ประวัติความเป็นมาของโปรเซสเซอร์ x86 สถาปัตยกรรม ARM แตกต่างจาก x86 อย่างไร
วันนี้จะไม่มีใครแปลกใจกับความจริงที่ว่ารูปถ่ายครอบครัวสุดโปรดที่จัดเก็บและป้องกันจากความประหลาดใจที่ร้ายกาจในรูปแบบเช่นน้ำจากเพื่อนบ้านที่โชคร้ายที่ชั้นบนสุดที่ลืมปิดก๊อกน้ำสามารถเป็นตัวแทนบางอย่างได้ ชุดตัวเลขที่เข้าใจยากและในขณะเดียวกันก็ยังคงเป็นรูปถ่ายครอบครัว คอมพิวเตอร์ที่บ้านกลายเป็นเรื่องธรรมดาเหมือนกับ "กล่อง" ที่มีหน้าจอสีน้ำเงิน ฉันจะไม่แปลกใจถ้าในไม่ช้าพีซีที่บ้านจะถือว่าเทียบเท่ากับเครื่องใช้ไฟฟ้าในครัวเรือน อย่างไรก็ตาม “กลไกแห่งความก้าวหน้า” ที่ทุกคนคุ้นเคยคือสิ่งที่ Intel ทำนายไว้สำหรับเรา โดยส่งเสริมแนวคิดเกี่ยวกับบ้านดิจิทัล
ดังนั้นคอมพิวเตอร์ส่วนบุคคลจึงพบช่องทางเฉพาะในทุกด้านของชีวิตมนุษย์ การปรากฏและการเกิดขึ้นของมันในฐานะองค์ประกอบสำคัญของวิถีชีวิตได้กลายเป็นประวัติศาสตร์ไปแล้ว เมื่อเราพูดถึงพีซี เราหมายถึงระบบที่เข้ากันได้กับ IBM PC และค่อนข้างถูกต้องเช่นกัน มีผู้อ่านเพียงไม่กี่คนที่เคยเห็นระบบที่ไม่รองรับ IBM PC ด้วยตาของตัวเอง ซึ่งไม่ค่อยได้ใช้มากนัก
IBM PC และคอมพิวเตอร์ที่เข้ากันได้ทั้งหมดใช้โปรเซสเซอร์ x86 จริงๆ แล้วบางครั้งดูเหมือนว่านี่ไม่ใช่แค่สถาปัตยกรรมโปรเซสเซอร์เท่านั้น แต่ยังรวมถึงสถาปัตยกรรมของพีซีทั้งหมดด้วย เช่นเดียวกับอุดมการณ์ของโครงสร้างระบบโดยรวม เป็นการยากที่จะบอกว่าใครดึงใครมาด้วย ไม่ว่าจะเป็นนักพัฒนาอุปกรณ์ต่อพ่วงและผลิตภัณฑ์ขั้นสุดท้ายที่ปรับให้เข้ากับสถาปัตยกรรม x86 หรือในทางกลับกัน พวกเขากำหนดเส้นทางการพัฒนาของโปรเซสเซอร์ x86 โดยตรงหรือโดยอ้อม ประวัติความเป็นมาของ x86 ไม่ใช่เส้นทางแอสฟัลต์ที่ราบเรียบ แต่เป็นชุดของขั้นตอนของนักพัฒนาที่มีระดับความรุนแรงและความอัจฉริยะที่แตกต่างกัน ซึ่งเกี่ยวพันกับปัจจัยทางเศรษฐกิจอย่างมาก ความรู้เกี่ยวกับประวัติของโปรเซสเซอร์ x86 นั้นไม่จำเป็นเลย การเปรียบเทียบโปรเซสเซอร์ของความเป็นจริงในปัจจุบันกับบรรพบุรุษโบราณนั้นไร้จุดหมาย แต่เพื่อที่จะติดตามแนวโน้มการพัฒนาทั่วไปและพยายามคาดการณ์ จำเป็นต้องมีการสำรวจอดีตทางประวัติศาสตร์ของสถาปัตยกรรม x86 แน่นอนว่างานประวัติศาสตร์ที่จริงจังอาจกินเวลามากกว่าหนึ่งเล่ม และไม่มีประโยชน์ที่จะอ้างวัตถุประสงค์และการรายงานข่าวในวงกว้างของหัวข้อนี้ ดังนั้นเราจะไม่เข้าสู่ความผันผวนของ "อายุการใช้งาน" ของโปรเซสเซอร์ x86 แต่ละรุ่น แต่จะจำกัดตัวเองอยู่เฉพาะเหตุการณ์ที่สำคัญที่สุดในมหากาพย์ x86 ทั้งหมด
1968
พนักงานสี่คนของ Fairchild Semiconductor: Bob Noyce ผู้จัดการและผู้ประดิษฐ์วงจรรวมในปี 1959 Gordon Moore ซึ่งเป็นผู้นำ การวิจัยทางวิทยาศาสตร์และการพัฒนาการออกแบบ Andy Grove ผู้เชี่ยวชาญด้านเทคโนโลยีเคมี และ Arthur Rock ผู้ให้การสนับสนุนทางการเงิน ได้ก่อตั้ง Intel ชื่อนี้ได้มาจากอินทิกรัลอิเล็กทรอนิกส์
1969
อดีตผู้อำนวยการฝ่ายการตลาดของ Fairchild Semiconductor, Jerry Sanders และบุคคลที่มีความคิดเหมือนกันอีกหลายคนได้ก่อตั้งบริษัท AMD (Advanced Micro Devices) ซึ่งเริ่มผลิตอุปกรณ์ไมโครอิเล็กทรอนิกส์
1971
เมื่อปฏิบัติตามคำสั่งซื้อชิป RAM อย่างใดอย่างหนึ่ง พนักงานของ Intel Ted Hoff เสนอให้สร้าง IC "อัจฉริยะ" ที่เป็นสากล การพัฒนานำโดย Federico Fagin เป็นผลให้ไมโครโปรเซสเซอร์ตัวแรก Intel 4004 ถือกำเนิดขึ้น
1978
ช่วงเวลาทั้งหมดก่อนหน้านี้เป็นยุคก่อนประวัติศาสตร์แม้ว่าจะแยกไม่ออกจากเหตุการณ์ที่เกิดขึ้นต่อไปก็ตาม ปีนี้ยุค x86 เริ่มต้นขึ้น - Intel ได้สร้างไมโครโปรเซสเซอร์ i8086 ซึ่งมีความถี่ 4.77.8 และ 10 MHz ความถี่ตลก? ใช่ นี่คือความถี่ของเครื่องคิดเลขสมัยใหม่ แต่นี่คือจุดเริ่มต้นทั้งหมด ชิปนี้ผลิตขึ้นโดยใช้เทคโนโลยี 3 μm และมีการออกแบบภายใน 16 บิตและบัส 16 บิต นั่นคือการสนับสนุน 16 บิตและด้วยเหตุนี้ระบบปฏิบัติการและโปรแกรม 16 บิตจึงปรากฏขึ้น
ต่อมาในปีเดียวกัน i8088 ได้รับการพัฒนา ความแตกต่างที่สำคัญคือบัสข้อมูลภายนอก 8 บิต ทำให้มั่นใจได้ถึงความเข้ากันได้กับฮาร์ดแวร์และหน่วยความจำ 8 บิตที่ใช้ก่อนหน้านี้ ข้อโต้แย้งที่สนับสนุนก็คือความเข้ากันได้กับ i8080/8085 และ Z-80 และราคาค่อนข้างต่ำ อย่างไรก็ตาม IBM เลือก i8088 เป็น CPU สำหรับพีซีเครื่องแรก ตั้งแต่นั้นมา โปรเซสเซอร์ Intel จะกลายเป็นส่วนสำคัญของคอมพิวเตอร์ส่วนบุคคล และคอมพิวเตอร์เองก็จะถูกเรียกว่า IBM PC ไปอีกนาน
 |
1982
i80286 ประกาศแล้ว “สองร้อยแปดสิบหก” กลายเป็นโปรเซสเซอร์ x86 ตัวแรกที่เจาะพื้นที่โซเวียตและหลังโซเวียตเป็นจำนวนมาก ความถี่สัญญาณนาฬิกา 6, 8, 10 และ 12 MHz ผลิตโดยใช้เทคโนโลยีการผลิต 1.5 μm และมีทรานซิสเตอร์ประมาณ 130,000 ตัว ชิปตัวนี้รองรับ 16 บิตเต็มรูปแบบ เป็นครั้งแรกที่มีการถือกำเนิดของ i80286 แนวคิดเช่น "โหมดป้องกัน" ปรากฏขึ้น แต่จากนั้นนักพัฒนา ซอฟต์แวร์ไม่ได้ใช้ความสามารถของตนอย่างเต็มที่ โปรเซสเซอร์สามารถจัดการหน่วยความจำได้มากกว่า 1 MB โดยการสลับไปยังโหมดที่ได้รับการป้องกัน แต่สามารถย้อนกลับได้หลังจากรีสตาร์ทเสร็จสมบูรณ์ และการจัดแบ่งการเข้าถึงหน่วยความจำแบบแบ่งกลุ่มต้องใช้ความพยายามเพิ่มเติมอย่างมากเมื่อเขียนโค้ดโปรแกรม สิ่งนี้นำไปสู่ความจริงที่ว่า i80286 ถูกใช้เหมือนกับ i8086 ที่รวดเร็วมากกว่า
 |
ประสิทธิภาพของชิปเมื่อเทียบกับ 8086 (และโดยเฉพาะเมื่อเทียบกับ i8088) เพิ่มขึ้นหลายครั้งและสูงถึง 2.6 ล้านการทำงานต่อวินาที ในช่วงหลายปีที่ผ่านมา ผู้ผลิตเริ่มใช้สถาปัตยกรรมแบบเปิดของพีซี IBM อย่างแข็งขัน ในเวลาเดียวกันระยะเวลาของการโคลนโปรเซสเซอร์ x86 จาก Intel โดยผู้ผลิตบุคคลที่สามก็เริ่มขึ้น นั่นคือชิปดังกล่าวผลิตโดยบริษัทอื่นเป็นสำเนาถูกต้อง Intel 80286 กลายเป็นพื้นฐานของพีซีรุ่นใหม่ล่าสุดตามมาตรฐานเหล่านั้น นั่นคือ IBM PC/AT และโคลนต่างๆ มากมาย ข้อได้เปรียบหลักของโปรเซสเซอร์ใหม่คือประสิทธิภาพที่เพิ่มขึ้นและโหมดการกำหนดแอดเดรสเพิ่มเติม และที่สำคัญที่สุด - ความเข้ากันได้กับซอฟต์แวร์ที่มีอยู่ โดยปกติแล้ว โปรเซสเซอร์ยังได้รับอนุญาตจากผู้ผลิตบุคคลที่สาม...
ในปีเดียวกันนั้น AMD ได้ทำข้อตกลงกับ Intel ข้อตกลงและบนพื้นฐานของมันเริ่มการผลิตโคลนของโปรเซสเซอร์ x86
1985
ในปีนี้อาจเป็นเหตุการณ์ที่สำคัญที่สุดในประวัติศาสตร์ของโปรเซสเซอร์ที่มีสถาปัตยกรรม x86 - Intel เปิดตัวโปรเซสเซอร์ i80386 ตัวแรก อาจกล่าวได้ว่าเป็นการปฏิวัติ: โปรเซสเซอร์มัลติทาสกิ้ง 32 บิตที่มีความสามารถในการรันหลายโปรแกรมพร้อมกัน โดยพื้นฐานแล้วโปรเซสเซอร์สมัยใหม่ส่วนใหญ่ไม่มีอะไรมากไปกว่า 386 ที่รวดเร็ว ซอฟต์แวร์สมัยใหม่ใช้สถาปัตยกรรม 386 แบบเดียวกัน เพียงแต่ว่าโปรเซสเซอร์สมัยใหม่ทำสิ่งเดียวกัน แต่เร็วกว่าเท่านั้น Intel 386™ มีการปรับปรุงอย่างมากเมื่อเทียบกับ i8086 และ i80286 โดยพื้นฐานแล้วโปรเซสเซอร์สมัยใหม่ส่วนใหญ่ไม่มีอะไรมากไปกว่า 386 ที่รวดเร็ว ซอฟต์แวร์สมัยใหม่ใช้สถาปัตยกรรม 386 แบบเดียวกัน เพียงแต่ว่าโปรเซสเซอร์สมัยใหม่ทำสิ่งเดียวกัน แต่เร็วกว่าเท่านั้น Intel 386™ มีการปรับปรุงอย่างมากเมื่อเทียบกับ i8086 และ i80286 Intel 386™ ได้รับการปรับปรุงการจัดการหน่วยความจำอย่างมีนัยสำคัญเมื่อเทียบกับ i80286 และความสามารถมัลติทาสก์ในตัวทำให้สามารถพัฒนาระบบปฏิบัติการได้ ระบบไมโครซอฟต์ Windows และ OS/2
 |
ต่างจาก i80286 ตรงที่ Intel 386™ สามารถสลับจากโหมดที่ได้รับการป้องกันเป็นโหมดจริงและกลับมาอีกครั้งได้อย่างอิสระ และมีโหมดใหม่ - 8086 เสมือน ในโหมดนี้ โปรเซสเซอร์สามารถรันซอฟต์แวร์เธรดที่แตกต่างกันหลายตัวพร้อมกัน เนื่องจากแต่ละเธรดทำงานบน แยก "เสมือน" รถยนต์คันที่ 86 โปรเซสเซอร์ได้แนะนำโหมดการกำหนดแอดเดรสหน่วยความจำเพิ่มเติมที่มีความยาวส่วนต่างๆ ซึ่งทำให้การสร้างแอปพลิเคชันง่ายขึ้นมาก โปรเซสเซอร์ผลิตขึ้นโดยใช้กระบวนการทางเทคโนโลยีขนาด 1 ไมครอน เป็นครั้งแรกที่มีการนำเสนอโปรเซสเซอร์ Intel ในหลายรุ่นที่ประกอบขึ้นเป็นตระกูล 386 นี่คือจุดเริ่มต้นของเกมการตลาดอันโด่งดัง อินเทลซึ่งต่อมาส่งผลให้มีการแบ่งคอร์ที่พัฒนาแล้วหนึ่งคอร์ออกเป็นสองรุ่นเชิงพาณิชย์ ในบางกลุ่มผู้ใช้และผู้เชี่ยวชาญเรียกว่า: "Pentium สำหรับคนรวย Celeron สำหรับคนจน" แม้ว่าสิ่งที่แย่ตรงนี้ก็คือหมาป่าได้รับอาหารอย่างดีและแกะก็ปลอดภัย
รุ่นต่อไปนี้เปิดตัว:
386DX ที่ 16, 20, 25 และ 33 MHz มีหน่วยความจำที่สามารถระบุตำแหน่งได้ 4 GB;
386SX ที่มีความถี่ 16, 20, 25 และ 33 MHz ซึ่งแตกต่างจาก 386DX มีบัสข้อมูล 16 มากกว่า 32 บิตและหน่วยความจำที่สามารถกำหนดแอดเดรสได้ 16 MB ตามนั้น (ในทำนองเดียวกันในคราวเดียวโปรเซสเซอร์ i8088 คือ “สร้าง” จาก i8086 โดยการลดความกว้างบิตของบัสภายนอกเพื่อให้แน่ใจว่าเข้ากันได้กับอุปกรณ์ภายนอกที่มีอยู่)
386SL ในเดือนตุลาคม 2533 - รุ่นมือถือโปรเซสเซอร์ Intel 386SX ที่มีความถี่ 20 และ 25 MHz
1989
Intel Corporation เปิดตัวโปรเซสเซอร์ตัวถัดไป - Intel 486™ DX ที่มีความถี่ 25, 33 และ 50 MHz Intel 486™ DX เป็นโปรเซสเซอร์ตัวแรกในตระกูล 486 และมีประสิทธิภาพเพิ่มขึ้นอย่างมีนัยสำคัญ (มากกว่า 2 เท่าที่ความถี่เดียวกัน) เมื่อเทียบกับตระกูล 386 โดยเพิ่มแคช L1 ขนาด 8 KB ที่รวมอยู่ในชิปและขนาดสูงสุด ของ L2 -แคชเพิ่มขึ้นเป็น 512 Kb i486DX ได้รวมหน่วยจุดลอยตัว (FPU - หน่วยจุดลอยตัว) ซึ่งก่อนหน้านี้ทำงานเป็นโปรเซสเซอร์ร่วมทางคณิตศาสตร์ภายนอกที่ติดตั้งบนเมนบอร์ด นอกจากนี้ นี่เป็นโปรเซสเซอร์ตัวแรกที่คอร์มีไปป์ไลน์ห้าขั้นตอน ดังนั้น คำสั่งที่ผ่านขั้นตอนแรกของไปป์ไลน์ ในขณะที่ดำเนินการต่อไปในขั้นตอนที่สอง จะปล่อยคำสั่งแรกสำหรับคำสั่งถัดไป หัวใจหลักของโปรเซสเซอร์ Intel 486™DX คือ Intel 386DX™ ที่รวดเร็ว รวมกับโปรเซสเซอร์ร่วมทางคณิตศาสตร์และแคช 8 KB บนชิปตัวเดียว การบูรณาการนี้ทำให้สามารถเพิ่มความเร็วของการสื่อสารระหว่างบล็อกให้เป็นค่าที่สูงมากได้
Intel เปิดตัวแคมเปญโฆษณาพร้อมสโลแกน "Intel: The Computer Inside" เวลาจะผ่านไปและจะกลายเป็นแคมเปญโฆษณาอันโด่งดัง “Intel Inside”
 |
1991
โปรเซสเซอร์ของ AMD ถูกสร้างขึ้น - Am386™ อันนี้ถูกสร้างขึ้นบางส่วนภายใต้ลิขสิทธิ์และส่วนหนึ่งมาจากการออกแบบของตัวเองและทำงานที่ความถี่สูงสุด 40 MHz ซึ่งสูงกว่าโปรเซสเซอร์ Intel
ก่อนหน้านี้เล็กน้อย การดำเนินคดีทางกฎหมายครั้งแรกเกิดขึ้นระหว่าง Intel และ AMD เกี่ยวกับความตั้งใจของ AMD ในการขายโคลน Intel 386™ หลังจากเสริมความแข็งแกร่งให้กับจุดยืนอย่างมั่นคง Intel ไม่จำเป็นต้องแจกจ่ายใบอนุญาตให้กับผู้ผลิตบุคคลที่สามอีกต่อไปและจะไม่แบ่งปันพายของตัวเองกับใครเลย เป็นผลให้ AMD เข้าสู่ตลาดโปรเซสเซอร์ x86 เป็นครั้งแรกในฐานะคู่แข่ง บริษัทอื่นก็ตามมา ดังนั้นการเผชิญหน้าครั้งใหญ่ระหว่างสองยักษ์ใหญ่จึงเริ่มต้นขึ้นซึ่งดำเนินต่อไปจนถึงทุกวันนี้ (คู่แข่งที่เหลือหลุดออกไป) ซึ่งทำให้โลกได้รับสิ่งที่ดีมากมาย สโลแกนที่ไม่ได้พูดของคู่แข่งของ Intel คือวลี: "เหมือนกับ Intel แต่ในราคาที่ต่ำกว่า"
ในเวลาเดียวกัน Intel เปิดตัว i486SX ซึ่งเพื่อลดต้นทุนของผลิตภัณฑ์จึงไม่มีหน่วย FPU (โปรเซสเซอร์ร่วมแบบรวม) ซึ่งแน่นอนว่ามีผลกระทบด้านลบต่อประสิทธิภาพ ไม่มีความแตกต่างอื่นใดจาก i486DX
 |
1992
ด้วยการเปิดตัวโปรเซสเซอร์ Intel 486DX2 มีการใช้ปัจจัยการคูณความถี่บัสเป็นครั้งแรก เมื่อถึงจุดนี้ ความถี่ภายในของคอร์เท่ากับความถี่ของบัสข้อมูลภายนอก (FSB) แต่เกิดปัญหาในการเพิ่มความถี่ดังกล่าว เนื่องจากบัสต่อพ่วงในพื้นที่ (ในขณะนั้น VESA VL-bus) และ อุปกรณ์ต่อพ่วงเองก็แสดงความไม่เสถียรที่ความถี่เกิน 33 MHz ตอนนี้อยู่ที่ความถี่ รถเมล์เอฟเอสบี 33 เมกะเฮิรตซ์ ความถี่สัญญาณนาฬิกาแกนหลักคือ 66 MHz เนื่องจากการคูณด้วย 2 เทคนิคนี้มีประวัติความเป็นมายาวนานและใช้กันในปัจจุบัน มีเพียงตัวคูณใน CPU สมัยใหม่เท่านั้นที่สามารถเกิน 20 ได้ Intel 486™ DX2 กลายเป็นโปรเซสเซอร์ยอดนิยมมาเป็นเวลานานและขายได้มหาศาล อย่างไรก็ตาม เช่นเดียวกับโคลนจากคู่แข่ง (AMD, Cyrix และอื่น ๆ ) ซึ่งขณะนี้มีความแตกต่างจาก "Intel ดั้งเดิม" อยู่บ้างแล้ว
 |
1993
เปิดตัวโปรเซสเซอร์ superscalar x86 ตัวแรกซึ่งมีความสามารถในการดำเนินการมากกว่าหนึ่งคำสั่งต่อรอบสัญญาณนาฬิกา - Pentium (ชื่อรหัส P5) ซึ่งสามารถทำได้โดยการมีสายพานลำเลียงที่ทำงานขนานกันสองตัวที่เป็นอิสระ โปรเซสเซอร์ตัวแรกมีความถี่ 60 และ 66 MHz และได้รับบัสข้อมูล 64 บิต เป็นครั้งแรกที่แคช L1 ถูกแบ่งออกเป็นสองส่วน: แยกจากกันสำหรับคำแนะนำและข้อมูล แต่หนึ่งในนวัตกรรมที่สำคัญที่สุดคือหน่วยจุดลอยตัว (FPU) ที่ได้รับการอัปเดตอย่างสมบูรณ์ ในความเป็นจริง ก่อนหน้านี้ไม่เคยมี FPU ที่ทรงพลังขนาดนี้บนแพลตฟอร์ม x86 และเพียงไม่กี่ปีหลังจากการเปิดตัว Intel Pentium คู่แข่งก็สามารถไปถึงระดับประสิทธิภาพได้ นอกจากนี้ เป็นครั้งแรกที่มีการรวมบล็อกการทำนายสาขาไว้ในโปรเซสเซอร์ ซึ่งได้รับการพัฒนาอย่างแข็งขันโดยวิศวกรตั้งแต่นั้นมา
สิ่งที่สำคัญที่สุดคือ: ในโปรแกรมใด ๆ มีการเปลี่ยนแบบมีเงื่อนไขมากมาย เมื่อการทำงานของโปรแกรมจะต้องไปตามเส้นทางใดเส้นทางหนึ่ง ขึ้นอยู่กับเงื่อนไข สามารถวางการเปลี่ยนแปลงได้เพียงหนึ่งในหลายสาขาในไปป์ไลน์ และหากท้ายที่สุดเต็มไปด้วยโค้ดจากสาขาที่ไม่ถูกต้อง ก็จะต้องเคลียร์และเติมรอบสัญญาณนาฬิกาหลายรอบ (ขึ้นอยู่กับจำนวนขั้นตอนของไปป์ไลน์) . มีการใช้กลไกการทำนายสาขาเพื่อแก้ไขปัญหานี้ โปรเซสเซอร์ประกอบด้วยทรานซิสเตอร์ 3.1 ล้านตัวและผลิตโดยใช้กระบวนการ 0.8 ไมโครเมตร การเปลี่ยนแปลงทั้งหมดนี้ทำให้สามารถเพิ่มประสิทธิภาพของโปรเซสเซอร์ใหม่ให้สูงขึ้นจนไม่สามารถบรรลุได้ ในความเป็นจริง การปรับโค้ดให้เหมาะสมที่สุด “สำหรับโปรเซสเซอร์” เกิดขึ้นได้ยากในตอนแรก และจำเป็นต้องใช้คอมไพเลอร์พิเศษ และเป็นเวลานานที่โปรเซสเซอร์ใหม่ล่าสุดต้องรันโปรแกรมที่ออกแบบมาสำหรับโปรเซสเซอร์ตระกูล 486 และ 386
ในปีเดียวกัน Pentium รุ่นที่สองปรากฏบนคอร์ P54 ซึ่งข้อบกพร่องทั้งหมดของ P5 ได้ถูกกำจัดออกไป ในระหว่างการผลิต มีการใช้กระบวนการทางเทคโนโลยีใหม่ขนาด 0.6 และหลังจากนั้น 0.35 ไมโครเมตร จนถึงปี 1996 โปรเซสเซอร์ใหม่ครอบคลุมความถี่สัญญาณนาฬิกาตั้งแต่ 75 ถึง 200 MHz
