 컴퓨터 구성 폼 팩터의 새로운 기술 표준으로 제안한 슬롯 1에 삽입됩니다.
1999 년 1 월 인텔은 공식적으로 PC 펜티엄 III 용 마이크로 프로세서를 공개했다. 회사 대표 인 세스 워커 (Seth Walker)에 따르면 펜티엄 III는 클록 주파수 (최초의 프로세서 모델은 450MHz 및 500MHz에서 작동), 그래픽 처리, 인터넷 작업의 속도 및 신뢰성을 포함하여 여러 가지면에서이 기술을 발전시켜야합니다. 펜티엄 III 제품군의 추가 개발 계획은 0.25 μm에서 0.18 μm의 기술 표준 (해당 마이크로 프로세서의 실제 이름은 Coppermine)에서 전환을 제공합니다. 0.25 미크론에서 0.18 미크론으로 전환하면 성능이 향상되고 전력 소비가 감소합니다. 이것은 크리스탈의 속도를 600MHz 이상으로 끌어 올릴 수 있습니다. 첫 번째 0.25 마이크론 펜티엄 III 프로세서의 클럭 속도는 450 및 500MHz입니다. 새로운 지침이 프로세서에 추가되었습니다. 이 명령 세트, 코드 명 Katmai New Instructions는 그래픽 처리 성능을 향상시키는 것을 목표로합니다. 또한 비디오, 오디오, 음성 인식 및 기타 유사한 기술의 적용 속도를 높일 수 있습니다. 2001 년 3 월, Intel은 900 MHz Xeon 프로세서를 출시했습니다. Pentium III 제품군의 마지막 멤버가되었습니다. 이 프로세서에는 2MB 캐시가 장착되어있어 성능이 향상됩니다.
2000 년 11 월 인텔은 펜티엄 4 마이크로 프로세서 출시 계획을 확인하고 2001 년 말 펜티엄 III에서 펜티엄 4로 대용량 데스크톱 PC를 옮길 계획을 발표했다. 펜티엄 4 프로세서는 인텔 NetBurst 마이크로 아키텍처를 기반으로합니다. 이것은 P6 마이크로 아키텍처를 갖춘 펜티엄 프로 프로세서가 1995 년에 출시 된 이래로 지난 5 년간 회사에서 개발 한 데스크톱 프로세서의 근본적으로 새로운 마이크로 아키텍처입니다. NetBurst의 아키텍처는 여러 새로운 기술을 사용합니다 : 하이퍼 파이프 라인 기술 (하이퍼 파이프 라인 기술)은 펜티엄 III보다 두 배 높은 파이프 라인 깊이를가집니다. 메인 코어의 주파수에 비해 클럭 주파수를 두 배로하여 정수 데이터로 작업 할 때 성능을 향상시키는 신속 실행 (Rapid Execution Engine)의 핵심. 이미 "디코딩 된"명령을 저장하는 실행 캐시 (Execution Trace Cache) 이렇게하면 다시 실행 가능한 코드 섹션을 분석 할 때의 지연이 제거됩니다.
펜티엄 4 프로세서에는 칩 당 4 천 2 백만 개의 트랜지스터가 포함되어 있으며 256KB 캐시가 장착되어 있으며 부동 소수점 데이터 블록의 처리를 가속화하는 소위 스트림 SIMD 확장 2 (SSE2)라는 144 개의 새로운 명령어가 있습니다. 펜티엄 4를 기반으로 한 플랫폼의 기초로 인텔 850 칩셋이 사용되고 있으며,이 칩셋은 현재 새 프로세서 용으로 설계된 유일한 칩셋입니다. 이 칩셋은 각 채널 당 1.6GB / s의 대역폭과 400MHz의 클록 주파수 및 최대 3.2GB / s의 대역폭을 갖춘 시스템 버스 인 듀얼 채널 Rambus Direct RAM (RDRAM)을 지원합니다. 사실, 시스템 버스 클록 주파수는 100MHz이며, 클록 당 4 번의 연산이 수행됩니다 (AGP 4x에서도 유사한 솔루션이 사용됩니다). 또한 인텔은 새로운 칩셋을 기반으로 한 최초의 ATX D850GB 데스크탑 보드를 발표했습니다. 현재 펜티엄 4의 1.4-, 1.5 및 1.7-GHz 버전이 생산되고 있으며 0.18 미크론 기술을 사용하여 생산됩니다.
선도적 인 분석가에 따르면 2001 년에 마이크로 칩 제조사는 2GHz 전환을 시도 할 것입니다. 폴리머 필름 코팅 및 초소형 화를 포함한 반도체 칩 생산을위한 새로운 기술은 제조업체가 2GHz 라인을 통과 할 수있게합니다.
마이크로 프로세서의 구조.
마이크로 프로세서는 정보 처리 및 제어에 필요한 모든 도구를 포함하여 하나 이상의 소프트웨어 제어 LSI로 구성된 반도체 장치로, 메모리 장치 및 입출력 정보와 함께 작동하도록 설계되었습니다.
마이크로 프로세서는 세 개의 주요 블록으로 구성됩니다.
산술 논리
레지스터 블록
제어 장치
산술 논리 장치 (ALU) - 모든 산술 및 논리 데이터 변환을 수행합니다.
제어 장치는 현재 명령의 내용에 따라 장치, 블록, 전자 구성 요소 및 회로의 작동을 활성화하는 컴퓨터의 전자 장치입니다.
Register는 하나의 데이터를 이진 코드로 저장하도록 설계된 일련의 트리거 형식의 메모리 셀입니다.
레지스터의 비트 수는 마이크로 프로세서의 디지트 용량에 의해 결정됩니다
범용 레지스터 - 수퍼 연산을 구성하고 계산 결과뿐 아니라 계산에 포함 된 피연산자를 저장하는 역할을합니다.
피연산자를 소스 데이터라고하며, 산술 유닛에서 다양한 동작이 수행됩니다.
명령 레지스터 - 현재 실행중인 명령을 저장합니다.
커맨드 카운터는 다음 커맨드가 저장된 메모리 셀의 어드레스를 나타내는 레지스터이다.
Stack (스택 메모리) - 정렬 된 데이터를 저장하기 위해 상호 연결된 레지스터 집합입니다. 첫 번째 스택은 마지막으로 스택에 저장되며, 그 반대의 경우도 마찬가지입니다.