Pentium รุ่นแรกมีบทบาทสำคัญในการเปลี่ยนผ่านไปสู่ระดับใหม่ของประสิทธิภาพของคอมพิวเตอร์ส่วนบุคคล เป็นแรงผลักดันและกำหนดแนวทางการพัฒนาสำหรับอนาคต แม้ว่าประสิทธิภาพจะก้าวกระโดดครั้งใหญ่ แต่ก็ไม่ได้ทำให้เกิดการเปลี่ยนแปลงพื้นฐานใดๆ กับสถาปัตยกรรม x86
1994
Intel 486™DX4, AMD Am486DX4 และ Cyrix 4x86 ที่เกิดขึ้นใหม่ยังคงดำเนินต่อไปในสาย 486 และการใช้การคูณความถี่บัสข้อมูล โปรเซสเซอร์มีความถี่สามเท่า โปรเซสเซอร์ DX4 ของ Intel วิ่งที่ 75 และ 100 MHz และ Am486DX4 ของ AMD ถึง 120 MHz ระบบการจัดการพลังงานมีการใช้กันอย่างแพร่หลายในโปรเซสเซอร์ ไม่มีความแตกต่างพื้นฐานอื่นๆ จาก 486DX2
1995
ประกาศเปิดตัว Pentium Pro (P6 core) บัสโปรเซสเซอร์ใหม่, ไปป์ไลน์อิสระสามท่อ, การเพิ่มประสิทธิภาพสำหรับโค้ด 32 บิต, จาก 256 Kb ถึง 1 Mb L2 cache ที่รวมอยู่ในโปรเซสเซอร์, ทำงานที่ความถี่คอร์, กลไกการทำนายสาขาที่ได้รับการปรับปรุง - ตามจำนวนนวัตกรรม โปรเซสเซอร์ใหม่เกือบจะทำลายสถิติที่ Intel Pentium กำหนดไว้ก่อนหน้านี้
 |
โปรเซสเซอร์อยู่ในตำแหน่งสำหรับใช้ในเซิร์ฟเวอร์และมีราคาที่สูงมาก สิ่งที่น่าทึ่งที่สุดคือคอร์ประมวลผล Pentium Pro ไม่ใช่คอร์สถาปัตยกรรม x86 จริงๆ รหัสเครื่อง x86 ที่เข้าสู่ CPU ได้รับการถอดรหัสภายในเป็นไมโครโค้ดที่คล้ายกับ RISC และนี่คือสิ่งที่แกนประมวลผลประมวลผล ชุดคำสั่ง CISC เช่นเดียวกับชุดคำสั่งของโปรเซสเซอร์ x86 บ่งบอกถึงความยาวคำสั่งแบบแปรผัน ซึ่งกำหนดความยากในการค้นหาแต่ละคำสั่งในสตรีม และดังนั้นจึงสร้างปัญหาในการพัฒนาโปรแกรม ทีม CISC มีความซับซ้อนและซับซ้อน คำสั่ง RISC นั้นเรียบง่าย สั้น และใช้เวลาน้อยกว่ามากในการรันคำสั่งที่มีความยาวคงที่ การใช้คำสั่ง RISC ช่วยให้คุณสามารถเพิ่มความขนานของการคำนวณตัวประมวลผลได้อย่างมากนั่นคือใช้ไปป์ไลน์มากขึ้นและลดเวลาดำเนินการของคำสั่ง แกน P6 เป็นพื้นฐานของโปรเซสเซอร์ Intel สามตัวถัดไป ได้แก่ Pentium II, Celeron, Pentium III
ปีนี้ยังเห็นเหตุการณ์สำคัญ - AMD ซื้อ NexGen ซึ่งในเวลานั้นมีการพัฒนาสถาปัตยกรรมขั้นสูง การควบรวมกิจการของทีมวิศวกรทั้งสองจะนำโปรเซสเซอร์ x86 ระดับโลกที่มีสถาปัตยกรรมไมโครที่แตกต่างจาก Intel มาใช้ในเวลาต่อมา และทำให้เกิดแรงผลักดันให้เกิดการแข่งขันที่ดุเดือดครั้งใหม่
โปรเซสเซอร์ MediaGX ใหม่จาก Cyrix ถูกนำเสนอเป็นครั้งแรกที่ Microprocessor Forum และคุณสมบัติที่โดดเด่นของมันคือตัวควบคุมหน่วยความจำในตัว ตัวเร่งกราฟิก อินเทอร์เฟซบัส PCI และประสิทธิภาพที่เทียบเท่ากับ Pentium นี่เป็นความพยายามครั้งแรกในการบูรณาการอุปกรณ์อย่างแน่นหนาเช่นนี้
1996
มีอันใหม่แล้ว โปรเซสเซอร์เอเอ็มดี K5 พร้อมคอร์ RISC ซูเปอร์สเกลาร์ อย่างไรก็ตาม แกน RISC และชุดคำสั่ง (คำสั่ง ROP) จะถูกซ่อนจากซอฟต์แวร์และผู้ใช้ และคำสั่ง x86 จะถูกแปลงเป็นคำสั่ง RISC วิศวกรของ AMD ใช้โซลูชันที่ไม่เหมือนใคร - คำสั่ง x86 จะถูกแปลงบางส่วนในขณะที่อยู่ในแคชของโปรเซสเซอร์ ตามหลักการแล้ว โปรเซสเซอร์ K5 สามารถดำเนินการได้ถึงสี่คำสั่ง x86 ต่อรอบสัญญาณนาฬิกา แต่ในทางปฏิบัติ โดยเฉลี่ยแล้ว จะมีการประมวลผลเพียง 2 คำสั่งต่อรอบสัญญาณนาฬิกาเท่านั้น
 |
นอกจากนี้ การเปลี่ยนแปลงลำดับการคำนวณ การเปลี่ยนชื่อรีจิสเตอร์ และ "เทคนิค" อื่นๆ แบบดั้งเดิมสำหรับโปรเซสเซอร์ RISC สามารถเพิ่มประสิทธิภาพได้ โปรเซสเซอร์ K5 เป็นผลงานของทีมวิศวกรร่วมจาก AMD และ NexGen ความเร็วสัญญาณนาฬิกาสูงสุดไม่เกิน 116 MHz แต่ประสิทธิภาพของ K5 นั้นสูงกว่าโปรเซสเซอร์ Pentium ที่มีความเร็วสัญญาณนาฬิกาเท่ากัน ดังนั้นเพื่อวัตถุประสงค์ทางการตลาด เป็นครั้งแรกในการฝึกฝนการทำเครื่องหมาย CPU จึงมีการใช้คะแนนประสิทธิภาพซึ่งแตกต่างอย่างชัดเจนกับความเร็วสัญญาณนาฬิกาของ Pentium ซึ่งมีประสิทธิภาพเท่ากัน แต่โปรเซสเซอร์ยังคงไม่สามารถแข่งขันกับมันได้อย่างเพียงพอเนื่องจาก Pentium มีความถี่ถึง 166 MHz แล้ว
ในปีเดียวกันนั้น Intel Pentium MMX ก็ได้เปิดตัว นวัตกรรมหลักของโปรเซสเซอร์ P55C คือคำสั่ง MXX เพิ่มเติมสำหรับชุดคำสั่งซึ่งแทบไม่มีการเปลี่ยนแปลงใด ๆ เลยนับตั้งแต่สร้างโปรเซสเซอร์รุ่นที่สาม เทคโนโลยี MMX คือการใช้คำสั่งที่เน้นการทำงานกับข้อมูลมัลติมีเดีย ชุดคำสั่งพิเศษ SIMD (คำสั่งเดียว - หลายข้อมูล) ปรับปรุงประสิทธิภาพเมื่อดำเนินการเวกเตอร์ คำสั่งแบบวนรอบ และประมวลผลข้อมูลจำนวนมาก - เมื่อใช้ตัวกรองกราฟิกและเอฟเฟกต์พิเศษต่างๆ
 |
โดยพื้นฐานแล้วนี่คือคำสั่งใหม่ 57 คำสั่งที่ออกแบบมาเพื่อเร่งความเร็วการประมวลผลวิดีโอและเสียง การเปลี่ยนแปลงเคอร์เนลที่เหลือคือการเพิ่มหน่วยความจำแคชโดยทั่วไป การปรับปรุงการทำงานของหน่วยความจำแคช และบล็อกอื่นๆ โปรเซสเซอร์ผลิตขึ้นโดยใช้กระบวนการ 0.35 ไมครอน ทรานซิสเตอร์ 4.5 ล้านตัว ความถี่สูงสุด 233 MHz.
การผลิตโปรเซสเซอร์ Superscalar Cyrix 6x86 เริ่มต้นบนคอร์ M1 ซึ่งจริงๆ แล้วเป็นโปรเซสเซอร์รุ่นที่ 5 โดยมีคุณลักษณะที่โดดเด่นคือไปป์ไลน์ "ลึก" และการใช้คำสั่ง x86 แบบคลาสสิกโดยไม่มีชุดคำสั่งเพิ่มเติม
ในช่วงสิ้นปี ขณะที่ Intel กำลังพัฒนา PentiumII นั้น AMD ก็กลับมาเป็นที่รู้จักอีกครั้งด้วยการเปิดตัวโปรเซสเซอร์ K6 รุ่นที่หก AMD-K6 มีพื้นฐานมาจากคอร์ที่พัฒนาโดยวิศวกร NexGen สำหรับโปรเซสเซอร์ Nx686 และได้รับการดัดแปลงอย่างมากโดย AMD เช่นเดียวกับ K5 แกน K6 ไม่ได้ทำงานด้วยคำสั่ง x86 แต่ใช้ไมโครโค้ดที่คล้ายกับ RISC โปรเซสเซอร์รองรับคำสั่ง MMX และบัสระบบ 100-MHz และมีแคช L1 เพิ่มขึ้นเป็น 64 KB ในไม่ช้าก็เห็นได้ชัดว่า PentiumII นั้นแข็งแกร่งเกินไปสำหรับ K6
ตั้งแต่ปี 2540 ถึงปัจจุบัน...
ภายในปี 1997 ทิศทางการพัฒนาทางวิศวกรรมของสถาปัตยกรรม x86 จากผู้ผลิตชั้นนำได้พัฒนาไปแล้ว ขั้นตอนต่อไปในการพัฒนาโปรเซสเซอร์ x86 สามารถมีลักษณะเป็นการเผชิญหน้าระหว่างสถาปัตยกรรมซึ่งยังคงดำเนินต่อไปจนถึงทุกวันนี้ ครั้งใหญ่ Intel เข้าสู่การแข่งขันโดยยึดตลาดได้ 90% AMD ต่อสู้กับมันอย่างดื้อรั้นสูญเสียกำลังการผลิตไปหลายครั้งและ Cyrix ซึ่ง VIA จะซื้อในภายหลังจากนั้นก็ไม่สามารถทนต่อ การแข่งขันจะจมลงสู่ความสับสน ผู้ผลิตรายอื่นจะไม่สามารถแข่งขันได้เพียงพอและจะถูกบังคับให้มองหาตลาดเฉพาะกลุ่มอื่น ๆ มีการวางแผนการเปลี่ยนจาก CISC ไปเป็นคำสั่งย่อยที่คล้ายกับ RISC ในระดับที่น้อยลงสำหรับ Intel และมากขึ้นสำหรับ AMD นอกจากนี้ คำสั่ง CISC ยังคงมาถึงอินพุตและเอาต์พุตของโปรเซสเซอร์ x86 จริงๆ แล้ว เหตุใดพวกเขาจึงเริ่มแนะนำสถาปัตยกรรม RISC ภายในให้กับโปรเซสเซอร์ x86 ด้วยสถาปัตยกรรม CISC ดั้งเดิม ซึ่งช่วยให้ดำเนินการคำสั่งแบบขนานได้ลึกยิ่งขึ้น ใช่ จากสถาปัตยกรรม CISC x86 ในสมัยก่อน รุ่นที่สี่ทุกอย่างถูกบีบออก และไม่มีวิธีใดที่จะปรับปรุงประสิทธิภาพในระดับชุดคำสั่งพื้นฐานได้
 |
ตั้งแต่นั้นเป็นต้นมา ไม่มีการเปลี่ยนแปลงหรือความก้าวหน้าใหม่ๆ โดยพื้นฐานในการพัฒนาสถาปัตยกรรม แม้ว่าโปรเซสเซอร์สมัยใหม่จะเร็วขึ้นหลายร้อยเท่า เช่น 386 วิศวกรได้ฝึกฝนและปรับปรุงสถาปัตยกรรมไมโครหลักที่มีอยู่ และสถาปัตยกรรมใหม่ก็เป็นเพียงการปรับปรุงสถาปัตยกรรมเก่าเท่านั้น การปรับปรุงและความพยายามที่จะปรับปรุงประสิทธิภาพทั้งหมดขึ้นอยู่กับการเพิ่มประสิทธิภาพ โซลูชั่นที่มีอยู่การแนะนำการแก้ไขต่างๆ และ "ไม้ค้ำยัน" สำหรับ FPU ที่ง่อย ระบบสำหรับจัดระเบียบไปป์ไลน์และแคช วิธีที่ถูกแฮ็กแต่ยังคงมีประสิทธิภาพคือการเพิ่มขนาดแคชและความถี่บัส FSB อย่างต่อเนื่อง โปรเซสเซอร์สมัยใหม่มีหน่วยความจำแคชสูงสุด 2 MB ทำงานที่ความถี่คอร์และความถี่บัสระบบสูงถึง 800 MHz จากนั้นใช้ตัวคูณเนื่องจากความถี่ที่สร้างขึ้นจริงคือเพียง 200 MHz ในช่วง 7 ปีที่ผ่านมา "นวัตกรรมการเสริมกำลัง" ต่อไปนี้ได้ถูกนำมาใช้ในโปรเซสเซอร์ x86: ในที่สุดหน่วยความจำแคชก็ถูกย้ายไปยังชิปโปรเซสเซอร์และถ่ายโอนไปยังความถี่หลัก หน่วยการทำนายสาขาได้รับการแนะนำและได้รับการปรับปรุงอย่างต่อเนื่องเพื่อเป็นการชดเชยสำหรับ เพิ่มความยาว (จำนวนขั้นตอน) ของไปป์ไลน์กลไก การเปลี่ยนแปลงแบบไดนามิกลำดับการดำเนินการคำสั่ง การลดจำนวนรอบที่ไม่ได้ใช้งาน กลไกการดึงข้อมูลล่วงหน้าสำหรับการใช้หน่วยความจำแคชอย่างมีเหตุผลมากขึ้น ชุดคำสั่งเพิ่มเติมกำลังเพิ่มขึ้น: SSE, SSE2, SSE3, 3DNow!, 3DNow Professional หากยังสามารถเรียก MMX ได้ โดยขยายชุดคำสั่ง x86 เพิ่มเติม ชุดที่ตามมาทั้งหมดไม่น่าจะเป็นไปได้ เนื่องจากไม่มีอะไรเหลือให้เพิ่มในคำสั่ง x86 จุดเด่นของการปรากฏตัวของชุดเหล่านี้คือการพยายามใช้หน่วยจุดลอยตัว (FPU) ให้น้อยที่สุดเท่าที่จะเป็นไปได้ในรูปแบบที่เป็นอยู่ เนื่องจากแม้ว่าจะมีประสิทธิภาพสูง แต่ก็มีคุณลักษณะที่ความสามารถในการปรับตัวต่ำเพื่อให้ได้ความแม่นยำสูง การคำนวณความไม่แน่นอนของสถาปัตยกรรมภายในและความคาดเดาไม่ได้ ซึ่งทำให้ชีวิตของโปรแกรมเมอร์ยากขึ้น นั่นคือพวกเขาแนะนำหน่วยการคำนวณพิเศษจริง ๆ ซึ่งไม่ได้เน้นไปที่การคำนวณโดยทั่วไป แต่เน้นไปที่งานจริงและพบบ่อยซึ่งเสนอให้ดำเนินการข้าม FPU แบบคลาสสิก
 |
ดูเหมือนการดิ้นรนกับผลที่ตามมาจากการรวมตัวประมวลผลร่วมทางคณิตศาสตร์เข้ากับ CPU เมื่อปี 1989 ไม่ว่าในกรณีใด หากคุณคิดและนับจำนวน โปรเซสเซอร์จะใช้เวลาส่วนใหญ่ "กับตัวเอง" - กับการแปลง การคาดการณ์ และอื่นๆ อีกมากมายทุกประเภท และไม่เกี่ยวกับการรันโค้ดโปรแกรม
เมื่อมองย้อนกลับไปก็ชัดเจนว่าทุกอย่างไม่ราบรื่น การแนะนำปัจจัยการคูณและความไม่ซิงโครนัสที่เกิดขึ้นตลอดจนการเพิ่มจำนวนขั้นตอนไปป์ไลน์ล้วนเป็นดาบสองคม ในอีกด้านหนึ่งสิ่งนี้ทำให้สามารถเพิ่มความเร็วสัญญาณนาฬิกาของโปรเซสเซอร์เป็นเกือบ 4 GHz (และนี่ไม่ใช่ขีด จำกัด ) ในทางกลับกันเรามีคอขวดในรูปแบบของบัส FSB และปัญหาเกี่ยวกับการแตกแขนงแบบมีเงื่อนไข . แต่ทุกอย่างมีเวลาของมัน และเห็นได้ชัดว่านี่เป็นการตัดสินใจที่สมเหตุสมผล เนื่องจากมีปัจจัยทางเศรษฐกิจที่ชั่วร้ายอยู่เสมอ
ควรสังเกตว่าในช่วงไม่กี่ปีที่ผ่านมาประสบความสำเร็จอย่างยอดเยี่ยมในด้านการผลิตเซมิคอนดักเตอร์ กระบวนการทางเทคโนโลยี 90 นาโนเมตรสำหรับการผลิตโปรเซสเซอร์ x86 ได้รับการฝึกฝนแล้วซึ่งทำให้สามารถบรรลุความถี่สัญญาณนาฬิกาที่ใกล้เคียงกับช่วงไมโครเวฟและจำนวนทรานซิสเตอร์ในคริสตัลสูงถึง 170 ล้าน (Pentium 4 EE)
เราคุ้นเคยกับการคิดว่าโปรเซสเซอร์เป็นอุปกรณ์หลักในพีซี และเป็นตัวกำหนดทิศทางสำหรับการใช้คอมพิวเตอร์ทั่วโลก แต่การเดินขบวนแห่งชัยชนะของสถาปัตยกรรม x86 ซึ่งกินเวลานานกว่าหนึ่งในสี่ของศตวรรษนั้นไม่ได้เริ่มต้นจากโปรเซสเซอร์โดยเฉพาะ แต่เริ่มต้นกับอุปกรณ์ผู้ใช้โดยรวม - IBM PC ในเวลานั้น IBM ไม่รู้ว่าพีซีเครื่องนี้จะมีอนาคตอันสดใสรออยู่อย่างไร และพวกเขาไม่ได้ให้ความสำคัญกับโปรเจ็กต์นี้เลย พวกเขาเปิดให้ทุกคนเข้าถึงได้ ความสำเร็จของ IBM PC เกิดจากการเปิดกว้างของแนวคิด ความสำเร็จของซอฟต์แวร์และ MS DOS และโปรเซสเซอร์ในนั้นอาจเป็นสถาปัตยกรรมอะไรก็ได้ แต่มันก็เกิดขึ้นที่ IBM เลือก i8088 และ i8086 จากนั้นทุกอย่างก็เริ่มหมุนและหมุน... แต่ท้ายที่สุดแล้วโปรเซสเซอร์ x86 ก็ไม่ได้กลายเป็นแบบใด คอมพิวเตอร์สากลสำหรับทุกโอกาสหรืออุปกรณ์ "อัจฉริยะ" ที่มีอยู่ทั่วไปทุกหนทุกแห่งและสามารถทำได้ทุกอย่างอย่างที่เราฝันไว้เมื่อก่อน และ "กฎหมาย" ของกอร์ดอน มัวร์ (ทุกๆ 2 ปี จำนวนทรานซิสเตอร์ในชิปโปรเซสเซอร์จะเพิ่มขึ้นสองเท่า) กลายเป็นกฎหมายสำหรับ Intel เท่านั้น ซึ่งวางไว้แถวหน้าของนโยบายการตลาด และเห็นได้ชัดว่าไม่สะดวกที่จะปฏิเสธคำนี้ .
 |
วันนี้เราสามารถพูดได้อย่างชัดเจนว่าสถาปัตยกรรม x86 ถึงทางตันแล้ว การมีส่วนร่วมของเธอในการทำให้คอมพิวเตอร์เป็นที่นิยมในฐานะอุปกรณ์นั้นยิ่งใหญ่มากและไม่มีใครโต้แย้งในเรื่องนี้ อย่างไรก็ตาม คุณไม่สามารถมีความเกี่ยวข้องได้ตลอดไป ม้าตัวหนึ่งที่อายุน้อยและแข็งแกร่งได้กลายเป็นคนแก่ที่จู้จี้จุกจิกซึ่งยังคงถูกควบคุมไว้กับเกวียน ความอยากของผู้ใช้นั้นไม่เพียงพอ และในไม่ช้าสถาปัตยกรรม x86 ก็จะไม่สามารถสนองความต้องการเหล่านั้นได้ แน่นอนว่าการเปลี่ยนแปลงนี้เกี่ยวข้องกับความพยายามของ Herculean เนื่องจากกลุ่มพีซีมูลค่าหลายล้านดอลลาร์ของโลกซึ่งโดยส่วนใหญ่แล้วใช้โปรเซสเซอร์สถาปัตยกรรม x86 และที่สำคัญที่สุดคือใช้ซอฟต์แวร์สำหรับโค้ด x86 คุณไม่สามารถพลิกทุกสิ่งได้ภายในวันเดียว มันต้องใช้เวลาหลายปี แต่การพัฒนาโปรเซสเซอร์และโปรแกรม 64 บิตกำลังได้รับแรงผลักดันด้วยความเร็วที่น่าอิจฉา Intel เปิดตัว Itanium2 และ AMD ได้เปิดตัว Athlon 64 มาเกือบหนึ่งปีแล้วซึ่งไม่มีสถาปัตยกรรม x86 เลยแม้ว่าจะเต็มแล้วก็ตาม เข้ากันได้และยังสามารถรันโปรแกรมเก่าทั้งหมดได้ ดังนั้นเราสามารถพูดได้ว่า AMD Athlon 64 ถือเป็นจุดเริ่มต้นของการออกจากสถาปัตยกรรม x86 และด้วยเหตุนี้จึงเปิดช่วงการเปลี่ยนแปลง
อย่างที่คุณเห็น การอ้างว่าโปรเซสเซอร์เป็นส่วนประกอบพีซีที่เติบโตเร็วที่สุดนั้นยังห่างไกลจากการไม่มีมูลความจริง ลองนึกภาพว่าคอมพิวเตอร์สำหรับเด็กของเราจะติดตั้งโปรเซสเซอร์ประเภทใด คิดแล้วสยอง!
 |
ในออดโนคลาสนิกิ
ข้อสงวนสิทธิ์
อาจเป็นไปได้ว่าเหตุผลที่ถูกต้องที่สุดสำหรับการปรากฏตัวของวัสดุนี้สามารถกำหนดได้ดังนี้: "มันไม่จำเป็นมากนักที่จะต้องมีอยู่ แต่มันแปลกที่มันยังไม่มีอยู่" และแน่นอน: ในความคิดเห็นต่อผลการทดสอบ เราดำเนินการอย่างต่อเนื่องโดยใช้แนวคิดเช่น "ความจุแคช" "ความเร็วบัสโปรเซสเซอร์" "การสนับสนุนชุดคำสั่งเพิ่มเติม" แต่ไม่มีบทความใดในเว็บไซต์ที่จะมีคำอธิบาย ของข้อกำหนดทั้งหมดนี้ แน่นอนว่าการละเลยนี้จะต้องถูกกำจัดออกไป บทความนี้มีชื่อว่า “x86 CPU FAQ” เป็นความพยายามในการทำเช่นนั้น แน่นอนว่าบางส่วนสามารถนำมาประกอบได้ไม่เฉพาะกับโปรเซสเซอร์ x86 เท่านั้นและไม่ใช่เฉพาะกับเวอร์ชันเดสก์ท็อป (สำหรับการติดตั้งในพีซี) แต่เราไม่ได้มุ่งเป้าไปที่โลกาภิวัตน์ดังกล่าวอย่างแน่นอน ดังนั้น โปรดจำไว้ว่าสำหรับวัตถุประสงค์ของเนื้อหานี้ เว้นแต่จะระบุไว้อย่างชัดเจนเป็นอย่างอื่น คำว่า "โปรเซสเซอร์" หมายถึง "โปรเซสเซอร์ x86 ที่ออกแบบมาสำหรับการติดตั้งในเดสก์ท็อป" บางทีในกระบวนการปรับปรุงและขยายเพิ่มเติมส่วนที่ทุ่มเทให้กับ CPU ของเซิร์ฟเวอร์หรือแม้แต่โปรเซสเซอร์ของสถาปัตยกรรมอื่น ๆ อาจปรากฏในบทความ แต่นี่เป็นเรื่องของอนาคต...
การแนะนำ
รหัสและข้อมูล: หลักการพื้นฐานของโปรเซสเซอร์
ดังนั้น หากเราไม่พยายามนำเสนอหลักสูตร "สั้นๆ" ในด้านวิทยาการคอมพิวเตอร์สำหรับโรงเรียนมัธยมศึกษาตอนปลาย สิ่งเดียวที่ฉันอยากเตือนคุณก็คือโปรเซสเซอร์ (ซึ่งมีข้อยกเว้นที่หายาก) จะไม่รันโปรแกรมที่เขียนด้วยการเขียนโปรแกรมบางโปรแกรม ภาษา (หนึ่งในนั้น คุณอาจจะรู้ด้วยซ้ำ) แต่เป็น "รหัสเครื่อง" บางชนิด นั่นคือคำสั่งสำหรับมันคือลำดับไบต์ที่อยู่ในหน่วยความจำของคอมพิวเตอร์ บางครั้งคำสั่งอาจเท่ากับหนึ่งไบต์ บางครั้งอาจใช้เวลาหลายไบต์ ในหน่วยความจำหลัก (RAM, RAM) ข้อมูลก็อยู่เช่นกัน พวกเขาอาจอยู่ในพื้นที่แยกต่างหากหรืออาจ "ปะปน" กับรหัส ความแตกต่างระหว่างรหัสและข้อมูลคือข้อมูลคืออะไร เหนือสิ่งอื่นใดโปรเซสเซอร์กำลังดำเนินการบางอย่าง และรหัสคือคำสั่งที่บอกเขาว่า การผ่าตัดแบบไหน?เขาจะต้องผลิต เพื่อให้ง่ายขึ้น เราสามารถจินตนาการถึงโปรแกรมและข้อมูลเป็นลำดับไบต์ที่มีความยาวจำกัดที่แน่นอน ซึ่งอยู่ในอาร์เรย์หน่วยความจำทั่วไปอย่างต่อเนื่อง (อย่าทำให้เรื่องซับซ้อน) ตัวอย่างเช่น เรามีอาร์เรย์หน่วยความจำที่มีความยาว 1,000,000 ไบต์ และโปรแกรมของเรา (พร้อมกับข้อมูล) จะมีหมายเลขไบต์ตั้งแต่ 1,000 ถึง 20,000 ไบต์อื่นคือโปรแกรมอื่นหรือข้อมูลหรือเพียงแค่หน่วยความจำว่างที่ไม่มีประโยชน์อะไร
ดังนั้น “รหัสเครื่อง” จึงเป็นคำสั่งของโปรเซสเซอร์ที่อยู่ในหน่วยความจำ ข้อมูลก็อยู่ที่นั่นด้วย เพื่อดำเนินการคำสั่ง โปรเซสเซอร์จะต้องอ่านจากหน่วยความจำ ในการดำเนินการกับข้อมูล โปรเซสเซอร์จะต้องอ่านจากหน่วยความจำ และอาจเป็นไปได้ว่าหลังจากดำเนินการบางอย่างแล้ว ให้เขียนกลับไปยังหน่วยความจำในรูปแบบที่อัปเดต (เปลี่ยนแปลง) คำสั่งและข้อมูลจะถูกระบุตามที่อยู่ ซึ่งก็คือหมายเลขซีเรียลของตำแหน่งหน่วยความจำ
หลักการทั่วไปของการโต้ตอบ
โปรเซสเซอร์และ RAM
อาจทำให้บางคนประหลาดใจที่ส่วนที่ค่อนข้างใหญ่ในคำถามที่พบบ่อยเกี่ยวกับ CPU x86 นั้นมีไว้เพื่ออธิบายคุณสมบัติของหน่วยความจำที่ทำงานใน ระบบที่ทันสมัยอ่า ขึ้นอยู่กับโปรเซสเซอร์ประเภทนี้ อย่างไรก็ตามข้อเท็จจริงเป็นสิ่งที่ดื้อรั้น: ขณะนี้โปรเซสเซอร์ x86 มีบล็อกจำนวนมากที่รับผิดชอบในการเพิ่มประสิทธิภาพการทำงานกับ RAM โดยเฉพาะซึ่งคงไร้สาระอย่างยิ่งหากเพิกเฉยต่อการเชื่อมต่อที่ใกล้ชิดนี้ เราสามารถพูดสิ่งนี้ได้: เนื่องจากโซลูชันที่เกี่ยวข้องกับการเพิ่มประสิทธิภาพการทำงานด้วยหน่วยความจำได้กลายเป็นส่วนสำคัญของโปรเซสเซอร์ ดังนั้นหน่วยความจำจึงถือได้ว่าเป็น "ภาคผนวก" ประเภทหนึ่งซึ่งการทำงานมีผลกระทบโดยตรงต่อความเร็ว ของซีพียู หากไม่เข้าใจลักษณะเฉพาะของการโต้ตอบระหว่างโปรเซสเซอร์และหน่วยความจำ จึงเป็นไปไม่ได้ที่จะเข้าใจว่าทำไมโปรเซสเซอร์เฉพาะ (ระบบนี้หรือระบบนั้น) จึงรันโปรแกรมช้าลงหรือเร็วขึ้น
ตัวควบคุมหน่วยความจำ
ก่อนหน้านี้เราได้พูดคุยกันแล้วเกี่ยวกับความจริงที่ว่าทั้งคำสั่งและข้อมูลเข้าสู่โปรเซสเซอร์จาก RAM ที่จริงแล้วทุกอย่างซับซ้อนกว่าเล็กน้อย ในระบบ x86 ที่ทันสมัยที่สุด (นั่นคือคอมพิวเตอร์ที่ใช้โปรเซสเซอร์ x86) โปรเซสเซอร์ในฐานะอุปกรณ์ไม่สามารถเข้าถึงหน่วยความจำได้เลย เนื่องจากไม่มีโหนดที่เกี่ยวข้อง ดังนั้นจึงเปลี่ยนเป็นอุปกรณ์พิเศษ "ระดับกลาง" ที่เรียกว่าตัวควบคุมหน่วยความจำซึ่งจะเปลี่ยนเป็นชิป RAM ที่อยู่บนโมดูลหน่วยความจำ คุณคงเคยเห็นโมดูลเหล่านี้มาก่อน - เหล่านี้เป็น "ไม้กระดาน" textolite ที่ยาวและแคบ (จริงๆ แล้วเป็นบอร์ดขนาดเล็ก) โดยมีวงจรขนาดเล็กจำนวนหนึ่งเสียบอยู่ในตัวเชื่อมต่อพิเศษบนเมนบอร์ด บทบาทของตัวควบคุม RAM นั้นเรียบง่าย: ทำหน้าที่เป็น "บริดจ์"* ประเภทหนึ่งระหว่างหน่วยความจำและอุปกรณ์ที่ใช้งาน (โดยวิธีนี้ ไม่เพียงแต่รวมถึงโปรเซสเซอร์เท่านั้น แต่ยังรวมถึงอีกเล็กน้อยในภายหลัง) ตามกฎแล้วตัวควบคุมหน่วยความจำจะเป็นส่วนหนึ่งของชิปเซ็ตซึ่งเป็นชุดชิปที่เป็นพื้นฐาน เมนบอร์ด. ความเร็วของการแลกเปลี่ยนข้อมูลระหว่างโปรเซสเซอร์และหน่วยความจำส่วนใหญ่ขึ้นอยู่กับความเร็วของคอนโทรลเลอร์ซึ่งเป็นหนึ่งในองค์ประกอบที่สำคัญที่สุดที่ส่งผลต่อประสิทธิภาพโดยรวมของคอมพิวเตอร์
* - อย่างไรก็ตามตัวควบคุมหน่วยความจำนั้นอยู่ในชิปชิปเซ็ตซึ่งโดยทั่วไปเรียกว่า "สะพานเหนือ"
บัสโปรเซสเซอร์
โปรเซสเซอร์ใดๆ ก็ตามจำเป็นต้องติดตั้งบัสโปรเซสเซอร์ ซึ่งในสภาพแวดล้อมของ CPU x86 มักจะเรียกว่า FSB (Front Side Bus) บัสนี้ทำหน้าที่เป็นช่องทางการสื่อสารระหว่างโปรเซสเซอร์และอุปกรณ์อื่นๆ ทั้งหมดในคอมพิวเตอร์: หน่วยความจำ การ์ดแสดงผล ฮาร์ดไดรฟ์ และอื่นๆ อย่างไรก็ตาม ดังที่เราทราบแล้วจากหัวข้อที่แล้ว ระหว่างหน่วยความจำกับโปรเซสเซอร์จะมีตัวควบคุมหน่วยความจำ ดังนั้น: โปรเซสเซอร์สื่อสารผ่าน FSB ด้วยตัวควบคุมหน่วยความจำซึ่งในทางกลับกันจะสื่อสารผ่านบัสพิเศษ (เรียกว่า "บัสหน่วยความจำ") กับโมดูล RAM บนบอร์ดโดยไม่ต้องกังวลใจอีกต่อไป อย่างไรก็ตาม เราทำซ้ำอีกครั้ง: เนื่องจาก CPU x86 แบบคลาสสิกมีบัส "ภายนอก" เพียงอันเดียว จึงใช้ไม่เพียงสำหรับการทำงานกับหน่วยความจำเท่านั้น แต่ยังใช้สำหรับการสื่อสารระหว่างโปรเซสเซอร์และอุปกรณ์อื่น ๆ ทั้งหมดด้วย
ความแตกต่างระหว่างแบบดั้งเดิม
สถาปัตยกรรมซีพียู x86 และ K8/AMD64
แนวทางการปฏิวัติของ AMD นั้นอยู่ที่ความจริงที่ว่าโปรเซสเซอร์ที่มีสถาปัตยกรรม AMD64 (และสถาปัตยกรรมไมโครซึ่งเรียกตามอัตภาพว่า "K8") นั้นมาพร้อมกับบัส "ภายนอก" จำนวนมาก ในกรณีนี้ บัส HyperTransport หนึ่งหรือหลายบัสถูกใช้สำหรับการสื่อสารกับอุปกรณ์ทั้งหมดยกเว้นหน่วยความจำ และกลุ่มบัสหนึ่งหรือสองกลุ่มที่แยกจากกัน (ในกรณีของตัวควบคุมสองช่องสัญญาณ) ใช้สำหรับการทำงานของโปรเซสเซอร์กับหน่วยความจำโดยเฉพาะ ข้อดีของการรวมตัวควบคุมหน่วยความจำเข้ากับโปรเซสเซอร์โดยตรงนั้นชัดเจน: "เส้นทางจากคอร์ไปยังหน่วยความจำ" จะ "สั้นลง" อย่างเห็นได้ชัดซึ่งช่วยให้คุณทำงานกับ RAM ได้เร็วขึ้น จริงอยู่ที่วิธีนี้ก็มีข้อเสียเช่นกัน ตัวอย่างเช่นหากอุปกรณ์ก่อนหน้านี้ชอบ ฮาร์ดไดรฟ์หรือการ์ดแสดงผลสามารถทำงานกับหน่วยความจำผ่านคอนโทรลเลอร์อิสระเฉพาะ - ในกรณีของสถาปัตยกรรม AMD64 จะถูกบังคับให้ทำงานกับ RAM ผ่านคอนโทรลเลอร์ที่อยู่บนโปรเซสเซอร์ เนื่องจาก CPU ในสถาปัตยกรรมนี้เป็นอุปกรณ์เดียวที่เข้าถึงหน่วยความจำได้โดยตรง โดยพฤตินัย ในการเผชิญหน้า “ผู้ควบคุมภายนอกกับ... บูรณาการ” ความเท่าเทียมกันได้พัฒนาในด้านหนึ่ง ช่วงเวลานี้ AMD เป็นผู้ผลิตโปรเซสเซอร์เดสก์ท็อป x86 เพียงรายเดียวที่มีตัวควบคุมหน่วยความจำในตัว ในทางกลับกัน บริษัท ดูเหมือนจะค่อนข้างพอใจกับโซลูชันนี้และจะไม่ละทิ้งมัน ประการที่สาม Intel จะไม่ยอมแพ้คอนโทรลเลอร์ภายนอกและค่อนข้างพอใจกับ "รูปแบบคลาสสิก" ที่ได้รับการพิสูจน์มานานหลายปี
แกะ
ความกว้างบัสหน่วยความจำ ตัวควบคุมหน่วยความจำ N-channel
ณ วันนี้ หน่วยความจำทั้งหมดที่ใช้ในระบบเดสก์ท็อป x86 สมัยใหม่มีบัสแบบกว้าง 64 บิต ซึ่งหมายความว่าในรอบสัญญาณนาฬิกาหนึ่งรอบ สามารถส่งข้อมูลจำนวนหนึ่งซึ่งเป็นผลคูณของ 8 ไบต์ได้พร้อมกันบนบัสนี้ (8 ไบต์สำหรับบัส SDR, 16 ไบต์สำหรับบัส DDR) สิ่งเดียวที่โดดเด่นคือหน่วยความจำประเภท RDRAM ซึ่งใช้ในระบบที่ใช้โปรเซสเซอร์ Intel Pentium 4 ในช่วงเริ่มต้นของสถาปัตยกรรม NetBurst แต่ตอนนี้ทิศทางนี้ได้รับการยอมรับว่าเป็นทางตันสำหรับพีซี x86 (โดยวิธีการ บริษัทเดียวกันนี้ที่ Intel มีส่วนช่วยในเรื่องนี้ ซึ่งครั้งหนึ่งเคยส่งเสริมอย่างแข็งขัน ประเภทนี้หน่วยความจำ). ความสับสนบางอย่างเกิดขึ้นจากคอนโทรลเลอร์แบบดูอัลแชนเนลเท่านั้น ซึ่งให้การทำงานพร้อมกันกับบัส 64 บิตแยกกันสองตัว เนื่องจากผู้ผลิตบางรายอ้างว่าความสามารถ "128 บิต" บางอย่าง แน่นอนว่านี่เป็นการดูหมิ่นล้วนๆ อนิจจาเลขคณิตในระดับชั้นประถมศึกษาปีที่ 1 ใช้ไม่ได้ในกรณีนี้: 2x64 ไม่เท่ากับ 128 เลย ทำไม? ใช่ หากเพียงเพราะแม้แต่ CPU x86 ที่ทันสมัยที่สุด (ดูส่วนคำถามที่พบบ่อย “ส่วนขยาย 64 บิตของสถาปัตยกรรม x86 (IA32) แบบคลาสสิก” ด้านล่าง) ไม่สามารถทำงานกับบัส 128 บิตและการกำหนดแอดเดรส 128 บิตได้ พูดโดยคร่าวๆ: ถนนคู่ขนานสองสายที่เป็นอิสระ แต่ละสายกว้าง 2 เมตร สามารถให้รถสองคันผ่านไปพร้อมกันได้ กว้าง 2 เมตร - แต่ไม่มีทางใดทางหนึ่ง กว้าง 4 เมตร ในทำนองเดียวกัน ตัวควบคุมหน่วยความจำ N-channel สามารถเพิ่มความเร็วในการทำงานกับข้อมูล N ครั้ง (และในทางทฤษฎีมากกว่าในทางปฏิบัติ) - แต่ไม่มีทางที่จะเพิ่มความจุบิตของข้อมูลนี้ได้ ความกว้างบัสหน่วยความจำในคอนโทรลเลอร์สมัยใหม่ทั้งหมดที่ใช้ในระบบ x86 คือ 64 บิต - ไม่ว่าคอนโทรลเลอร์นี้จะอยู่ในชิปเซ็ตหรือในโปรเซสเซอร์ก็ตาม คอนโทรลเลอร์บางตัวมีช่องสัญญาณ 64 บิตอิสระสองช่อง แต่สิ่งนี้จะไม่ส่งผลต่อความกว้างบัสหน่วยความจำ แต่อย่างใด - เฉพาะความเร็วในการอ่านและเขียนข้อมูลเท่านั้น
ความเร็วในการอ่านและเขียน
ความเร็วในการอ่านและเขียนข้อมูลลงในหน่วยความจำในทางทฤษฎีนั้นถูกจำกัดโดยแบนด์วิธของหน่วยความจำเท่านั้น ตัวอย่างเช่นตัวควบคุมหน่วยความจำ DDR400 แบบดูอัลแชนเนลในทางทฤษฎีสามารถให้ความเร็วในการอ่านและเขียนข้อมูลเท่ากับ 8 ไบต์ (ความกว้างบัส) * 2 (จำนวนช่องสัญญาณ) * 2 (โปรโตคอล DDR ซึ่งช่วยให้มั่นใจได้ถึงการถ่ายโอนแพ็กเก็ตข้อมูล 2 ชุดต่อ รอบสัญญาณนาฬิกา) * 200"000"000 (ความถี่การทำงานจริงของบัสหน่วยความจำคือ 200 MHz นั่นคือ 200"000"000 รอบสัญญาณนาฬิกาต่อวินาที) ตามกฎแล้วค่าที่ได้รับจากการทดสอบภาคปฏิบัตินั้นต่ำกว่าค่าทางทฤษฎีเล็กน้อย: นี่เป็นเพราะการออกแบบตัวควบคุมหน่วยความจำที่ "ไม่สมบูรณ์" รวมถึงค่าโสหุ้ย (ความล่าช้า) ที่เกิดจากการทำงานของแคช ระบบย่อยของโปรเซสเซอร์เอง (ดูหัวข้อแคชของโปรเซสเซอร์ด้านล่าง) อย่างไรก็ตาม "การจับ" หลักไม่ได้อยู่ในการซ้อนทับที่เกี่ยวข้องกับการทำงานของตัวควบคุมและระบบย่อยแคช แต่ในความจริงที่ว่าความเร็วของการอ่านหรือการเขียน "เชิงเส้น" ไม่ใช่คุณลักษณะเดียวที่ส่งผลต่อความเร็วที่แท้จริงของ โปรเซสเซอร์ที่มี RAM เพื่อทำความเข้าใจว่าส่วนประกอบใดที่ประกอบเป็นความเร็วที่แท้จริงของโปรเซสเซอร์และหน่วยความจำ นอกเหนือจากความเร็วในการอ่านหรือเขียนเชิงเส้นแล้ว เรายังต้องคำนึงถึงคุณลักษณะดังกล่าวด้วย เวลาแฝง.
เวลาแฝง
เวลาแฝงนั้นมีความสำคัญไม่น้อยจากมุมมองของประสิทธิภาพของระบบย่อยหน่วยความจำมากกว่าความเร็วของ "การสูบข้อมูล" แต่มันแตกต่างอย่างสิ้นเชิงในสาระสำคัญ การแลกเปลี่ยนข้อมูลความเร็วสูงนั้นดีเมื่อมีขนาดค่อนข้างใหญ่ แต่หากเราต้องการ “ทีละน้อยจากที่อยู่ที่แตกต่างกัน” เวลาแฝงก็จะมาถึงเบื้องหน้า มันคืออะไร? โดยทั่วไปแล้ว เวลาที่ใช้ในการเริ่มอ่านข้อมูลจากที่อยู่ที่ระบุ และแน่นอน: ตั้งแต่ช่วงเวลาที่โปรเซสเซอร์ส่งคำสั่งอ่าน (เขียน) ไปยังตัวควบคุมหน่วยความจำจนถึงช่วงเวลาที่ดำเนินการนี้ ระยะเวลาหนึ่งจะผ่านไป ยิ่งไปกว่านั้นมันไม่เท่ากับเวลาที่ใช้ในการถ่ายโอนข้อมูลเลย เมื่อได้รับคำสั่งอ่านหรือเขียนจากโปรเซสเซอร์ ตัวควบคุมหน่วยความจำจะ "ระบุ" ไปยังที่อยู่ที่ต้องการใช้งาน การเข้าถึงที่อยู่โดยพลการใด ๆ ไม่สามารถทำได้ทันที สิ่งนี้จำเป็น เวลาที่แน่นอน. เกิดความล่าช้า: มีการระบุที่อยู่ แต่หน่วยความจำยังไม่พร้อมที่จะให้เข้าถึงได้ โดยทั่วไปความล่าช้านี้เรียกว่าเวลาแฝง มันแตกต่างกันไปตามหน่วยความจำประเภทต่างๆ ตัวอย่างเช่น หน่วยความจำ DDR2 มีโดยเฉลี่ยมาก ความล่าช้าเป็นเวลานานกว่า DDR (ที่ความถี่การรับส่งข้อมูลเดียวกัน) เป็นผลให้หากข้อมูลในโปรแกรมอยู่ในตำแหน่ง "วุ่นวาย" และอยู่ใน "ชิ้นเล็ก ๆ" ความเร็วในการอ่านข้อมูลจะมีความสำคัญน้อยกว่าความเร็วในการเข้าถึง "จุดเริ่มต้นของก้อน" เนื่องจากความล่าช้าเมื่อย้ายไปที่ ที่อยู่ถัดไปส่งผลต่อประสิทธิภาพของระบบมากกว่าความเร็วในการอ่านหรือเขียน
“การแข่งขัน” ระหว่างความเร็วในการอ่าน (เขียน) และเวลาแฝงถือเป็นหนึ่งในปัญหาใหญ่สำหรับนักพัฒนาระบบสมัยใหม่ น่าเสียดายที่ความเร็วในการอ่าน (เขียน) ที่เพิ่มขึ้นมักจะนำไปสู่การเพิ่มขึ้นของเวลาแฝงเสมอ ตัวอย่างเช่น หน่วยความจำประเภท SDR (PC66, PC100, PC133) มีความหน่วงที่ดีกว่า (ต่ำกว่า) โดยเฉลี่ยมากกว่า DDR ในทางกลับกัน DDR2 มีเวลาแฝงที่สูงกว่า (ซึ่งแย่กว่านั้น) มากกว่า DDR
ควรเข้าใจว่าเวลาแฝง "โดยรวม" ของระบบย่อยหน่วยความจำนั้นไม่เพียงขึ้นอยู่กับตัวมันเองเท่านั้น แต่ยังขึ้นอยู่กับตัวควบคุมหน่วยความจำและตำแหน่งของมันด้วย - ปัจจัยทั้งหมดเหล่านี้ยังส่งผลต่อเวลาแฝงด้วย นั่นคือเหตุผลที่ AMD ในกระบวนการพัฒนาสถาปัตยกรรม AMD64 ตัดสินใจแก้ไขปัญหาเวลาแฝงสูง "ในคราวเดียว" ด้วยการรวมคอนโทรลเลอร์เข้ากับโปรเซสเซอร์โดยตรง - เพื่อ "ลดระยะห่าง" ระหว่างคอร์โปรเซสเซอร์และ โมดูล RAM ให้มากที่สุด แนวคิดนี้ประสบความสำเร็จ แต่มีต้นทุนสูง ปัจจุบันระบบที่ใช้สถาปัตยกรรม CPU AMD64 เฉพาะสามารถทำงานได้กับหน่วยความจำที่คอนโทรลเลอร์ได้รับการออกแบบเท่านั้น นี่อาจเป็นสาเหตุที่ Intel ยังไม่ตัดสินใจที่จะดำเนินการขั้นตอนที่รุนแรงเช่นนี้ โดยเลือกที่จะใช้วิธีการแบบเดิม: การปรับปรุงตัวควบคุมหน่วยความจำในชิปเซ็ตและกลไกการดึงข้อมูลล่วงหน้าในโปรเซสเซอร์ (ดูรายละเอียดด้านล่าง)
โดยสรุป เราทราบว่าโดยทั่วไปแล้วแนวคิดของ "ความเร็วในการอ่าน / เขียน" และ "เวลาแฝง" นั้นใช้กับหน่วยความจำทุกประเภท - รวมถึงไม่เพียงแต่ DRAM แบบคลาสสิก (SDR, Rambus, DDR, DDR2) เท่านั้น แต่ยังรวมถึงแคชด้วย (ดู ด้านล่าง).
หน่วยประมวลผล: ข้อมูลทั่วไป
แนวคิดทางสถาปัตยกรรม
สถาปัตยกรรมเป็นความเข้ากันได้ของรหัส
แน่นอนว่าคุณมักจะเจอคำว่า "x86" หรือ "โปรเซสเซอร์ที่เข้ากันได้กับ Intel" (หรือ "เข้ากันได้กับ IBM PC" - แต่สิ่งนี้เกี่ยวข้องกับคอมพิวเตอร์) บางครั้งมีการใช้คำว่า "เข้ากันได้กับ Pentium" ด้วย (ทำไมถึงเป็น Pentium - คุณจะเข้าใจในภายหลัง) มีอะไรซ่อนอยู่หลังชื่อเหล่านี้จริงๆ? ในขณะนี้ สูตรง่ายๆ ต่อไปนี้ดูถูกต้องที่สุดจากมุมมองของผู้เขียน: โปรเซสเซอร์ x86 ที่ทันสมัยคือโปรเซสเซอร์ที่สามารถรันโค้ดเครื่องของสถาปัตยกรรม IA32 ได้อย่างถูกต้อง (สถาปัตยกรรมของโปรเซสเซอร์ Intel 32 บิต). ในการประมาณครั้งแรก นี่คือโค้ดที่ดำเนินการโดยโปรเซสเซอร์ i80386 (รู้จักกันทั่วไปในชื่อ "386") แต่ในที่สุดชุดคำสั่ง IA32 หลักก็ถูกสร้างขึ้นด้วยการเปิดตัวโปรเซสเซอร์ Intel Pentium Pro “ชุดหลัก” หมายถึงอะไร และยังมีอะไรบ้าง? ก่อนอื่นเรามาตอบคำถามส่วนแรกกันก่อน “พื้นฐาน” ในกรณีนี้หมายความว่าเพียงใช้ชุดคำสั่งนี้เท่านั้น โปรแกรมใดๆ ที่สามารถเขียนโดยทั่วไปสำหรับโปรเซสเซอร์ x86 (หรือ IA32 หากคุณต้องการ) ก็สามารถเขียนได้
นอกจากนี้ สถาปัตยกรรม IA32 ยังมีส่วนขยาย "อย่างเป็นทางการ" (ชุดคำสั่งเพิ่มเติม) จากผู้พัฒนาสถาปัตยกรรม Intel: MMX, SSE, SSE2 และ SSE3 นอกจากนี้ยังมีชุดคำสั่งเพิ่มเติมที่ “ไม่เป็นทางการ” (ไม่ใช่ของ Intel): EMMX, 3DNow! และขยาย 3DNow! - ได้รับการพัฒนาโดย AMD อย่างไรก็ตาม "เป็นทางการ" และ "ไม่เป็นทางการ" ในกรณีนี้เป็นแนวคิดที่เกี่ยวข้องกัน - โดยพฤตินัยทั้งหมดนี้มาจากข้อเท็จจริงที่ว่าส่วนขยายบางส่วนของชุดคำสั่งได้รับการยอมรับจาก Intel ในฐานะผู้พัฒนาชุดดั้งเดิมและบางส่วนเป็น ไม่ใช่ ในขณะที่นักพัฒนาซอฟต์แวร์ใช้สิ่งที่ดีที่สุดสำหรับพวกเขาทุกประการ มีกฎง่ายๆ ข้อหนึ่งเกี่ยวกับมารยาทที่ดีเมื่อพูดถึงชุดคำสั่งเพิ่มเติม: ก่อนที่จะใช้งาน โปรแกรมควรตรวจสอบว่าโปรเซสเซอร์รองรับชุดคำสั่งเหล่านั้นหรือไม่ บางครั้งการเบี่ยงเบนจากกฎนี้เกิดขึ้น (และอาจนำไปสู่การทำงานของโปรแกรมที่ไม่ถูกต้อง) แต่โดยแท้จริงแล้วนี่เป็นปัญหาของซอฟต์แวร์ที่เขียนไม่ถูกต้องไม่ใช่โปรเซสเซอร์
ชุดคำสั่งเพิ่มเติมมีไว้เพื่ออะไร? ประการแรก เพื่อเพิ่มประสิทธิภาพเมื่อดำเนินการบางอย่าง โดยทั่วไป คำสั่งหนึ่งจากชุดรองจะดำเนินการที่ต้องใช้โปรแกรมขนาดเล็กที่ประกอบด้วยคำสั่งจากชุดหลัก ตามกฎแล้วคำสั่งหนึ่งคำสั่งจะถูกดำเนินการโดยโปรเซสเซอร์เร็วกว่าลำดับที่แทนที่ อย่างไรก็ตาม ใน 99% ของกรณี ไม่มีอะไรที่ไม่สามารถทำได้โดยใช้คำสั่งพื้นฐานไม่สามารถทำได้โดยใช้คำสั่งจากชุดเพิ่มเติม.
ดังนั้นการตรวจสอบดังกล่าวข้างต้นโดยโปรแกรมเพื่อรองรับชุดคำสั่งเพิ่มเติมโดยโปรเซสเซอร์ควรทำหน้าที่ง่ายมาก: ตัวอย่างเช่นหากโปรเซสเซอร์รองรับ SSE เราจะนับอย่างรวดเร็วและใช้คำสั่งจากชุด SSE ถ้าไม่เช่นนั้นเราจะนับช้าลงโดยใช้คำสั่งจากชุดหลัก โปรแกรมที่เขียนอย่างถูกต้องจะต้องดำเนินการในลักษณะนี้ อย่างไรก็ตาม ตอนนี้แทบจะไม่มีใครตรวจสอบโปรเซสเซอร์สำหรับการรองรับ MMX เนื่องจาก CPU ทั้งหมดที่เปิดตัวในช่วง 5 ปีที่ผ่านมารับประกันว่าจะรองรับชุดนี้ เพื่อเป็นข้อมูลอ้างอิง ต่อไปนี้เป็นตารางที่สรุปข้อมูลเกี่ยวกับการสนับสนุนชุดคำสั่งเพิ่มเติมต่างๆ โดยโปรเซสเซอร์เดสก์ท็อปต่างๆ (ออกแบบมาสำหรับเดสก์ท็อปพีซี)
| ซีพียู | |||||||
| อินเทล เพนเทียม ทู | |||||||
| Intel Celeron สูงถึง 533 MHz | |||||||
| อินเทล เพนเทียม III | |||||||
| Intel Celeron 533-1400 เมกะเฮิรตซ์ | |||||||
| อินเทล เพนเทียม 4 | |||||||
| Intel Celeron จาก 1700 MHz | |||||||
| Intel Celeron D | |||||||
| Intel Pentium 4 eXtreme Edition | |||||||
| Intel Pentium eXtreme Edition | |||||||
| อินเทล เพนเทียม ดี | |||||||
| เอเอ็มดี K6 | |||||||
| เอเอ็มดี K6-2 | |||||||
| เอเอ็มดี K6-III | |||||||
| เอเอ็มดี แอธลอน | |||||||
| AMD Duron สูงถึง 900 MHz | |||||||
| เอเอ็มดี แอธลอน XP | |||||||
| AMD Duron จาก 1,000 MHz | |||||||
| AMD Athlon 64 / Athlon FX | |||||||
| เอเอ็มดี เซมพรอน | |||||||
| เอเอ็มดี แอธลอน 64 X2 | |||||||
| ผ่านทาง C3 |
*ขึ้นอยู่กับการปรับเปลี่ยน
ในขณะนี้ซอฟต์แวร์เดสก์ท็อปยอดนิยมทั้งหมด (ปฏิบัติการ ระบบวินโดวส์และ Linux ชุดสำนักงาน เกมส์คอมพิวเตอร์ฯลฯ) กำลังได้รับการพัฒนาสำหรับโปรเซสเซอร์ x86 โดยเฉพาะ มันทำงาน (ยกเว้นโปรแกรมที่ "ทำงานไม่ดี") บนโปรเซสเซอร์ x86 ใด ๆ ไม่ว่าใครจะเป็นคนสร้างก็ตาม ดังนั้น แทนที่จะใช้คำว่า "เข้ากันได้กับ Intel" หรือ "เข้ากันได้กับ Pentium" ซึ่งมุ่งเป้าไปที่ผู้พัฒนาสถาปัตยกรรมดั้งเดิม พวกเขาจึงเริ่มใช้ชื่อที่เป็นกลาง: "โปรเซสเซอร์ที่รองรับ x86", "โปรเซสเซอร์ที่มีสถาปัตยกรรม x86" ในกรณีนี้ “สถาปัตยกรรม” หมายถึงความเข้ากันได้กับชุดคำสั่งบางชุด กล่าวคือ “สถาปัตยกรรมตัวประมวลผลจากมุมมองของโปรแกรมเมอร์” มีการตีความคำเดียวกันอีกประการหนึ่ง
สถาปัตยกรรมที่เป็นคุณลักษณะของตระกูลโปรเซสเซอร์
“ Zhelezyachniki” - ผู้ที่ทำงานส่วนใหญ่ไม่ได้ใช้ซอฟต์แวร์ แต่ใช้ฮาร์ดแวร์เข้าใจ "สถาปัตยกรรม" ในลักษณะที่แตกต่างออกไปเล็กน้อย (แม้ว่าจะถูกต้องมากกว่าที่พวกเขาเรียกว่า "สถาปัตยกรรม" เรียกว่า "สถาปัตยกรรมไมโคร" แต่โดยพฤตินัยคำนำหน้า " micro" มักละเว้น) สำหรับพวกเขา “สถาปัตยกรรม CPU” คือชุดคุณสมบัติบางอย่างที่มีอยู่ในโปรเซสเซอร์ตระกูลทั้งหมด ซึ่งมักจะผลิตขึ้นเป็นเวลาหลายปี (หรืออีกนัยหนึ่งคือ “การออกแบบภายใน” “องค์กร” ของโปรเซสเซอร์เหล่านี้) ตัวอย่างเช่น ผู้เชี่ยวชาญ CPU x86 จะบอกคุณว่าโปรเซสเซอร์ที่มี ALU ทำงานที่ความถี่สองเท่า, บัส QDR, แคชติดตาม และอาจรองรับเทคโนโลยี Hyper-Threading นั้นเป็น "โปรเซสเซอร์สถาปัตยกรรม NetBurst" (ไม่ใช่ ตกใจกับคำศัพท์ที่ไม่คุ้นเคย - ทั้งหมดจะอธิบายในภายหลังเล็กน้อย) ก โปรเซสเซอร์อินเทล Pentium Pro, Pentium II และ Pentium III คือ "สถาปัตยกรรม P6" ดังนั้นแนวคิดของ "สถาปัตยกรรม" ที่เกี่ยวข้องกับโปรเซสเซอร์จึงค่อนข้างคลุมเครือ: สามารถเข้าใจได้ว่าเข้ากันได้กับชุดคำสั่งชุดเดียวและชุดโซลูชันฮาร์ดแวร์ที่มีอยู่ในกลุ่มโปรเซสเซอร์ที่ค่อนข้างกว้างบางกลุ่ม แน่นอนว่าความเป็นทวินิยมของแนวคิดพื้นฐานประการหนึ่งนั้นไม่สะดวกนัก แต่นี่คือวิธีที่เป็นอยู่ และไม่น่าจะมีอะไรเปลี่ยนแปลงในอนาคตอันใกล้นี้...
ส่วนขยาย 64 บิตของสถาปัตยกรรม x86 (IA32) แบบคลาสสิก
ไม่นานมานี้ ผู้ผลิตซีพียู x86 ชั้นนำทั้งสองรายได้ประกาศเทคโนโลยี* สองเทคโนโลยีที่แทบจะเหมือนกัน (อย่างไรก็ตาม AMD เลือกที่จะเรียกมันว่าสถาปัตยกรรม) ต้องขอบคุณซีพียู x86 (IA32) แบบคลาสสิกที่ได้รับสถานะ 64 บิต ในกรณีของเอเอ็มดี เทคโนโลยีนี้ได้รับชื่อ "AMD64" (สถาปัตยกรรม AMD 64 บิต) ในกรณีของ Intel - "EM64T" (เทคโนโลยีหน่วยความจำขยาย 64 บิต) นอกจากนี้ ผู้เฒ่าผู้มีเกียรติซึ่งคุ้นเคยกับประวัติของปัญหานี้บางครั้งใช้ชื่อ "x86-64" ซึ่งเป็นชื่อทั่วไปสำหรับส่วนขยาย 64 บิตทั้งหมดของสถาปัตยกรรม x86 โดยไม่เชื่อมโยงกับเครื่องหมายการค้าจดทะเบียนของผู้ผลิตรายใด โดยพฤตินัย การใช้หนึ่งในสามชื่อที่ให้ไว้ข้างต้นขึ้นอยู่กับความชอบส่วนบุคคลของผู้ใช้มากกว่าความแตกต่างที่แท้จริง เนื่องจากความแตกต่างระหว่าง AMD64 และ EM64T พอดีกับปลายเข็มที่บางมาก นอกจากนี้ AMD เองก็ได้เปิดตัวชื่อ "แบรนด์" "AMD64" เพียงไม่นานก่อนที่จะมีการประกาศโปรเซสเซอร์ของตัวเองที่ใช้สถาปัตยกรรมนี้และก่อนหน้านั้นก็ใช้ "x86-64" ที่เป็นกลางมากกว่าในเอกสารของตัวเองอย่างใจเย็น อย่างไรก็ตามไม่ทางใดก็ทางหนึ่งทุกอย่างก็ลงมาที่สิ่งหนึ่ง: การลงทะเบียนตัวประมวลผลภายในบางตัวกลายเป็น 64- บิตแทนที่จะเป็น 32- บิตคำสั่งรหัส x86 32- บิตได้รับอะนาล็อก 64- บิตนอกจากนี้จำนวน หน่วยความจำที่กำหนดแอดเดรสได้ (รวมถึงไม่เพียงแต่ทางกายภาพเท่านั้น แต่ยังรวมถึงเสมือนด้วย) เพิ่มขึ้นหลายครั้ง (เนื่องจากที่อยู่ได้รับรูปแบบ 64 บิตแทนที่จะเป็น 32 บิต) จำนวนการคาดเดาทางการตลาดในหัวข้อ "64-บิต" เกินขีดจำกัดที่สมเหตุสมผลทั้งหมด ดังนั้นเราควรพิจารณาถึงข้อดีของนวัตกรรมนี้อย่างใกล้ชิดเป็นพิเศษ ดังนั้น จริงๆ แล้วมีอะไรเปลี่ยนแปลงไปบ้าง และอะไรยังไม่เปลี่ยนแปลงบ้าง?
* - ข้อโต้แย้งที่ Intel "คัดลอก EM64T จาก AMD64 อย่างโจ่งแจ้ง" ไม่สามารถทนต่อคำวิจารณ์ได้ และไม่ใช่เลยเพราะมันไม่เป็นเช่นนั้น - แต่เพราะมันไม่ได้ "หน้าด้าน" เลย มีแนวคิดดังกล่าว: "ข้อตกลงการอนุญาตให้ใช้สิทธิข้าม" หากข้อตกลงดังกล่าวเกิดขึ้น หมายความว่าการพัฒนาทั้งหมดของบริษัทหนึ่งในพื้นที่หนึ่งจะพร้อมใช้งานสำหรับอีกบริษัทหนึ่งโดยอัตโนมัติ เช่นเดียวกับการพัฒนาของอีกบริษัทหนึ่งจะพร้อมใช้งานสำหรับบริษัทแรกโดยอัตโนมัติ Intel ใช้ประโยชน์จากการออกใบอนุญาตข้ามสายเพื่อพัฒนา EM64T โดยใช้ AMD64 เป็นพื้นฐาน (ซึ่งไม่มีใครปฏิเสธ) AMD ใช้ประโยชน์จากข้อตกลงเดียวกันนี้เพื่อแนะนำการรองรับชุดคำสั่งเพิ่มเติม SSE2 และ SSE3 ที่พัฒนาโดย Intel ให้กับโปรเซสเซอร์ และไม่มีอะไรน่าละอายในเรื่องนี้ เนื่องจากเราตกลงที่จะ "แบ่งปัน" การพัฒนา นั่นหมายความว่าเราต้องแบ่งปัน
อะไรไม่เปลี่ยนแปลง? ประการแรก ความเร็วของโปรเซสเซอร์ คงจะโง่เขลาอย่างเห็นได้ชัดหากสมมติว่าโปรเซสเซอร์เดียวกันเมื่อเปลี่ยนจากโหมด 32 บิตปกติเป็น 64 บิต (และซีพียู x86 ปัจจุบันทั้งหมดจำเป็นต้องรองรับโหมด 32 บิต) จะทำงานเร็วขึ้น 2 เท่า แน่นอนว่าในบางกรณี อาจมีการเร่งความเร็วจากการใช้เลขคณิตจำนวนเต็ม 64 บิต แต่กรณีเหล่านี้มีจำนวนจำกัดมาก และไม่มีผลกระทบกับซอฟต์แวร์ผู้ใช้สมัยใหม่ส่วนใหญ่ โดยวิธีการ: ทำไมเราถึงใช้คำว่า "เลขคณิตจำนวนเต็ม 64 บิต"? แต่เนื่องจากบล็อกของการดำเนินการจุดลอยตัว (ดูด้านล่าง) ในโปรเซสเซอร์ x86 ทั้งหมดจึงไม่ใช่แบบ 32 บิตอีกต่อไป และไม่ใช่ 64 บิตด้วยซ้ำ x87 FPU แบบคลาสสิก (ดูด้านล่าง) ซึ่งในที่สุดก็กลายเป็นส่วนหนึ่งของ CPU ในสมัยของ Intel Pentium 32 บิตรุ่นเก่าที่ดี - เป็น 80 บิตอยู่แล้ว. ตัวถูกดำเนินการของคำสั่ง SSE และ SSE2/3 เป็นแบบ 128 บิต! ในเรื่องนี้สถาปัตยกรรม x86 ค่อนข้างขัดแย้ง: แม้ว่าที่จริงแล้วโปรเซสเซอร์ของสถาปัตยกรรมนี้อย่างเป็นทางการยังคงเป็น 32 บิตมาเป็นเวลานาน - ความจุบิตของบล็อกเหล่านั้นโดยที่ "b โอ“ความจุบิตที่สูงขึ้น” เป็นสิ่งจำเป็นจริงๆ - มันถูกเพิ่มขึ้นโดยสิ้นเชิงโดยไม่ขึ้นอยู่กับส่วนที่เหลือ ตัวอย่างเช่น โปรเซสเซอร์ AMD Athlon XP และ Intel Pentium 4 “Northwood” รวมหน่วยที่ทำงานร่วมกับตัวถูกดำเนินการ 32 บิต 80 บิต และ 128 บิต เฉพาะชุดคำสั่งหลัก (สืบทอดมาจากโปรเซสเซอร์สถาปัตยกรรม IA32 ตัวแรก - Intel 386) และการกำหนดที่อยู่หน่วยความจำ (สูงสุด 4 กิกะไบต์ไม่นับ "ความวิปริต") เท่านั้นที่ยังคงเป็น 32 บิต ประเภทอินเทลพีเออี)
ดังนั้นความจริงที่ว่าโปรเซสเซอร์ AMD และ Intel กลายเป็น "อย่างเป็นทางการ 64 บิต" ในทางปฏิบัติทำให้เรามีการปรับปรุงเพียงสามประการเท่านั้น: การปรากฏตัวของคำสั่งสำหรับการทำงานกับจำนวนเต็ม 64 บิต, การเพิ่มจำนวนและ/หรือความลึกบิตของการลงทะเบียน และการเพิ่มขึ้นของหน่วยความจำวอลุ่มที่สามารถระบุตำแหน่งได้สูงสุด หมายเหตุ: ไม่มีใครปฏิเสธคุณประโยชน์ที่แท้จริงของนวัตกรรมเหล่านี้ (โดยเฉพาะประการที่สาม!) เช่นเดียวกับที่ไม่มีใครปฏิเสธข้อดีของ AMD ในการส่งเสริมแนวคิด "การปรับปรุงให้ทันสมัย" (เนื่องจากการเปิดตัวโปรเซสเซอร์ x86 แบบ 64 บิต) เราแค่อยากเตือนถึงความคาดหวังที่มากเกินไป: คุณไม่ควรหวังว่าคอมพิวเตอร์ที่ซื้อ "ในระดับราคา VAZ" จะกลายเป็น "Mercedes ที่ห้าวหาญ" โดยไม่ต้องติดตั้งซอฟต์แวร์ 64 บิต ปาฏิหาริย์ไม่มีในโลก...
แกนประมวลผล
ความแตกต่างระหว่างคอร์ของสถาปัตยกรรมไมโครเดียวกัน
"แกนประมวลผล" (โดยปกติจะเรียกง่ายๆ ว่า "แกนกลาง" สำหรับความกะทัดรัด) เป็นรูปลักษณ์เฉพาะของสถาปัตยกรรม [ไมโคร] (นั่นคือ "สถาปัตยกรรมในความหมายเชิงฮาร์ดแวร์ของคำนี้") ที่เป็นมาตรฐานสำหรับทั้งซีรีส์ ของโปรเซสเซอร์ ตัวอย่างเช่น NetBurst เป็นสถาปัตยกรรมไมโครที่รองรับโปรเซสเซอร์ Intel จำนวนมากในปัจจุบัน: Celeron, Pentium 4, Xeon สถาปัตยกรรมไมโครกำหนดหลักการทั่วไป: ไปป์ไลน์ที่ยาว การใช้แคชโค้ดระดับแรกบางประเภท (แคชติดตาม) และคุณสมบัติ "ทั่วโลก" อื่นๆ แกนกลางเป็นรูปลักษณ์ที่เฉพาะเจาะจงมากขึ้น ตัวอย่างเช่น โปรเซสเซอร์ของสถาปัตยกรรมไมโคร NetBurst ที่มีบัส 400 MHz, แคชระดับที่สอง 256 กิโลไบต์ และไม่รองรับ Hyper-Threading นี่เป็นคำอธิบายที่สมบูรณ์ของคอร์ Willamette ไม่มากก็น้อย แต่คอร์ Northwood มีแคชระดับที่สองที่ 512 กิโลไบต์ แม้ว่าจะอิงจาก NetBurst ก็ตาม แกนประมวลผล AMD Thunderbird ใช้สถาปัตยกรรมไมโคร K7 แต่ไม่รองรับชุดคำสั่ง SSE แต่แกนประมวลผล Palomino รองรับ
ดังนั้นเราสามารถพูดได้ว่า "แกนกลาง" เป็นศูนย์รวมเฉพาะของสถาปัตยกรรมไมโครบางอย่าง "ในซิลิคอน" ซึ่งมี (ตรงกันข้ามกับสถาปัตยกรรมไมโครเอง) ชุดคุณลักษณะที่กำหนดไว้อย่างเคร่งครัด สถาปัตยกรรมไมโครนั้นไม่มีรูปร่าง ซึ่งอธิบายหลักการทั่วไปของการออกแบบโปรเซสเซอร์ แกนกลางโดยเฉพาะคือสถาปัตยกรรมไมโคร "รก" พร้อมด้วยพารามิเตอร์และคุณลักษณะทุกประเภท เป็นเรื่องยากมากที่โปรเซสเซอร์จะเปลี่ยนสถาปัตยกรรมไมโครในขณะที่ยังคงชื่อเดิมไว้ และในทางกลับกัน ชื่อโปรเซสเซอร์เกือบทุกชื่อได้ "เปลี่ยน" แกนหลักอย่างน้อยหลายครั้งในระหว่างที่มีอยู่ ตัวอย่างเช่นชื่อทั่วไปของซีรีส์โปรเซสเซอร์ AMD คือ "Athlon XP" - นี่คือสถาปัตยกรรมไมโครหนึ่งตัว (K7) แต่มีมากถึงสี่คอร์ (Palomino, Thoroughbred, Barton, Thorton) เคอร์เนลที่แตกต่างกันที่สร้างขึ้นบนสถาปัตยกรรมไมโครเดียวกันอาจมีระดับประสิทธิภาพที่แตกต่างกัน
การตรวจสอบ
การแก้ไขคือหนึ่งในการแก้ไขเคอร์เนล ซึ่งแตกต่างไปเล็กน้อยจากการแก้ไขครั้งก่อน ซึ่งเป็นสาเหตุที่ทำให้ไม่สมควรได้รับฉายาว่า "เคอร์เนลใหม่" ตามกฎแล้วผู้ผลิตโปรเซสเซอร์ไม่ได้สร้างเรื่องใหญ่จากการเปิดตัวการแก้ไขครั้งถัดไป มันเกิดขึ้น "ในลำดับการทำงาน" ดังนั้นแม้ว่าคุณจะซื้อโปรเซสเซอร์ตัวเดียวกันซึ่งมีชื่อและคุณสมบัติคล้ายกันมาก แต่ด้วยช่วงเวลาประมาณหกเดือนก็ค่อนข้างเป็นไปได้ที่ในความเป็นจริงมันจะแตกต่างออกไปเล็กน้อย การเปิดตัวการแก้ไขใหม่มักจะเกี่ยวข้องกับการปรับปรุงเล็กๆ น้อยๆ บางประการ ตัวอย่างเช่น เราสามารถลดการใช้พลังงานลงได้เล็กน้อย หรือลดแรงดันไฟฟ้าลง หรือเพิ่มประสิทธิภาพอย่างอื่น หรือข้อผิดพลาดเล็กๆ น้อยๆ สองสามข้อถูกกำจัดออกไป จากมุมมองของประสิทธิภาพ เราจำไม่ได้ว่ามีตัวอย่างเดียวที่การแก้ไขเคอร์เนลหนึ่งแตกต่างจากที่อื่นอย่างมีนัยสำคัญมากจนสมเหตุสมผลที่จะพูดถึงมัน แม้ว่าตัวเลือกนี้จะเป็นไปได้ในทางทฤษฎีล้วนๆ - ตัวอย่างเช่น บล็อกตัวประมวลผลตัวใดตัวหนึ่งที่รับผิดชอบในการรันคำสั่งหลายคำสั่งได้รับการปรับปรุงให้เหมาะสม โดยสรุป เราสามารถพูดได้ว่าบ่อยครั้งที่การแก้ไขโปรเซสเซอร์ไม่คุ้มค่า: ในกรณีที่หายากมาก การเปลี่ยนแปลงการแก้ไขทำให้เกิดการเปลี่ยนแปลงพื้นฐานบางอย่างกับโปรเซสเซอร์ แค่รู้ว่ามีสิ่งนั้นอยู่ก็เพียงพอแล้ว - สำหรับเท่านั้น การพัฒนาทั่วไป.
ความถี่หลัก
ตามกฎแล้ว พารามิเตอร์นี้เรียกขานว่า "ความถี่ของโปรเซสเซอร์" แม้ว่าในกรณีทั่วไป คำจำกัดความของ "ความถี่การทำงานของคอร์" ยังคงถูกต้องมากกว่า เนื่องจากไม่จำเป็นเลยที่ส่วนประกอบทั้งหมดของ CPU จะทำงานที่ความถี่เดียวกันกับคอร์ (ตัวอย่างที่พบบ่อยที่สุดของสิ่งที่ตรงกันข้ามคือแบบเก่า ซีพียู "สล็อต" x86 - Intel Pentium II และ Pentium III สำหรับสล็อต 1, AMD Athlon สำหรับสล็อต A - แคช L2 ทำงานที่ 1/2 และบางครั้งก็อยู่ที่ 1/3 ของความถี่คอร์) ความเข้าใจผิดที่พบบ่อยอีกประการหนึ่งคือความเชื่อที่ว่าความถี่คอร์เป็นตัวกำหนดประสิทธิภาพโดยเฉพาะ ในความเป็นจริง นี่เป็นสิ่งที่ผิดสองครั้ง: ประการแรก แต่ละคอร์ของโปรเซสเซอร์เฉพาะ (ขึ้นอยู่กับวิธีการออกแบบ จำนวนหน่วยประมวลผลที่ประกอบด้วย หลากหลายชนิดฯลฯ ฯลฯ) สามารถดำเนินการคำสั่งจำนวนที่แตกต่างกันในรอบสัญญาณนาฬิกาหนึ่งรอบ แต่ความถี่เป็นเพียงจำนวนรอบสัญญาณนาฬิกาดังกล่าวต่อวินาที ดังนั้น (แน่นอนว่าการเปรียบเทียบด้านล่างนั้นง่ายมากและเป็นไปตามอำเภอใจมาก) โปรเซสเซอร์ที่คอร์ดำเนินการ 3 คำสั่งต่อรอบสัญญาณนาฬิกาสามารถมีความถี่ต่ำกว่าโปรเซสเซอร์ที่ดำเนินการ 2 คำสั่งต่อรอบสัญญาณนาฬิกาถึงสามเท่า - และในเวลาเดียวกันก็มี ประสิทธิภาพใกล้เคียงกันโดยสิ้นเชิง
ประการที่สอง แม้จะอยู่ในคอร์เดียวกัน การเพิ่มความถี่ไม่ได้ทำให้ประสิทธิภาพเพิ่มขึ้นตามสัดส่วนเสมอไป ความรู้ที่คุณสามารถรวบรวมได้จากหัวข้อ "หลักการทั่วไปของการโต้ตอบระหว่างโปรเซสเซอร์และ RAM" จะมีประโยชน์มากสำหรับคุณ ความจริงก็คือความเร็วของการดำเนินการคำสั่งโดยแกนประมวลผลไม่ใช่ตัวบ่งชี้เดียวที่ส่งผลต่อความเร็วของการทำงานของโปรแกรม สิ่งสำคัญไม่แพ้กันคือความเร็วที่คำสั่งและข้อมูลมาถึง CPU ตามทฤษฎีแล้ว ลองจินตนาการถึงระบบดังกล่าว: ความเร็วโปรเซสเซอร์คือ 10,000 คำสั่งต่อวินาที ความเร็วหน่วยความจำคือ 1,000 ไบต์ต่อวินาที คำถาม: แม้ว่าเราจะถือว่าหนึ่งคำสั่งใช้ไม่เกินหนึ่งไบต์และเราก็ไม่ ข้อมูลเลยโปรแกรมจะถูกดำเนินการในระบบดังกล่าวด้วยความเร็วเท่าใด ถูกต้อง: ไม่เกิน 1,000 คำสั่งต่อวินาทีและประสิทธิภาพของ CPU ไม่เกี่ยวข้องเลย: เราจะไม่ถูก จำกัด ด้วยมัน แต่ด้วยความเร็ว ที่คำสั่งใดเข้าสู่โปรเซสเซอร์ ดังนั้นคุณควรเข้าใจ: เป็นไปไม่ได้ที่จะเพิ่มความถี่คอร์เดียวอย่างต่อเนื่องโดยไม่ต้องเร่งระบบย่อยหน่วยความจำพร้อมกันเนื่องจากในกรณีนี้โดยเริ่มจากขั้นตอนหนึ่งการเพิ่มความถี่ CPU จะไม่ส่งผลกระทบต่อ เพิ่มประสิทธิภาพของระบบโดยรวม
คุณสมบัติของการสร้างชื่อโปรเซสเซอร์
ก่อนหน้านี้ เมื่อท้องฟ้าเป็นสีฟ้า เบียร์ก็อร่อยขึ้น และเด็กผู้หญิงก็สวยขึ้น โปรเซสเซอร์ก็ถูกเรียกง่ายๆ ว่า: ชื่อผู้ผลิต + ชื่อ ช่วงโมเดล+ ความถี่ ตัวอย่างเช่น: "AMD K6-2 450 MHz" ในปัจจุบัน ผู้ผลิตรายใหญ่ทั้งสองได้เลิกใช้ประเพณีนี้ และแทนที่จะใช้ความถี่ พวกเขาใช้ตัวเลขที่เข้าใจยากซึ่งระบุว่าใครจะรู้อะไร สองส่วนถัดไปจะอธิบายสั้นๆ ว่าตัวเลขเหล่านี้หมายถึงอะไรจริงๆ
คะแนนจากเอเอ็มดี
เหตุผลที่ AMD "ลบ" ความถี่ออกจากชื่อโปรเซสเซอร์และแทนที่ด้วยหมายเลขนามธรรมบางส่วนเป็นที่รู้จักกันดี: หลังจากการปรากฏตัวของโปรเซสเซอร์ Intel Pentium 4 ซึ่งทำงานที่ความถี่สูงมาก โปรเซสเซอร์ AMD ถัดจากนั้นก็เริ่มที่จะ “ ดูแย่ในหน้าต่างร้านค้า” - ผู้ซื้อไม่เชื่อว่า CPU ที่มีความถี่เช่น 1500 MHz สามารถแซงหน้า CPU ที่มีความถี่ 2000 MHz ได้ ดังนั้นความถี่ในชื่อจึงถูกแทนที่ด้วยการให้คะแนน การตีความอย่างเป็นทางการ (“โดยนิตินัย” เพื่อพูด) ของการให้คะแนนนี้จาก AMD ฟังดูแตกต่างออกไปเล็กน้อยในเวลาที่ต่างกัน แต่ไม่เคยฟังในรูปแบบที่ผู้ใช้รับรู้: โปรเซสเซอร์ AMD ที่มีคะแนนที่แน่นอนควรเป็นอย่างน้อย ไม่ช้ากว่าโปรเซสเซอร์ Intel Pentium 4 ที่มีความถี่สอดคล้องกับระดับนี้ ในขณะเดียวกัน มันไม่ได้เป็นความลับสำหรับทุกคนที่การตีความนี้เป็นเป้าหมายสูงสุดในการแนะนำการจัดอันดับ โดยทั่วไปแล้วทุกคนเข้าใจทุกอย่างอย่างสมบูรณ์แบบ แต่ AMD แกล้งทำเป็นว่าไม่มีส่วนเกี่ยวข้องกับมัน :) เธอไม่ควรถูกตำหนิในเรื่องนี้: ในการแข่งขัน มีการใช้กฎที่แตกต่างอย่างสิ้นเชิงจากการต่อสู้แบบอัศวิน นอกจากนี้ผลการทดสอบอิสระแสดงให้เห็นว่า: โดยทั่วไปแล้ว AMD จะให้คะแนนโปรเซสเซอร์อย่างยุติธรรม จริงๆ แล้ว ตราบใดที่เป็นเช่นนั้น ก็แทบจะไม่สมเหตุสมผลเลยที่จะประท้วงต่อต้านการใช้การให้คะแนน จริงอยู่คำถามหนึ่งยังคงเปิดอยู่: อะไร (แน่นอนว่าเราสนใจในสถานะโดยพฤตินัยและไม่ได้อยู่ในคำอธิบายของฝ่ายการตลาด) การจัดอันดับของโปรเซสเซอร์ AMD จะเชื่อมโยงกับในภายหลังเล็กน้อยเมื่อ Intel เริ่มผลิตบางส่วน โปรเซสเซอร์อื่นแทน Pentium 4?
หมายเลขโปรเซสเซอร์จาก Intel
สิ่งที่คุณต้องจำทันที: หมายเลขโปรเซสเซอร์ (ต่อไปนี้จะเรียกว่า PN) สำหรับโปรเซสเซอร์ Intel ไม่ใช่การจัดอันดับ ไม่ใช่การจัดอันดับประสิทธิภาพหรือการจัดอันดับสิ่งอื่นใด ในความเป็นจริง มันเป็นเพียง "รายการ" ซึ่งเป็นรายการในรายการสินค้าคงคลังที่มีวัตถุประสงค์เพียงอย่างเดียวเพื่อให้แน่ใจว่าบรรทัดที่เป็นตัวแทนของโปรเซสเซอร์ตัวหนึ่งแตกต่างจากบรรทัดที่แสดงถึงอีกตัวหนึ่ง ภายในอนุกรม (PN หลักตัวแรก) โดยหลักการแล้วอีกสองหลักสามารถพูดอะไรบางอย่างได้ แต่เมื่อพิจารณาถึงตารางที่แสดงความสอดคล้องกันอย่างสมบูรณ์ระหว่าง PN และพารามิเตอร์จริง เราไม่เห็นประเด็นมากนักในการจดจำซึ่ง - สิ่งเหล่านี้คือ จดหมายโต้ตอบระดับกลาง แรงจูงใจของ Intel ในการใช้ PN (แทนที่จะระบุความถี่ของ CPU) นั้นซับซ้อนกว่าของ AMD ความจำเป็นในการแนะนำ PN (ตามที่ Intel อธิบายเอง) สาเหตุหลักมาจากการที่คู่แข่งหลักทั้งสองมีแนวทางที่แตกต่างกันในประเด็นเรื่องเอกลักษณ์ของชื่อ CPU ตัวอย่างเช่น สำหรับ AMD ชื่อ “Athlon 64 3200+” อาจหมายถึงโปรเซสเซอร์สี่ตัวที่แตกต่างกันเล็กน้อย ลักษณะทางเทคนิค(แต่มี "เรตติ้งเท่ากัน") Intel มีความเห็นว่าชื่อของโปรเซสเซอร์ต้องไม่ซ้ำกัน ดังนั้นก่อนหน้านี้บริษัทจึงต้อง "หลบ" โดยการเพิ่มตัวอักษรที่แตกต่างกันให้กับค่าความถี่ในชื่อ ซึ่งทำให้เกิดความสับสน ตามทฤษฎีแล้ว PN ควรขจัดความสับสนนี้ออกไป เป็นการยากที่จะบอกว่าบรรลุเป้าหมายหรือไม่ แต่ช่วงของโปรเซสเซอร์ Intel ยังคงค่อนข้างซับซ้อน ในทางกลับกันสิ่งนี้เป็นสิ่งที่หลีกเลี่ยงไม่ได้เนื่องจากผลิตภัณฑ์มีให้เลือกมากมาย อย่างไรก็ตามโดยไม่คำนึงถึงสิ่งอื่นใดบรรลุผลโดยพฤตินัยเพียงอย่างเดียว: ตอนนี้มีเพียงผู้เชี่ยวชาญที่เข้าใจปัญหาเท่านั้นที่สามารถพูดว่า "จากหน่วยความจำ" ได้อย่างรวดเร็วและแม่นยำด้วยชื่อของโปรเซสเซอร์ว่ามันคืออะไรและประสิทธิภาพจะเป็นอย่างไรเมื่อเปรียบเทียบกับโปรเซสเซอร์อื่น ๆ ซีพียู มันดีแค่ไหน? ยากที่จะบอก เราอยากจะงดเว้นจากการแสดงความคิดเห็น
การวัดความเร็ว "เป็นเมกะเฮิรตซ์" - เป็นไปได้อย่างไร
สิ่งนี้ไม่มีทางเป็นไปได้ เนื่องจากความเร็วไม่ได้วัดเป็นเมกะเฮิรตซ์ เช่นเดียวกับระยะทางไม่ได้วัดเป็นกิโลกรัม อย่างไรก็ตาม นักการตลาดที่เป็นสุภาพบุรุษเข้าใจมานานแล้วว่าในการดวลด้วยวาจาระหว่างนักฟิสิกส์และนักจิตวิทยา ฝ่ายหลังจะชนะเสมอ - และไม่ว่าใครจะพูดถูกก็ตาม นั่นเป็นเหตุผลที่เราอ่านเกี่ยวกับ "ultra-fast 1,066 MHz FSB" ซึ่งพยายามทำความเข้าใจอย่างเจ็บปวดว่าสามารถวัดความเร็วโดยใช้ความถี่ได้อย่างไร ในความเป็นจริง เนื่องจากแนวโน้มในทางที่ผิดดังกล่าวได้หยั่งรากลึกไปแล้ว คุณเพียงแค่ต้องชัดเจนว่ามันหมายถึงอะไร สิ่งที่เราหมายถึงมีดังต่อไปนี้: ถ้าเรา "แก้ไข" ความกว้างของบัสเป็น N บิต ปริมาณงานของมันจะขึ้นอยู่กับความถี่ที่บัสทำงานและปริมาณข้อมูลที่สามารถส่งต่อรอบสัญญาณนาฬิกาได้ บนบัสโปรเซสเซอร์ปกติที่มีความเร็ว "เดี่ยว" (เช่นบัสเช่นโปรเซสเซอร์ Intel Pentium III) 64 บิตซึ่งก็คือ 8 ไบต์จะถูกถ่ายโอนต่อรอบสัญญาณนาฬิกา ตามนั้น ถ้า ความถี่ในการทำงานบัสคือ 100 MHz (100"000"000 รอบสัญญาณนาฬิกาต่อวินาที) - ดังนั้นอัตราการถ่ายโอนข้อมูลจะเท่ากับ 8 ไบต์ * 100"000"000 เฮิรตซ์ ~= 763 เมกะไบต์ต่อวินาที (และถ้าเรานับเป็น "เมกะไบต์ทศนิยม" ซึ่งเป็นธรรมเนียมที่จะต้องนับ กระแสข้อมูลแล้วสวยงามยิ่งขึ้น - 800 เมกะไบต์ต่อวินาที) ดังนั้น หากบัส DDR ทำงานที่ 100 เมกะเฮิรตซ์เท่ากัน ซึ่งสามารถส่งข้อมูลได้เป็นสองเท่าในรอบสัญญาณนาฬิกาหนึ่งรอบ ความเร็วจะเพิ่มขึ้นสองเท่าอย่างแน่นอน ดังนั้นตามตรรกะที่ขัดแย้งกันของนักการตลาดสุภาพบุรุษ บัสนี้จึงควรเรียกว่า "200 MHz" และถ้าเป็นบัส QDR (Quad Data Rate) ด้วย จริงๆ แล้วจะกลายเป็น "400 MHz" เนื่องจากมันจะส่งแพ็กเก็ตข้อมูลสี่แพ็กเก็ตในรอบสัญญาณนาฬิกาเดียว แม้ว่าความถี่ในการใช้งานจริงของรถโดยสารทั้งสามคันที่อธิบายไว้ข้างต้นจะเท่ากัน - 100 เมกะเฮิรตซ์นี่คือวิธีที่ "เมกะเฮิรตซ์" มีความหมายเหมือนกันกับความเร็ว
ดังนั้นบัส QDR (ด้วยความเร็ว "สี่เท่า") ซึ่งทำงานที่ความถี่จริง 266 เมกะเฮิรตซ์จึงกลายเป็น "1,066 เมกะเฮิรตซ์" อย่างน่าอัศจรรย์ หมายเลข "1,066" ในกรณีนี้แสดงถึงปริมาณงานเป็น 4 เท่าของบัส "ความเร็วเดียว" ที่ทำงานที่ความถี่เดียวกัน สับสนกันหรือยัง?.. ชินซะ! นี่ไม่ใช่ทฤษฎีสัมพัทธภาพบางประเภท ทุกอย่างที่นี่ซับซ้อนกว่าและถูกละเลยมากกว่ามาก... อย่างไรก็ตาม สิ่งสำคัญที่สุดในที่นี้คือการจดจำหลักการง่ายๆ ข้อเดียว: หากเรากำลังทำสิ่งที่บิดเบือนเช่นการเปรียบเทียบความเร็วของรถเมล์สองคันกับ ซึ่งกันและกัน “เป็นเมกะเฮิรตซ์” แล้วจะต้องมีความกว้างเท่ากัน มิฉะนั้นปรากฎว่าเหมือนในฟอรัมเดียวซึ่งมีคนโต้แย้งอย่างจริงจังว่าปริมาณงานของ AGP2X (“ 133 MHz” แต่ 32 บิตบัส) - สูงกว่าแบนด์วิดท์ FSB ของ Pentium III 800 (ความถี่จริง 100 MHz, ความกว้าง 64 บิต).
คำไม่กี่คำเกี่ยวกับคุณสมบัติที่น่าสนใจของโปรโตคอล DDR และ QDR
ตามที่กล่าวไว้ข้างต้น ในโหมด DDR ปริมาณข้อมูลจะถูกส่งผ่านบัสเป็นสองเท่าในรอบสัญญาณนาฬิกาหนึ่งรอบ และในโหมด QDR ข้อมูลจะถูกส่งเป็นสี่เท่า จริงอยู่ที่ในเอกสารที่เน้นไปที่การเชิดชูความสำเร็จของผู้ผลิตมากกว่าการครอบคลุมความเป็นจริงตามวัตถุประสงค์ ด้วยเหตุผลบางอย่างพวกเขามักจะลืมระบุสิ่งเล็กๆ น้อยๆ ว่า "แต่": โหมดความเร็วสองเท่าและสี่เท่าจะเปิดใช้งานระหว่างการถ่ายโอนข้อมูลแพ็คเก็ตเท่านั้น. นั่นคือ ถ้าเราขอหน่วยความจำสองสามเมกะไบต์จากที่อยู่ X ไปยังที่อยู่ Y ใช่แล้ว สองเมกะไบต์นี้จะถูกถ่ายโอนด้วยความเร็วสองเท่าหรือสี่เท่า แต่คำขอข้อมูลนั้นจะถูกส่งผ่านบัสด้วยความเร็ว "เดียว" - เสมอ ! ดังนั้นหากเรามีคำขอจำนวนมากและขนาดของข้อมูลที่ส่งไม่ใหญ่มาก จำนวนข้อมูลที่ "เดินทาง" ไปตามบัสด้วยความเร็วเดียว (และคำขอก็เป็นข้อมูลด้วย) จะเกือบจะ เท่ากับจำนวนที่ส่งด้วยความเร็วสองเท่าหรือสี่เท่า ดูเหมือนว่าไม่มีใครโกหกเราอย่างเปิดเผย ดูเหมือนว่า DDR และ QDR จะใช้งานได้จริง แต่... อย่างที่พวกเขาพูดในเรื่องตลกเก่า ๆ เรื่องหนึ่ง: "เขาขโมยเสื้อคลุมขนสัตว์จากใครบางคน หรือมีคนขโมยเสื้อคลุมขนสัตว์จากเขา แต่มีบางอย่างผิดปกติกับเสื้อคลุมขนสัตว์..." ;)
โปรเซสเซอร์บล็อกขนาดใหญ่
แคช
คำอธิบายทั่วไปและหลักการทำงาน
โปรเซสเซอร์สมัยใหม่ทั้งหมดมีแคช (ภาษาอังกฤษ - แคช) แคชเป็นหน่วยความจำประเภทพิเศษ (คุณสมบัติหลักที่ทำให้แคชแตกต่างจาก RAM โดยพื้นฐานคือความเร็วการทำงาน) ซึ่งเป็น "บัฟเฟอร์" ประเภทหนึ่งระหว่างตัวควบคุมหน่วยความจำและโปรเซสเซอร์ บัฟเฟอร์นี้ใช้เพื่อเพิ่มความเร็วในการทำงานกับ RAM ยังไง? ทีนี้มาลองอธิบายกัน ในเวลาเดียวกันเราตัดสินใจที่จะละทิ้งการเปรียบเทียบที่เหมือนโรงเรียนอนุบาลซึ่งมักพบในวรรณกรรมยอดนิยมเกี่ยวกับหัวข้อตัวประมวลผล (สระว่ายน้ำที่เชื่อมต่อกันด้วยท่อที่มีเส้นผ่านศูนย์กลางต่างกัน ฯลฯ ฯลฯ ) ท้ายที่สุดแล้ว คนที่อ่านบทความจนถึงจุดนี้และไม่เผลอหลับไปก็น่าจะสามารถยืนหยัดและ "แยกแยะ" คำอธิบายทางเทคนิคล้วนๆ ได้ โดยไม่ต้องมีสระว่ายน้ำ แมว และดอกแดนดิไลออน
ลองจินตนาการว่าเรามีหน่วยความจำที่ค่อนข้างช้าจำนวนมาก (ปล่อยให้เป็น RAM ขนาด 10,000,000 ไบต์) และมีหน่วยความจำที่เร็วมากค่อนข้างน้อย (ปล่อยให้เป็นแคชขนาดเพียง 1,024 ไบต์) เราจะใช้กิโลไบต์ที่โชคร้ายนี้เพื่อเพิ่มความเร็วในการทำงานกับหน่วยความจำทั้งหมดโดยทั่วไปได้อย่างไร แต่ที่นี่ควรจำไว้ว่าตามกฎแล้วข้อมูลระหว่างการทำงานของโปรแกรมไม่ได้ถูกโยนจากที่หนึ่งไปยังอีกที่หนึ่งโดยไม่ได้ตั้งใจ - มัน เปลี่ยน. พวกเขาอ่านค่าของตัวแปรบางตัวจากหน่วยความจำ เพิ่มตัวเลขเข้าไป และเขียนกลับไปไว้ที่เดิม เรานับอาร์เรย์ จัดเรียงตามลำดับจากน้อยไปหามาก และเขียนลงในหน่วยความจำอีกครั้ง นั่นคือถึงจุดหนึ่งโปรแกรมไม่ทำงานกับหน่วยความจำทั้งหมด แต่ตามกฎแล้วจะมีส่วนที่ค่อนข้างเล็ก วิธีแก้ปัญหาใดแนะนำตัวเอง? ถูกต้อง: โหลดแฟรกเมนต์นี้ลงในหน่วยความจำ "เร็ว" ประมวลผลที่นั่น จากนั้นเขียนกลับไปยังหน่วยความจำ "ช้า" (หรือเพียงแค่ลบออกจากแคชหากข้อมูลไม่มีการเปลี่ยนแปลง) โดยทั่วไปนี่คือวิธีการทำงานของแคชโปรเซสเซอร์: ข้อมูลใด ๆ ที่อ่านจากหน่วยความจำไม่เพียงจบลงในโปรเซสเซอร์เท่านั้น แต่ยังอยู่ในแคชด้วย และหากต้องการข้อมูลเดียวกัน (ที่อยู่เดียวกันในหน่วยความจำ) อีกครั้ง โปรเซสเซอร์จะตรวจสอบก่อนว่า อยู่ในแคชหรือไม่ หากมี ข้อมูลจะถูกนำมาจากที่นั่น และการเข้าถึงหน่วยความจำจะไม่เกิดขึ้นเลย ในทำนองเดียวกันกับการเขียน: ข้อมูลหากปริมาณของมันพอดีกับแคชจะถูกเขียนที่นั่น และเมื่อโปรเซสเซอร์เสร็จสิ้นการดำเนินการเขียนและเริ่มดำเนินการคำสั่งอื่น ๆ ข้อมูลที่เขียนลงในแคชก็จะถูกเขียน ควบคู่ไปกับการทำงานของแกนประมวลผล“ยกเลิกการโหลดอย่างช้าๆ” ลงใน RAM
แน่นอนว่าปริมาณข้อมูลที่อ่านและเขียนระหว่างการดำเนินการทั้งหมดของโปรแกรมนั้นมากกว่าขนาดแคชมาก ดังนั้นจึงจำเป็นต้องลบบางส่วนออกเป็นครั้งคราวเพื่อให้รายการใหม่ที่เกี่ยวข้องมากขึ้นสามารถใส่ลงในแคชได้ กลไกที่ง่ายที่สุดที่ทราบเพื่อให้แน่ใจว่ากระบวนการนี้คือการติดตามเวลาของการเข้าถึงข้อมูลครั้งล่าสุดที่อยู่ในแคช ดังนั้น หากเราจำเป็นต้องวางข้อมูลใหม่ในแคช และแคช "เต็มความจุแล้ว" ตัวควบคุมที่จัดการแคชจะดูว่าแคชส่วนใดที่ไม่สามารถเข้าถึงได้เป็นเวลานานที่สุด ส่วนนี้เองที่เป็นตัวเลือกแรกสำหรับ "การออกเดินทาง" และแทนที่ข้อมูลใหม่จะถูกบันทึกไว้ซึ่งจำเป็นต้องดำเนินการในตอนนี้ โดยทั่วไปแล้ว นี่คือกลไกการแคชในโปรเซสเซอร์ทำงานอย่างไร แน่นอนว่าคำอธิบายข้างต้นนั้นดูดั้งเดิมมาก จริงๆ แล้วทุกอย่างซับซ้อนกว่านี้ แต่เราหวังว่าคุณจะเข้าใจได้ว่าทำไมโปรเซสเซอร์ถึงต้องการแคชและวิธีการทำงาน
เพื่อให้ชัดเจนว่าแคชมีความสำคัญเพียงใด เราจะยกตัวอย่างง่ายๆ: ความเร็วของการแลกเปลี่ยนข้อมูลระหว่างโปรเซสเซอร์ Pentium 4 และแคชนั้นเร็วกว่าความเร็วการทำงานกับหน่วยความจำมากกว่า 10 เท่า (!) ในความเป็นจริงโปรเซสเซอร์สมัยใหม่สามารถทำงานได้อย่างเต็มประสิทธิภาพกับแคชเท่านั้น: ทันทีที่พวกเขาต้องเผชิญกับความจำเป็นในการอ่านข้อมูลจากหน่วยความจำ เมกะเฮิรตซ์ที่โอ้อวดทั้งหมดก็เริ่ม "ทำให้อากาศร้อน" ตัวอย่างง่ายๆ อีกครั้ง: โปรเซสเซอร์ดำเนินการคำสั่งที่ง่ายที่สุดในรอบสัญญาณนาฬิกาเดียว นั่นคือในวินาทีที่โปรเซสเซอร์สามารถดำเนินการตามจำนวนนี้ได้ คำแนะนำง่ายๆความถี่ของมันคืออะไร (อันที่จริงมากกว่านั้น แต่เราจะทิ้งไว้ในภายหลัง...) แต่ในกรณีที่เลวร้ายที่สุดสามารถรอข้อมูลจากหน่วยความจำได้มากกว่า 200 รอบ! โปรเซสเซอร์ทำอะไรในขณะที่รอข้อมูลที่จำเป็น? แต่เขาไม่ทำอะไรเลย แค่ยืนรอ...
แคชหลายระดับ
การออกแบบเฉพาะของแกนประมวลผลสมัยใหม่ทำให้ระบบแคชใน CPU ส่วนใหญ่ต้องมีหลายระดับ แคชระดับแรก (ใกล้กับคอร์มากที่สุด) เดิมแบ่งออกเป็นสองซีก (โดยปกติจะเท่ากัน) ได้แก่ แคชคำสั่ง (L1I) และแคชข้อมูล (L1D) แผนกนี้จัดทำขึ้นโดยสิ่งที่เรียกว่า "สถาปัตยกรรมฮาร์วาร์ด" ของโปรเซสเซอร์ ซึ่งในปัจจุบันเป็นการพัฒนาทางทฤษฎีที่ได้รับความนิยมมากที่สุดสำหรับการสร้างซีพียูสมัยใหม่ ดังนั้นใน L1I จึงมีการรวบรวมเฉพาะคำสั่งเท่านั้น (ตัวถอดรหัสใช้งานได้ดูด้านล่าง) และใน L1D จะสะสมเฉพาะข้อมูลเท่านั้น (ตามกฎแล้วพวกเขาจะจบลงในการลงทะเบียนภายในของโปรเซสเซอร์) “ เหนือ L1” มีแคชระดับที่สอง - L2 ตามกฎแล้วจะมีปริมาณมากขึ้นและมี "ผสม" อยู่แล้ว - ทั้งคำสั่งและข้อมูลอยู่ที่นั่น ตามกฎแล้ว L3 (แคชระดับที่สาม) จะจำลองโครงสร้างของ L2 อย่างสมบูรณ์และไม่ค่อยพบในซีพียู x86 สมัยใหม่ บ่อยครั้งที่ L3 เป็นผลมาจากการประนีประนอม: โดยการใช้บัสที่ช้ากว่าและแคบกว่า มันสามารถทำให้มีขนาดใหญ่มากได้ แต่ในขณะเดียวกัน ความเร็ว L3 ก็ยังคงสูงกว่าความเร็วหน่วยความจำ (แม้ว่าจะไม่สูงเท่ากับแคช L2 ). อย่างไรก็ตามอัลกอริทึมสำหรับการทำงานกับแคชหลายระดับโดยทั่วไปไม่แตกต่างจากอัลกอริทึมสำหรับการทำงานกับแคชระดับเดียว เพียงเพิ่มการวนซ้ำเพิ่มเติม: ขั้นแรก ข้อมูลจะถูกค้นหาใน L1 หากไม่มี - ใน L2 จากนั้น - ใน L3 และหลังจากนั้นเท่านั้นหากไม่พบในระดับแคชเดียว - กำลังเข้าถึงหน่วยความจำหลัก (RAM)
เครื่องถอดรหัส
ที่จริงแล้วหน่วยประมวลผลของโปรเซสเซอร์ x86 เดสก์ท็อปสมัยใหม่ทั้งหมด... ไม่สามารถใช้งานกับโค้ดในมาตรฐาน x86 ได้เลย โปรเซสเซอร์แต่ละตัวมีระบบคำสั่ง "ภายใน" ของตัวเอง ซึ่งไม่มีอะไรเหมือนกันกับคำสั่งเหล่านั้น (นั่นคือ "รหัส") ที่มาจากภายนอก โดยทั่วไป คำสั่งที่ดำเนินการโดยเคอร์เนลนั้นง่ายกว่าและดั้งเดิมกว่าคำสั่งของมาตรฐาน x86 มาก มีไว้เพื่อให้โปรเซสเซอร์ "ดูภายนอก" เหมือน CPU x86 อย่างแม่นยำและมีบล็อกเช่นตัวถอดรหัส: มีหน้าที่ในการแปลงรหัส x86 "ภายนอก" เป็นคำสั่ง "ภายใน" ที่ดำเนินการโดยเคอร์เนล (ในสิ่งนี้ กรณีนี้ บ่อยครั้งที่คำสั่งหนึ่งของโค้ด x86 จะถูกแปลงเป็น "ภายใน" ที่ง่ายกว่าเล็กน้อย ตัวถอดรหัสเป็นส่วนที่สำคัญมากของโปรเซสเซอร์สมัยใหม่: ความเร็วของมันจะกำหนดว่าการไหลของคำสั่งที่มาถึงหน่วยดำเนินการจะคงที่เพียงใด ท้ายที่สุดพวกเขาไม่สามารถทำงานกับรหัส x86 ได้ดังนั้นไม่ว่าพวกเขาจะทำอะไรบางอย่างหรือไม่ได้ใช้งานส่วนใหญ่ขึ้นอยู่กับความเร็วของตัวถอดรหัส Intel ได้ใช้วิธีที่ค่อนข้างผิดปกติในการเร่งกระบวนการถอดรหัสคำสั่งในโปรเซสเซอร์สถาปัตยกรรม NetBurst - ดูด้านล่างเกี่ยวกับแคชติดตาม
อุปกรณ์ดำเนินการ (ใช้งานได้)
เมื่อผ่านระดับแคชและตัวถอดรหัสทั้งหมดแล้วในที่สุดคำสั่งก็ไปถึงบล็อกที่จัดระเบียบความสับสนวุ่นวายทั้งหมดนี้: การแสดงอุปกรณ์ ที่จริงแล้วมันเป็นอุปกรณ์ในการดำเนินการนั่นเอง องค์ประกอบที่จำเป็นเท่านั้นโปรเซสเซอร์ คุณสามารถทำได้โดยไม่ต้องใช้แคช - ความเร็วจะลดลง แต่โปรแกรมจะทำงาน คุณสามารถทำได้โดยไม่ต้องใช้ตัวถอดรหัส - อุปกรณ์ประมวลผลจะซับซ้อนมากขึ้น แต่โปรเซสเซอร์จะยังคงทำงานอยู่ ท้ายที่สุดแล้วโปรเซสเซอร์ x86 รุ่นแรก ๆ (i8086, i80186, 286, 386, 486, Am5x86) ได้รับการจัดการโดยไม่ต้องใช้ตัวถอดรหัส เป็นไปไม่ได้ที่จะทำโดยไม่มีอุปกรณ์ดำเนินการ เนื่องจากอุปกรณ์เหล่านี้เป็นอุปกรณ์ที่รันโค้ดโปรแกรม ในการประมาณครั้งแรก โดยทั่วไปจะแบ่งออกเป็นสองกลุ่มใหญ่: หน่วยทางคณิตศาสตร์ (ALU) และหน่วยจุดลอยตัว (FPU)
อุปกรณ์ลอจิกเลขคณิต
ALU มักจะรับผิดชอบการดำเนินงานสองประเภท: การดำเนินการทางคณิตศาสตร์(การบวก ลบ การคูณ การหาร) ด้วยจำนวนเต็ม การดำเนินการเชิงตรรกะด้วยจำนวนเต็มอีกครั้ง (เชิงตรรกะ “และ” ตรรกะ “หรือ” “เฉพาะหรือ” และอื่นๆ ในทำนองเดียวกัน) ซึ่งอันที่จริงตามมาจากชื่อของพวกเขา ตามกฎแล้วมี ALU หลายหน่วยในโปรเซสเซอร์สมัยใหม่ เพื่ออะไร - คุณจะเข้าใจในภายหลังหลังจากอ่านหัวข้อ "Superscalarity และการดำเนินการคำสั่งที่ไม่เป็นไปตามคำสั่ง" เป็นที่ชัดเจนว่า ALU สามารถดำเนินการตามคำสั่งที่กำหนดไว้เท่านั้น บล็อกพิเศษมีหน้าที่รับผิดชอบในการกระจายคำสั่งที่มาจากตัวถอดรหัสไปยังอุปกรณ์ดำเนินการต่าง ๆ แต่อย่างที่พวกเขาพูดว่า "เรื่องที่ซับซ้อนเกินไป" และแทบจะไม่สมเหตุสมผลเลยที่จะอธิบายสิ่งเหล่านี้ในเนื้อหาที่อุทิศให้กับคนรู้จักผิวเผินเท่านั้น หลักการทำงานของซีพียู x86 สมัยใหม่
หน่วยจุดลอยตัว*
FPU มีหน้าที่รับผิดชอบในการดำเนินการคำสั่งที่ทำงานกับตัวเลขทศนิยม นอกจากนี้ตามธรรมเนียมแล้วจะ "แขวนสุนัขทั้งหมด" ไว้ในรูปแบบของชุดคำสั่งเพิ่มเติมทุกประเภท (MMX, 3DNow!, SSE, SSE2, SSE3.. .) - ไม่ว่าจะทำงานกับตัวเลขทศนิยมหรือจำนวนเต็มก็ตาม เช่นเดียวกับในกรณีของ ALU อาจมีบล็อกหลายบล็อกใน FPU และสามารถทำงานแบบขนานได้
* - ตามประเพณีของโรงเรียนคณิตศาสตร์รัสเซียเราเรียก FPU ว่าเป็น "หน่วยคำนวณแบบลอยตัว" ลูกน้ำ" แม้ว่าชื่อของมันแท้จริงแล้ว (Floating จุดหน่วย) แปลว่า “...จุดลอยตัว” - ตามมาตรฐานการเขียนตัวเลขดังกล่าวของอเมริกา
การลงทะเบียนโปรเซสเซอร์
โดยพื้นฐานแล้วรีจิสเตอร์คือเซลล์หน่วยความจำเดียวกัน แต่ "ในเชิงภูมิศาสตร์" เซลล์เหล่านี้จะอยู่ในแกนประมวลผลโดยตรง แน่นอนว่าความเร็วในการทำงานกับรีจิสเตอร์นั้นมากกว่าความเร็วในการทำงานกับเซลล์หน่วยความจำที่อยู่ใน RAM หลักหลายเท่า (โดยทั่วไปจะเรียงตามลำดับความสำคัญ...) และกับแคชในทุกระดับ ดังนั้นคำสั่งส่วนใหญ่ในสถาปัตยกรรม x86 จึงเกี่ยวข้องกับการดำเนินการกับเนื้อหาของรีจิสเตอร์โดยเฉพาะ ไม่ใช่ในเนื้อหาของหน่วยความจำ อย่างไรก็ตาม ตามกฎแล้วปริมาณการลงทะเบียนตัวประมวลผลทั้งหมดมีขนาดเล็กมาก - ไม่สามารถเทียบได้กับปริมาณของแคชระดับแรกด้วยซ้ำ ดังนั้นโค้ดโปรแกรมโดยพฤตินัย (ไม่ใช่ในภาษาระดับสูง แต่เป็นไบนารี "เครื่องจักร") มักจะมีลำดับการดำเนินการดังต่อไปนี้: โหลดข้อมูลจาก RAM ลงในหนึ่งในการลงทะเบียนตัวประมวลผล โหลดข้อมูลอื่น ๆ ลงในการลงทะเบียนอื่น (เช่นจาก RAM) ดำเนินการบางอย่างกับเนื้อหาของรีจิสเตอร์เหล่านี้โดยวางผลลัพธ์ไว้ในอันที่สาม - จากนั้นจึงขนผลลัพธ์จากรีจิสเตอร์ไปยังหน่วยความจำหลักอีกครั้ง
โปรเซสเซอร์โดยละเอียด
คุณสมบัติของแคช
ความถี่แคชและบัส
ในซีพียู x86 สมัยใหม่ทั้งหมด ระดับแคชทั้งหมดจะทำงานที่ความถี่เดียวกันกับแกนประมวลผล แต่ก็ไม่ได้เป็นเช่นนั้นเสมอไป (ปัญหานี้ได้ถูกหยิบยกขึ้นมาข้างต้นแล้ว) อย่างไรก็ตามความเร็วในการทำงานกับแคชไม่เพียงขึ้นอยู่กับความถี่เท่านั้น แต่ยังขึ้นอยู่กับความกว้างของบัสที่เชื่อมต่อกับคอร์โปรเซสเซอร์ด้วย ดังที่คุณ (หวังว่า) จำได้จากการอ่านครั้งก่อน อัตราการถ่ายโอนข้อมูลโดยพื้นฐานแล้วเป็นผลคูณของความถี่บัส (จำนวนรอบสัญญาณนาฬิกาต่อวินาที) คูณด้วยจำนวนไบต์ที่ถ่ายโอนไปตามบัสในรอบสัญญาณนาฬิกาหนึ่งรอบ จำนวนไบต์ที่ส่งต่อรอบสัญญาณนาฬิกาสามารถเพิ่มได้โดยการใช้โปรโตคอล DDR และ QDR (Double Data Rate และ Quad Data Rate) หรือเพียงเพิ่มความกว้างของบัส ในกรณีของแคช ตัวเลือกที่สองได้รับความนิยมมากกว่า อย่างน้อยก็เนื่องมาจาก "คุณสมบัติที่น่าสนใจ" ของ DDR/QDR ที่อธิบายไว้ข้างต้น แน่นอนว่าความกว้างแคชบัสขั้นต่ำที่เหมาะสมคือความกว้างของบัสภายนอกของโปรเซสเซอร์เองนั่นคือ ณ วันนี้ - 64 บิต นี่คือสิ่งที่ AMD ทำในจิตวิญญาณของความเรียบง่ายที่ดีต่อสุขภาพ: ในโปรเซสเซอร์ความกว้างของบัส L1 L2 คือ 64 บิต แต่ในขณะเดียวกันก็เป็นแบบสองทิศทางนั่นคือสามารถส่งและรับข้อมูลได้พร้อมกัน . Intel ดำเนินการอีกครั้งด้วยจิตวิญญาณของ "ความยิ่งใหญ่ที่ดีต่อสุขภาพ": ในโปรเซสเซอร์โดยเริ่มจาก Pentium III "Coppermine" บัส L1 L2 มีความกว้าง... 256 บิต! ตามหลักการที่ว่า "คุณไม่สามารถทำให้โจ๊กเสียด้วยเนยได้" ตามที่พวกเขาพูด จริงอยู่ที่รถบัสนี้มีทิศทางเดียวนั่นคือ ณ จุดหนึ่งมันจะใช้งานได้สำหรับการส่งสัญญาณเท่านั้นหรือสำหรับการรับสัญญาณเท่านั้น การถกเถียงเกี่ยวกับวิธีการที่ดีกว่า (บัสแบบสองทิศทาง แต่แคบกว่า หรือบัสแบบทิศทางเดียว) ยังคงดำเนินต่อไปจนถึงทุกวันนี้... อย่างไรก็ตาม เช่นเดียวกับข้อพิพาทอื่น ๆ อีกมากมายเกี่ยวกับโซลูชันทางเทคนิคที่ใช้โดยคู่แข่งหลักสองรายในตลาดซีพียู x86 .
แคชพิเศษและไม่ผูกขาด
แนวคิดของการแคชแบบเอกสิทธิ์เฉพาะบุคคลและแบบไม่ผูกขาดนั้นง่ายมาก: ในกรณีของแคชแบบไม่ผูกขาด ข้อมูลในระดับแคชทั้งหมดสามารถทำซ้ำได้ ดังนั้น L2 จึงสามารถมีข้อมูลที่มีอยู่แล้วใน L1I และ L1D และ L3 (ถ้ามี) สามารถมีสำเนาที่สมบูรณ์ของเนื้อหาทั้งหมดของ L2 (และ L1I และ L1D ตามลำดับ) แคชเอกสิทธิ์เฉพาะบุคคลนั้นแตกต่างจากแคชแบบไม่ผูกขาดตรงที่ให้ความแตกต่างที่ชัดเจน: หากมีข้อมูลอยู่ที่ระดับแคชระดับใดระดับหนึ่ง ก็จะไม่ปรากฏที่แคชระดับอื่นทั้งหมด ข้อดีของแคชพิเศษนั้นชัดเจน: ขนาดรวมของข้อมูลที่แคชในกรณีนี้เท่ากับปริมาณรวมของแคชในทุกระดับ ตรงกันข้ามกับแคชที่ไม่ผูกขาด ซึ่งขนาดของข้อมูลที่แคช (ในกรณีที่เลวร้ายที่สุด) ) เท่ากับปริมาตรของระดับแคชที่ใหญ่ที่สุด ข้อเสียของแคชพิเศษนั้นชัดเจนน้อยกว่า แต่มีอยู่: จำเป็นต้องมีกลไกพิเศษที่ตรวจสอบ "ความพิเศษ" ที่แท้จริง (ตัวอย่างเช่นเมื่อลบข้อมูลจากแคช L1 กระบวนการคัดลอกไปยัง L2 จะเริ่มโดยอัตโนมัติก่อนหน้านั้น ).
โดยทั่วไปแล้ว Intel จะใช้แคชแบบไม่ผูกขาด ส่วนแคชพิเศษ (ตั้งแต่การกำเนิดของโปรเซสเซอร์ Athlon ที่ใช้คอร์ Thunderbird) ถูกใช้โดย AMD โดยทั่วไป เราเห็นการเผชิญหน้าแบบคลาสสิกระหว่างปริมาณและความเร็ว: เนื่องจากความพิเศษเฉพาะตัว ด้วยปริมาณ L1/L2 ที่เท่ากัน AMD จึงได้รับขนาดข้อมูลแคชโดยรวมที่ใหญ่กว่า - แต่เนื่องจากมันทำงานช้าลงด้วย (ความล่าช้าที่เกิดจากการมีอยู่ของข้อมูล) ของกลไกพิเศษ) อาจเป็นที่น่าสังเกตว่าเมื่อเร็ว ๆ นี้ Intel ได้ชดเชยข้อบกพร่องของแคชที่ไม่ผูกขาดด้วยวิธีที่เรียบง่าย โง่เขลา แต่มีนัยสำคัญ: โดยการเพิ่มระดับเสียง สำหรับโปรเซสเซอร์ระดับท็อปของบริษัทนี้ แคช L2 ขนาด 2 MB เกือบจะกลายเป็นเรื่องปกติไปแล้ว และ AMD ซึ่งมี L1C+L1D ขนาด 128 KB และสูงสุด 1 MB L2 ยังไม่ได้ "เอาชนะ" ขนาด 2 MB เหล่านี้แม้จะเนื่องมาจากความพิเศษเฉพาะตัว .
นอกจากนี้ การเพิ่มปริมาณรวมของข้อมูลแคชด้วยการใช้สถาปัตยกรรมแคชพิเศษเฉพาะจะเหมาะสมก็ต่อเมื่อปริมาณที่เพิ่มขึ้นนั้นค่อนข้างมาก และ m. สำหรับ AMD สิ่งนี้มีความเกี่ยวข้องเพราะ... CPU ปัจจุบันมีปริมาณ L1D+L1I รวม 128 KB สำหรับโปรเซสเซอร์ Intel ซึ่งมีปริมาณ L1D สูงสุด 32 KB และบางครั้ง L1I ก็มีโครงสร้างที่แตกต่างไปจากเดิมอย่างสิ้นเชิง (ดูเกี่ยวกับแคชการติดตาม) การแนะนำสถาปัตยกรรมพิเศษจะให้ประโยชน์น้อยกว่ามาก
นอกจากนี้ยังมีความเข้าใจผิดที่พบบ่อยว่าสถาปัตยกรรมแคชของ Intel CPU นั้น "ครอบคลุม" ไม่เชิง. มันไม่ได้พิเศษ สถาปัตยกรรมแบบรวมช่วยให้มีระดับแคช "ต่ำกว่า" ไม่ได้ไม่มีอะไรที่ไม่ได้อยู่บน "สูงกว่า" ไม่ใช่สถาปัตยกรรมพิเศษ ยอมรับการทำซ้ำข้อมูลในระดับต่างๆ
ติดตามแคช
แนวคิดของ Trace cache คือการจัดเก็บไว้ในแคชคำสั่งระดับแรก (L1I) ไม่ใช่คำสั่งที่อ่านจากหน่วยความจำ แต่เป็นลำดับที่ถอดรหัสแล้ว (ดูตัวถอดรหัส) ดังนั้น หากคำสั่ง x86 บางตัวถูกดำเนินการซ้ำๆ และยังยังคงอยู่ใน L1I ตัวถอดรหัสโปรเซสเซอร์ก็ไม่จำเป็นต้องแปลงคำสั่งนั้นเป็นลำดับของคำสั่ง "โค้ดภายใน" อีกครั้ง เนื่องจาก L1I มีลำดับนี้ในรูปแบบที่ถอดรหัสแล้ว แนวคิดแคชการติดตามเข้ากันได้เป็นอย่างดีกับแนวคิดทั่วไปของสถาปัตยกรรม Intel NetBurst ซึ่งมีวัตถุประสงค์เพื่อสร้างโปรเซสเซอร์ที่มีความถี่คอร์ที่สูงมาก อย่างไรก็ตาม ประโยชน์ของ Trace cache สำหรับ CPU ความถี่ต่ำ [ค่อนข้าง] ยังคงเป็นที่น่าสงสัย เนื่องจากความซับซ้อนของการจัดระเบียบ Trace cache เทียบได้กับงานการออกแบบตัวถอดรหัสแบบรวดเร็วแบบทั่วไป ดังนั้น แม้จะยกย่องความริเริ่มของแนวคิดนี้ เรายังคงกล่าวว่า Trace cache ไม่สามารถถือเป็นโซลูชันสากล “สำหรับทุกโอกาส” ได้
Superscalarity และการดำเนินการตามคำสั่งที่ไม่เป็นระเบียบ
คุณสมบัติหลักของโปรเซสเซอร์สมัยใหม่ทั้งหมดคือสามารถเรียกใช้การดำเนินการได้ไม่เพียงแต่คำสั่งที่ควรดำเนินการ (ตามรหัสโปรแกรม) ในเวลาที่กำหนดเท่านั้น แต่ยังรวมถึงคำสั่งอื่น ๆ ที่ตามมาด้วย เรามายกตัวอย่างง่ายๆ (ตามรูปแบบบัญญัติ) กัน ให้เราดำเนินการตามลำดับคำสั่งต่อไปนี้:
1) ก = ข + ค
2) Z = X + Y
3) K = A + Z
เป็นเรื่องง่ายที่จะเห็นว่าคำสั่ง (1) และ (2) มีความเป็นอิสระจากกันโดยสมบูรณ์ - คำสั่งเหล่านี้ไม่ได้ตัดกันในข้อมูลต้นฉบับ (ตัวแปร B และ C ในกรณีแรก, X และ Y ในกรณีที่สอง) หรือใน ตำแหน่งของผลลัพธ์ (ตัวแปร A ในกรณีแรกและ Z ในกรณีที่สอง) ดังนั้น หากในขณะนี้ เรามีบล็อกการดำเนินการที่ว่างมากกว่าหนึ่งบล็อก คำสั่งเหล่านี้สามารถกระจายไปยังบล็อกเหล่านั้นและดำเนินการพร้อมกัน แทนที่จะดำเนินการตามลำดับ* ดังนั้น หากเราใช้เวลาดำเนินการของแต่ละคำสั่งเท่ากับ N รอบของตัวประมวลผล ดังนั้นในกรณีคลาสสิก การดำเนินการของลำดับทั้งหมดจะใช้เวลา N*3 รอบสัญญาณนาฬิกา และในกรณีของการดำเนินการแบบขนาน - มีเพียงรอบสัญญาณนาฬิกา N*2 เท่านั้น (เนื่องจากคำสั่ง (3) ไม่สามารถดำเนินการได้ โดยไม่ต้องรอผลลัพธ์ของสองคำสั่งก่อนหน้า)
* - แน่นอนว่าระดับของความขนานนั้นไม่มีที่สิ้นสุด: คำสั่งสามารถดำเนินการแบบขนานได้ก็ต่อเมื่อมีจำนวนบล็อกว่าง (FU) ที่เหมาะสมในเวลาที่กำหนด และผู้ที่ "เข้าใจ" คำสั่งดังกล่าวโดยเฉพาะ. ตัวอย่างที่ง่ายที่สุด: บล็อกที่เป็นของ ALU ไม่สามารถดำเนินการคำสั่งที่มีไว้สำหรับ FPU ได้ทางกายภาพ สิ่งที่ตรงกันข้ามก็เป็นจริงเช่นกัน
ที่จริงแล้วมันซับซ้อนกว่านั้นอีก ดังนั้น หากเรามีลำดับดังนี้
1) ก = ข + ค
2) K = A + M
3) Z = X + Y
จากนั้นคิวการดำเนินการคำสั่งของโปรเซสเซอร์จะเปลี่ยนไป! เนื่องจากคำสั่ง (1) และ (3) มีความเป็นอิสระจากกัน (ทั้งในข้อมูลต้นทางหรือตำแหน่งของผลลัพธ์) จึงสามารถดำเนินการแบบคู่ขนานได้ และจะดำเนินการแบบคู่ขนานกัน แต่คำสั่ง (2) จะถูกดำเนินการหลังจากนั้น (คำสั่งที่สาม) - เนื่องจากเพื่อให้ผลการคำนวณถูกต้อง จำเป็นต้องดำเนินการคำสั่ง (1) ก่อนหน้านั้น ด้วยเหตุนี้กลไกที่กล่าวถึงในหัวข้อนี้จึงเรียกว่า “การดำเนินการตามคำสั่งนอกคำสั่ง” (Out-of-Order Execution หรือเรียกสั้น ๆ ว่า “OoO”) ในกรณีที่คำสั่งในการดำเนินการไม่สามารถส่งผลกระทบในทางใดทางหนึ่งต่อ ผลลัพธ์คือมีการส่งคำสั่งเพื่อดำเนินการในลำดับที่ไม่ถูกต้อง ลำดับที่อยู่ในโค้ดโปรแกรม แต่เป็นลำดับที่ช่วยให้คุณได้รับประสิทธิภาพสูงสุด
ในที่สุดก็ควรจะชัดเจนสำหรับคุณแล้วว่าทำไม CPU สมัยใหม่จึงต้องการหน่วยประมวลผลประเภทเดียวกันจำนวนมาก: พวกมันให้ความสามารถในการรันคำสั่งหลายคำสั่งพร้อมกันซึ่งในกรณีของแนวทาง "คลาสสิก" ในการออกแบบโปรเซสเซอร์จะต้องดำเนินการ ในลำดับที่มีอยู่ในซอร์สโค้ดทีละรายการ
โปรเซสเซอร์ที่มีกลไกสำหรับการประมวลผลคำสั่งหลายคำสั่งต่อเนื่องกันแบบขนาน มักเรียกว่า "ซูเปอร์สเกลาร์" อย่างไรก็ตาม ไม่ใช่ว่าโปรเซสเซอร์ระดับซูเปอร์สเกลาร์ทั้งหมดจะรองรับการดำเนินการที่ไม่อยู่ในลำดับ ดังนั้นในตัวอย่างแรก “ความยิ่งใหญ่แบบธรรมดา” (การดำเนินการสองคำสั่งติดต่อกันพร้อมกัน) ก็เพียงพอแล้วสำหรับเรา - แต่ในตัวอย่างที่สอง เราไม่สามารถดำเนินการได้โดยไม่ต้องจัดเรียงคำสั่งใหม่ หากเราต้องการได้รับประสิทธิภาพสูงสุด CPU x86 ที่ทันสมัยทั้งหมดมีคุณสมบัติทั้งสองอย่าง: เป็นซุปเปอร์สเกลาร์และรองรับการดำเนินการตามคำสั่งที่ไม่เป็นไปตามคำสั่ง ในเวลาเดียวกัน ในประวัติศาสตร์ของ x86 ยังมี "ซุปเปอร์สเกลาร์แบบธรรมดา" ที่ไม่รองรับ OoO ตัวอย่างเช่น เดสก์ท็อป x86 ซูเปอร์สเกลาร์แบบคลาสสิกที่ไม่มี OoO คือ Intel Pentium
เพื่อความเป็นธรรม เป็นที่น่าสังเกตว่าทั้ง Intel หรือ AMD หรือผู้ผลิตซีพียู x86 รายอื่น (รวมถึงที่เสียชีวิตไปแล้ว) ไม่มีข้อดีในการพัฒนาแนวคิดเรื่อง superscalarity และ OoO คอมพิวเตอร์ซูเปอร์สเกลาร์เครื่องแรกที่รองรับ OoO ได้รับการพัฒนาโดย Seymour Cray ย้อนกลับไปในยุค 60 ของศตวรรษที่ 20 สำหรับการเปรียบเทียบ: Intel เปิดตัวโปรเซสเซอร์ superscalar ตัวแรก (Pentium) ในปี 1993 ซึ่งเป็น superscalar ตัวแรกที่มี OoO (Pentium Pro) - ในปี 1995 OoO superscalar (K5) ตัวแรกของ AMD เปิดตัวในปี 1996 ความเห็นอย่างที่เขาว่ากันว่าไม่จำเป็น...
การถอดรหัสเบื้องต้น (ล่วงหน้า)
และการแคช
การทำนายสาขา
โปรแกรมที่ซับซ้อนไม่มากก็น้อยจะมีคำสั่งการข้ามแบบมีเงื่อนไข: “หากเงื่อนไขใดเงื่อนไขหนึ่งเป็นจริง ให้ไปที่การดำเนินการของโค้ดส่วนหนึ่ง หากไม่ใช่ ให้ไปที่ส่วนอื่น” ในแง่ของความเร็วในการรันโค้ดโปรแกรม โปรเซสเซอร์ที่ทันสมัยซึ่งสนับสนุนการดำเนินการที่ไม่เป็นไปตามคำสั่ง คำสั่งการกระโดดแบบมีเงื่อนไขใดๆ ถือเป็นหายนะของพระเจ้าอย่างแท้จริง ท้ายที่สุดจนกว่าจะทราบว่าส่วนใดของโค้ดหลังจากการข้ามแบบมีเงื่อนไขจะ "เกี่ยวข้อง" จึงเป็นไปไม่ได้ที่จะเริ่มถอดรหัสและดำเนินการ (ดูการดำเนินการที่ไม่อยู่ในลำดับ) เพื่อที่จะกระทบยอดแนวคิดของการดำเนินการที่ไม่อยู่ในลำดับด้วยคำสั่งการข้ามแบบมีเงื่อนไข จึงมีจุดมุ่งหมายในบล็อกพิเศษ: บล็อกการทำนายสาขา ตามชื่อของมัน มันเกี่ยวข้องกับ "คำทำนาย" เป็นหลัก: มันพยายามคาดเดาส่วนของโค้ดที่คำสั่ง Jump แบบมีเงื่อนไขจะชี้ไปที่ แม้กระทั่งก่อนที่จะถูกดำเนินการก็ตาม ตามคำแนะนำของ "ผู้เผยพระวจนะภายในคอร์ปกติ" โปรเซสเซอร์จะดำเนินการจริงมาก: ส่วนโค้ด "ที่ทำนายไว้" จะถูกโหลดลงในแคช (หากไม่มีอยู่) และแม้แต่เริ่มถอดรหัสและดำเนินการคำสั่งของมัน . นอกจากนี้ ในบรรดาคำสั่งที่ถูกดำเนินการนั้นอาจมีคำสั่งการข้ามแบบมีเงื่อนไขด้วย และผลลัพธ์ของคำสั่งเหล่านั้นก็จะถูกคาดการณ์ด้วย ซึ่งจะสร้างห่วงโซ่ทั้งหมดของ ยังไม่ได้รับการยืนยันคำทำนาย! แน่นอนว่า หากหน่วยทำนายสาขาผิด งานทั้งหมดที่ทำตามการคาดการณ์ก็จะถูกยกเลิกไป
อันที่จริง อัลกอริธึมที่ใช้โดยหน่วยทำนายสาขาไม่ใช่ผลงานชิ้นเอกของปัญญาประดิษฐ์เลย ส่วนใหญ่จะเรียบง่าย...และโง่เขลา เนื่องจากโดยส่วนใหญ่แล้วคำสั่ง Jump แบบมีเงื่อนไขจะพบอยู่ในลูป: ตัวนับบางตัวรับค่า X และหลังจากผ่านแต่ละลูป ค่าของตัวนับจะลดลงหนึ่งตัว ดังนั้น ตราบใดที่ค่าตัวนับมากกว่าศูนย์ การเปลี่ยนไปยังจุดเริ่มต้นของลูปจะดำเนินการ และหลังจากที่มีค่าเท่ากับศูนย์ การดำเนินการจะดำเนินต่อไปต่อไป บล็อกการทำนายสาขาเพียงวิเคราะห์ผลลัพธ์ของการดำเนินการคำสั่งกระโดดแบบมีเงื่อนไข และเชื่อว่าหาก N ครั้งติดต่อกัน ผลลัพธ์คือการข้ามไปยังที่อยู่ที่กำหนด ในกรณี N+1 จะทำการข้ามไปยังที่อยู่เดียวกัน อย่างไรก็ตาม แม้จะมีลัทธิดั้งเดิมทั้งหมด โครงการนี้มันใช้งานได้ดี: ตัวอย่างเช่น หากตัวนับรับค่า 100 และ "เกณฑ์การดำเนินการ" ของตัวทำนายสาขา (N) เท่ากับการเปลี่ยนสองครั้งติดต่อกันไปยังที่อยู่เดียวกัน - จะง่ายที่จะเห็นว่าการเปลี่ยน 97 ครั้งออก จาก 98 ทำนายถูก!
แน่นอนว่าแม้จะมีประสิทธิภาพค่อนข้างสูงก็ตาม อัลกอริธึมอย่างง่ายกลไกการทำนายสาขาใน CPU สมัยใหม่ยังคงได้รับการปรับปรุงอย่างต่อเนื่องและมีความซับซ้อนมากขึ้น - แต่ที่นี่เรากำลังพูดถึงการต่อสู้เพื่อหน่วยเปอร์เซ็นต์: ตัวอย่างเช่นเพื่อเพิ่มประสิทธิภาพของหน่วยทำนายสาขาจาก 95 เปอร์เซ็นต์เป็น 97 หรือ แม้จาก 97% ถึง 99 ...
การดึงข้อมูลล่วงหน้า
บล็อกการดึงข้อมูลล่วงหน้า (Prefetch) มีความคล้ายคลึงกันมากในหลักการของการดำเนินการกับบล็อกการทำนายสาขา ข้อแตกต่างเพียงอย่างเดียวคือในกรณีนี้ เรากำลังพูดถึงไม่เกี่ยวกับโค้ด แต่เกี่ยวกับข้อมูล หลักการทั่วไปการดำเนินการจะเหมือนกัน: หากวงจรในตัวสำหรับการวิเคราะห์การเข้าถึงข้อมูล RAM ตัดสินใจว่าจะเข้าถึงพื้นที่หน่วยความจำบางส่วนที่ยังไม่ได้โหลดลงในแคชในไม่ช้าก็จะให้คำสั่งให้โหลดพื้นที่นี้ของ หน่วยความจำในแคชก่อนที่โปรแกรมปฏิบัติการจะจำเป็นต้องใช้ หน่วยดึงข้อมูลล่วงหน้าที่ทำงาน "อย่างชาญฉลาด" (มีประสิทธิภาพ) สามารถลดเวลาการเข้าถึงข้อมูลที่ต้องการได้อย่างมาก และด้วยเหตุนี้ จึงเพิ่มความเร็วของการทำงานของโปรแกรม โดยวิธีการ: Prefetch ที่มีความสามารถจะชดเชยเวลาแฝงที่สูงของระบบย่อยหน่วยความจำได้เป็นอย่างดีโหลดข้อมูลที่จำเป็นลงในแคชและด้วยเหตุนี้จึงปรับระดับความล่าช้าในการเข้าถึงหากไม่ได้อยู่ในแคช แต่อยู่ใน RAM หลัก .
อย่างไรก็ตาม แน่นอนว่า ในกรณีที่เกิดข้อผิดพลาดในหน่วยการดึงข้อมูลล่วงหน้า ผลที่ตามมาด้านลบเป็นสิ่งที่หลีกเลี่ยงไม่ได้: โดยการโหลดข้อมูลที่ "ไม่จำเป็น" โดยพฤตินัยลงในแคช การดึงข้อมูลล่วงหน้าจะแทนที่ข้อมูลอื่นๆ จากแคช (บางทีอาจเป็นเพียงข้อมูลที่จำเป็นเท่านั้น) นอกจากนี้ ด้วยการ "คาดการณ์" การดำเนินการอ่าน โหลดเพิ่มเติมจะถูกสร้างขึ้นบนตัวควบคุมหน่วยความจำ (โดยพฤตินัย ในกรณีที่เกิดข้อผิดพลาด จะไม่มีประโยชน์โดยสิ้นเชิง)
อัลกอริธึมการดึงข้อมูลล่วงหน้าเช่นเดียวกับอัลกอริธึมของบล็อกการทำนายสาขาก็ไม่ได้ส่องแสงด้วยความชาญฉลาดเช่นกัน: ตามกฎแล้วบล็อกนี้พยายามติดตามว่าข้อมูลถูกอ่านจากหน่วยความจำด้วย "ขั้นตอน" บางอย่าง (ตามที่อยู่) หรือไม่และขึ้นอยู่กับการวิเคราะห์นี้ โดยจะพยายามคาดเดาที่อยู่จากที่อยู่ใด ข้อมูลจะถูกอ่านระหว่างการทำงานของโปรแกรมต่อไป อย่างไรก็ตาม เช่นเดียวกับในกรณีของบล็อกการทำนายสาขา ความเรียบง่ายของอัลกอริธึมไม่ได้หมายความว่าประสิทธิภาพต่ำเลย โดยเฉลี่ยแล้ว บล็อกการดึงข้อมูลล่วงหน้าจะ "เข้าชม" บ่อยกว่าที่จะทำผิดพลาด (และนี่ เช่นเดียวกับในกรณีก่อนหน้า สาเหตุหลักมาจากความจริงที่ว่าตามกฎแล้วการอ่านข้อมูลจากหน่วยความจำ "จำนวนมาก" เกิดขึ้นในระหว่างการดำเนินการของรอบต่างๆ)
บทสรุป
ฉันคือกระต่ายตัวนั้นที่ไม่สามารถเคี้ยวหญ้าได้จนกว่า...
จะไม่เข้าใจรายละเอียดทั้งหมดว่ากระบวนการสังเคราะห์แสงเกิดขึ้นได้อย่างไร!
(คำแถลงจุดยืนส่วนตัวโดยเพื่อนสนิทคนหนึ่งของผู้เขียน)
ค่อนข้างเป็นไปได้ที่ความรู้สึกที่คุณมีหลังจากอ่านบทความนี้สามารถอธิบายได้ประมาณดังนี้: “ แทนที่จะอธิบายด้วยนิ้วว่าโปรเซสเซอร์ตัวไหนดีกว่ากันพวกเขาเอาข้อมูลเฉพาะมากมายที่ยังต้องเข้าใจมาใส่สมองของฉัน และเข้าใจ และไม่มีที่สิ้นสุด!” ปฏิกิริยาปกติอย่างสมบูรณ์: เชื่อฉันสิเราเข้าใจคุณดี สมมติว่ามากกว่านี้ (และปล่อยให้มงกุฎหลุดจากหัวของคุณ!): ถ้าคุณคิดว่าพวกเราเองสามารถตอบคำถามง่าย ๆ นี้ (“ โปรเซสเซอร์ตัวไหนดีกว่า?”) - แสดงว่าคุณคิดผิดมาก ไม่ได้. สำหรับงานบางอย่างจะดีกว่าสำหรับงานอื่น ๆ - อีกงานหนึ่งจากนั้นราคาก็แตกต่างกัน ความพร้อมใช้งาน ความชอบของผู้ใช้เฉพาะสำหรับบางยี่ห้อ... ปัญหาไม่มีวิธีแก้ไขที่ชัดเจน ถ้ามี คงจะต้องมีคนค้นพบมัน และจะกลายเป็นผู้สังเกตการณ์ที่มีชื่อเสียงที่สุดในประวัติศาสตร์ของห้องปฏิบัติการทดสอบอิสระ
ฉันอยากจะเน้นอีกครั้ง: แม้จะมีการดูดซึมและเข้าใจข้อมูลทั้งหมดที่นำเสนอในเอกสารนี้อย่างสมบูรณ์แล้ว แต่คุณก็ยังไม่สามารถคาดเดาได้ว่าโปรเซสเซอร์ตัวใดในสองตัวนี้จะเร็วกว่าในงานของคุณโดยดูเฉพาะคุณลักษณะเท่านั้น. ประการแรก เนื่องจากไม่ได้พิจารณาคุณลักษณะทั้งหมดของโปรเซสเซอร์ที่นี่ ประการที่สอง เนื่องจากมีพารามิเตอร์ CPU ที่สามารถนำเสนอในรูปแบบตัวเลขเท่านั้นและขยายได้มากเท่านั้น แล้วทั้งหมดนี้เขียนเพื่อใคร (และเพื่ออะไร)? โดยหลักแล้ว - สำหรับ "กระต่าย" คนเดียวกันที่ต้องการทราบว่าเกิดอะไรขึ้นภายในอุปกรณ์ที่พวกเขาใช้ทุกวัน เพื่ออะไร? บางทีพวกเขาอาจจะรู้สึกดีขึ้นเมื่อรู้ว่าเกิดอะไรขึ้นรอบตัวพวกเขา? :)
ในอนาคตอันใกล้นี้มีแผนจะขยายคำถามที่พบบ่อย:
- ส่วนที่เกี่ยวกับระบบมัลติโปรเซสเซอร์โดยเฉพาะ: คำอธิบายแนวคิดของ SMP, เทคโนโลยี Hyper-Threading, การประมวลผล N, N-core
- ส่วนที่กล่าวถึงลักษณะทางกายภาพของ CPU โดยเฉพาะ: ประเภทของเคส ซ็อกเก็ต การใช้พลังงาน ฯลฯ
คุณสมบัติหลักของสถาปัตยกรรม
SSE4 ประกอบด้วย 54 คำสั่ง โดย 47 คำสั่งในนั้นจัดเป็น SSE4.1 (พบได้ในโปรเซสเซอร์ Penryn เท่านั้น) ชุดคำสั่งแบบเต็ม (SSE4.1 และ SSE4.2 เช่น 47 + 7 คำสั่งที่เหลือ) มีอยู่ในโปรเซสเซอร์ Nehalem ไม่มีคำสั่ง SSE4 ใดที่ใช้งานได้กับรีจิสเตอร์ mmx 64 บิต เฉพาะกับ xmm0-15 128 บิตเท่านั้น ไม่มีการเปิดตัวโปรเซสเซอร์ 32 บิตพร้อม SSE4
เพิ่มคำแนะนำที่เร่งความเร็วการชดเชยการเคลื่อนไหวในตัวแปลงสัญญาณวิดีโอ การอ่านอย่างรวดเร็วจากหน่วยความจำ USWC และคำแนะนำมากมายเพื่อทำให้การทำเวกเตอร์ของโปรแกรมโดยคอมไพเลอร์ทำได้ง่ายขึ้น นอกจากนี้ SSE4.2 ยังเพิ่มคำแนะนำสำหรับการประมวลผลสตริงอักขระ 8/16 บิต โดยคำนวณ CRC32, popcnt เป็นครั้งแรกใน SSE4 ที่การลงทะเบียน xmm0 ถูกใช้เป็นอาร์กิวเมนต์โดยนัยสำหรับคำแนะนำบางอย่าง
คำสั่ง SSE4.1 ใหม่ประกอบด้วยการเร่งความเร็ววิดีโอ เวกเตอร์ดั้งเดิม การแทรก/การแยก การคูณสเกลาร์เวกเตอร์ การผสม การตรวจสอบบิต การปัดเศษ และการอ่านหน่วยความจำ WC
คำสั่ง SSE4.2 ใหม่ประกอบด้วยการประมวลผลสตริง การนับ CRC32 การนับประชากรหนึ่งบิต และการทำงานกับเวกเตอร์ดั้งเดิม
SSE5
ส่วนขยายคำสั่ง x86 ใหม่จาก AMD ชื่อ SSE5 ชุดคำสั่ง SSE ใหม่ทั้งหมดซึ่งสร้างโดยผู้เชี่ยวชาญของ AMD จะได้รับการสนับสนุนจากบริษัท CPU ที่มีแนวโน้มจะเริ่มต้นในปี 2552
SSE5 นำคุณสมบัติบางอย่างมาสู่สถาปัตยกรรม x86 แบบคลาสสิกซึ่งก่อนหน้านี้มีเฉพาะในโปรเซสเซอร์ RISC เท่านั้น ชุดคำสั่ง SSE5 กำหนดคำสั่งพื้นฐานใหม่ 47 คำสั่งที่ออกแบบมาเพื่อเร่งความเร็วการประมวลผลแบบเธรดเดียวโดยการเพิ่มความหนาแน่นของข้อมูลที่ประมวลผล
ในบรรดาคำสั่งใหม่ มีสองกลุ่มหลักที่โดดเด่น ชุดแรกประกอบด้วยคำแนะนำที่รวบรวมผลลัพธ์ของการคูณ คำแนะนำประเภทนี้มีประโยชน์สำหรับการจัดระเบียบกระบวนการคำนวณซ้ำเมื่อเรนเดอร์รูปภาพหรือสร้างเอฟเฟกต์เสียง 3 มิติ คำสั่งใหม่กลุ่มที่สองประกอบด้วยคำสั่งที่ทำงานบนรีจิสเตอร์สองตัวและจัดเก็บผลลัพธ์ไว้ในคำสั่งที่สาม นวัตกรรมนี้สามารถช่วยให้นักพัฒนาหลีกเลี่ยงการถ่ายโอนข้อมูลที่ไม่จำเป็นระหว่างการลงทะเบียนในอัลกอริธึมการคำนวณ SSE5 ยังมีคำสั่งใหม่หลายประการสำหรับการเปรียบเทียบเวกเตอร์ การจัดเรียงและย้ายข้อมูล ตลอดจนการเปลี่ยนความแม่นยำและการปัดเศษ
AMD มองว่างานด้านคอมพิวเตอร์ การประมวลผลเนื้อหามัลติมีเดีย และเครื่องมือเข้ารหัสเป็นแอปพลิเคชันหลักสำหรับ SSE5 คาดว่าในการคำนวณแอปพลิเคชันที่ใช้การดำเนินการเมทริกซ์ การใช้ SSE5 จะช่วยเพิ่มประสิทธิภาพได้ 30% งานมัลติมีเดียที่ต้องการประสิทธิภาพการแปลงโคไซน์แบบแยกจะได้รับประโยชน์จากการเร่งความเร็ว 20% และอัลกอริธึมการเข้ารหัสด้วย SSE5 สามารถบรรลุความเร็วในการประมวลผลข้อมูลเพิ่มขึ้นห้าเท่า
เอวีเอ็กซ์
ส่วนขยายชุดถัดไปมาจาก Intel รองรับการประมวลผลตัวเลขทศนิยมที่บรรจุอยู่ใน "คำ" 256 บิต สำหรับพวกเขา มีการรองรับคำสั่งเดียวกันเช่นเดียวกับในตระกูล SSE SSE 128 บิตลงทะเบียน XMM0 - XMM15 ขยายเป็น YMM0-YMM15 256 บิต
ส่วนขยายโปรเซสเซอร์ Intel Post 32nm เป็นชุดคำสั่งใหม่ของ Intel ที่ช่วยให้คุณสามารถแปลงตัวเลขครึ่งความแม่นยำเป็นตัวเลขความแม่นยำเดี่ยวและสองเท่า รับตัวเลขสุ่มจริงในฮาร์ดแวร์ และเข้าถึงรีจิสเตอร์ FS/GS
AVX2
การพัฒนาเพิ่มเติมของ AVX คำแนะนำจำนวนเต็ม SSE เริ่มทำงานกับรีจิสเตอร์ AVX 256 บิต
เออีเอส
ส่วนขยายของชุดคำสั่ง AES ซึ่งเป็นการใช้งานไมโครโปรเซสเซอร์ของการเข้ารหัส AES
3Dตอนนี้!
ชุดคำสั่งสำหรับการประมวลผลสตรีมของจำนวนจริงที่มีความแม่นยำระดับเดียว รองรับโดยโปรเซสเซอร์ AMD เริ่มต้นจาก K6-2 ไม่รองรับโปรเซสเซอร์ Intel
คำแนะนำ 3DNow! ใช้รีจิสเตอร์ MMX เป็นตัวถูกดำเนินการ (ตัวเลขความแม่นยำสองตัวถูกวางไว้ในรีจิสเตอร์เดียว) ดังนั้น ต่างจาก SSE ตรงที่ไม่จำเป็นต้องบันทึกบริบท 3DNow! แยกกันเมื่อสลับงาน
โหมด 64 บิต
Superscalar หมายความว่าโปรเซสเซอร์สามารถทำงานได้มากกว่าหนึ่งครั้งในรอบสัญญาณนาฬิกาหนึ่งรอบ Superpipelining หมายความว่าโปรเซสเซอร์มีไปป์ไลน์การคำนวณหลายรายการ Pentium มีสองตัว ซึ่งช่วยให้มีประสิทธิภาพเป็นสองเท่าของรุ่น 486 ที่ความถี่เดียวกัน โดยดำเนินการ 2 คำสั่งต่อรอบสัญญาณนาฬิกา
นอกจากนี้ คุณสมบัติของโปรเซสเซอร์ Pentium ยังเป็นหน่วย FPU ที่ได้รับการออกแบบใหม่ทั้งหมดและทรงพลังมากในขณะนั้น ซึ่งประสิทธิภาพดังกล่าวยังคงไม่สามารถบรรลุได้โดยคู่แข่งจนถึงสิ้นปี 1990
เพนเทียม โอเวอร์ไดรฟ์
นอกจากนี้ บล็อก MMX ยังถูกเพิ่มเข้าไปในคอร์ Pentium II
เซเลรอน
ตัวแทนคนแรกของตระกูลนี้มีพื้นฐานมาจากสถาปัตยกรรม Pentium II มันเป็นคาร์ทริดจ์ที่มีแผงวงจรพิมพ์ซึ่งติดตั้งคอร์แคชระดับที่สองและแท็กแคช ติดตั้งในช่องที่ 2
Modern Xeons ใช้สถาปัตยกรรม Core 2/Core i7
โปรเซสเซอร์เอเอ็มดี
Am8086 / Am8088 / Am186 / Am286 / Am386 / Am486โปรเซสเซอร์ AMD ใหม่โดยพื้นฐาน (เมษายน 1997) โดยใช้คอร์ที่ซื้อจาก NexGen โปรเซสเซอร์นี้มีการออกแบบรุ่นที่ห้า แต่เป็นของรุ่นที่หกและได้รับตำแหน่งเป็นคู่แข่งของ Pentium II รวมบล็อก MMX และบล็อก FPU ที่ออกแบบใหม่เล็กน้อย อย่างไรก็ตาม หน่วยเหล่านี้ยังคงทำงานช้ากว่าโปรเซสเซอร์ Intel ที่มีโอเวอร์คล็อกคล้ายกันถึง 15-20% โปรเซสเซอร์มีแคช L1 ขนาด 64 KB
โดยทั่วไป ประสิทธิภาพที่เทียบเคียงได้กับ Pentium II ความเข้ากันได้กับมาเธอร์บอร์ดรุ่นเก่า การเปิดตัวก่อนหน้านี้ (AMD เปิดตัว K6 เร็วกว่า Intel เปิดตัว P-II หนึ่งเดือน) และราคาที่ต่ำกว่าทำให้ได้รับความนิยมอย่างมาก แต่ปัญหาการผลิตของ AMD ทำให้ชื่อเสียงเสียไปอย่างมาก ของโปรเซสเซอร์นี้
K6-2การพัฒนาเพิ่มเติมของคอร์ K6 โปรเซสเซอร์เหล่านี้เพิ่มการรองรับ 3DNow เฉพาะทาง! . อย่างไรก็ตามประสิทธิภาพที่แท้จริงกลับกลายเป็นว่าต่ำกว่าของ Pentium II ที่มีโอเวอร์คล็อกคล้ายกันอย่างมาก (เนื่องจากประสิทธิภาพที่เพิ่มขึ้นตามความถี่ที่เพิ่มขึ้นใน P-II นั้นสูงขึ้นเนื่องจากแคชภายใน) และ K6-2 สามารถแข่งขันกับ Celeron เท่านั้น โปรเซสเซอร์มีแคช L1 ขนาด 64 KB
K6-IIIประสบความสำเร็จทางเทคโนโลยีมากกว่า K6-2 ซึ่งเป็นความพยายามที่จะสร้างอะนาล็อกของ Pentium III อย่างไรก็ตาม มันไม่ประสบความสำเร็จทางการตลาด มีความโดดเด่นด้วยการมีแคชระดับแรก 64 KB และแคชระดับที่สอง 256 KB ในคอร์ซึ่งทำให้มีประสิทธิภาพเหนือกว่า Intel Celeron ที่ความถี่สัญญาณนาฬิกาเดียวกันและไม่ด้อยกว่า Pentium III รุ่นแรก ๆ มากนัก .
K6-III+อะนาล็อก K6-III พร้อมเทคโนโลยีประหยัดพลังงาน PowerNow! และความถี่ที่สูงขึ้นและชุดคำสั่งแบบขยาย เดิมทีมีไว้สำหรับแล็ปท็อป มันถูกติดตั้งในระบบเดสก์ท็อปด้วยซ็อกเก็ตโปรเซสเซอร์ Super 7 ใช้เพื่ออัพเกรดระบบเดสก์ท็อปด้วยซ็อกเก็ตโปรเซสเซอร์ Socket 7 (เฉพาะบนมาเธอร์บอร์ดที่จ่ายแรงดันไฟฟ้าให้กับโปรเซสเซอร์สองระดับ ตัวแรกสำหรับยูนิต I/O ของโปรเซสเซอร์ และตัวที่สองสำหรับคอร์โปรเซสเซอร์ ผู้ผลิตบางรายไม่ได้จัดเตรียมแหล่งจ่ายไฟคู่ไว้บน เมนบอร์ดรุ่นแรกที่มีซ็อกเก็ต Socket 7)
คล้ายกับ K6-III+ โดยมีแคชระดับที่สองถูกตัดแต่งเหลือ 128 KB
แอธลอนโปรเซสเซอร์ที่ประสบความสำเร็จอย่างมากซึ่งต้องขอบคุณ AMD ที่สามารถฟื้นตำแหน่งที่สูญเสียไปเกือบในตลาดไมโครโปรเซสเซอร์ได้ แคชระดับแรก - 128 KB เริ่มแรก โปรเซสเซอร์ถูกผลิตในคาร์ทริดจ์ที่มีแคชระดับที่สอง (512 KB) ซึ่งอยู่บนบอร์ดและติดตั้งใน Slot A (ซึ่งมีกลไก แต่ไม่สามารถใช้งานร่วมกับ Slot 1 จาก Intel ได้ทางไฟฟ้า) จากนั้น ฉันเปลี่ยนมาใช้ Socket A และมีแคชระดับที่สอง 256 KB ในคอร์ ในแง่ของประสิทธิภาพ - อะนาล็อกโดยประมาณของ Pentium III
ดูรอนAthlon เวอร์ชันแยกส่วนจะแตกต่างจากรุ่นแม่ในขนาดของแคชระดับที่สอง (เพียง 64 KB แต่รวมเข้ากับชิปและทำงานที่ความถี่คอร์)
คู่แข่งกับ Pentium III / Pentium 4 รุ่น Celeron ประสิทธิภาพสูงกว่า Celerons ที่คล้ายกันอย่างเห็นได้ชัด และตรงกับ Pentium III เมื่อทำงานหลายอย่าง
แอธลอนเอ็กซ์พีการพัฒนาสถาปัตยกรรม Athlon อย่างต่อเนื่อง ในด้านประสิทธิภาพก็ใกล้เคียงกับ Pentium 4 เมื่อเปรียบเทียบกับ Athlon ปกติแล้ว มีการเพิ่มการรองรับคำสั่ง SSE แล้ว
เซมพรอนโปรเซสเซอร์ Athlon XP และ Athlon 64 เวอร์ชันราคาถูกกว่า (เนื่องจากแคชระดับที่สองลดลง)
Sempron รุ่นแรกได้รับการติดฉลากชิป Athlon XP ใหม่บนแกน Thoroughbred และ Thorton ซึ่งมีแคชระดับที่สอง 256 KB และทำงานบนบัส 166 (333 DDR) ต่อมาภายใต้แบรนด์ Sempron มีการผลิต Athlon 64/Athlon II เวอร์ชันแยกส่วน (และกำลังผลิต) โดยมีตำแหน่งเป็น คู่แข่งของอินเทลเซเลรอน Semprons ทั้งหมดมีแคชระดับ 2 ที่ลดลง รุ่นน้องของ Socket 754 ได้ปิดกั้น Cool&quiet และ x86-64; รุ่นซ็อกเก็ต 939 มีโหมดหน่วยความจำแบบดูอัลแชนเนลที่ล็อคไว้
ออปเทอรอนโปรเซสเซอร์ตัวแรกที่รองรับสถาปัตยกรรม x86-64
แอธลอน 64โปรเซสเซอร์ที่ไม่ใช่เซิร์ฟเวอร์ตัวแรกที่รองรับสถาปัตยกรรม x86-64
แอธลอน 64 X2ความต่อเนื่องของสถาปัตยกรรม Athlon 64 มีคอร์ประมวลผล 2 คอร์
แอธลอน เอฟเอ็กซ์
มีชื่อเสียงว่าเป็น "โปรเซสเซอร์ที่เร็วที่สุดสำหรับของเล่น" อันที่จริงมันคือโปรเซสเซอร์เซิร์ฟเวอร์ Opteron 1xx บนซ็อกเก็ตเดสก์ท็อปที่ไม่มีการสนับสนุนหน่วยความจำที่ลงทะเบียน ผลิตเป็นชุดเล็กๆ มีค่าใช้จ่ายสูงกว่าคู่แข่ง "จำนวนมาก" อย่างมาก
ฟีนอมการพัฒนาเพิ่มเติมของสถาปัตยกรรม Athlon 64 มีให้บริการในเวอร์ชันที่มีสองคอร์ (Athlon 64 X2 Kuma), สามคอร์ (Phenom X3 Toliman) และสี่คอร์ (Phenom X4 Agena)
ฟีนอม IIโปรเซสเซอร์ VIA
ซีริกซ์ 3/เวีย ซี3โปรเซสเซอร์ตัวแรกที่เปิดตัวภายใต้แบรนด์ VIA เปิดตัวพร้อมกับเคอร์เนลที่แตกต่างจากทีมพัฒนาต่างๆ ขั้วต่อซ็อกเก็ต 370
การเปิดตัวครั้งแรกนั้นใช้เคอร์เนล Joshua ซึ่ง VIA ได้รับพร้อมกับทีมพัฒนา Cyrix
รุ่นที่สองมาพร้อมกับเคอร์เนล Samuel ซึ่งพัฒนาบนพื้นฐานของ IDT WinChip -3 ที่ไม่เคยเปิดตัว มันมีความโดดเด่นด้วยการไม่มีแคชระดับที่สองและดังนั้นจึงเป็นอย่างมาก ระดับต่ำผลผลิต
รุ่นที่สามมาพร้อมกับแกน Samuel-2 ซึ่งเป็นเวอร์ชันปรับปรุงของแกนก่อนหน้า พร้อมด้วยแคชระดับที่สอง โปรเซสเซอร์ผลิตขึ้นโดยใช้เทคโนโลยีทินเนอร์และลดการใช้พลังงาน หลังจากการเปิดตัวคอร์นี้ ในที่สุดแบรนด์ "VIA Cyrix III" ก็หลีกทางให้กับ "VIA C3"
รุ่นที่สี่มาพร้อมกับแกน Ezra นอกจากนี้ยังมีรุ่น Ezra-T ซึ่งปรับให้ทำงานบนบัสที่ออกแบบมาสำหรับโปรเซสเซอร์ Intel ที่มีคอร์ Tualatin การพัฒนาต่อยอดสู่ทิศทางการประหยัดพลังงาน
รุ่นที่ห้ามาพร้อมกับแกนเนหะมีย์ (C5P) ในที่สุดคอร์นี้ก็ได้รับโปรเซสเซอร์ร่วมความเร็วเต็ม รองรับคำสั่งหรือ .
โปรเซสเซอร์ที่ใช้คอร์ V33 ไม่มีโหมดการจำลอง 8080 แต่รองรับโหมดการกำหนดแอดเดรสแบบขยายด้วยความช่วยเหลือของคำสั่งเพิ่มเติมสองคำสั่ง
โปรเซสเซอร์ NexGen
Nx586ในเดือนมีนาคม พ.ศ. 2537 มีการเปิดตัวโปรเซสเซอร์ NexGen Nx586 ถูกวางตำแหน่งให้เป็นคู่แข่งของ Pentium แต่ในตอนแรกไม่มีโปรเซสเซอร์ร่วมในตัว การใช้บัสของคุณเองจำเป็นต้องใช้ชิปเซ็ตของคุณเอง NxVL (VESA Local Bus) และ NxPCI 820C500 (PCI) และซ็อกเก็ตโปรเซสเซอร์ที่เข้ากันไม่ได้ ชิปเซ็ตได้รับการพัฒนาร่วมกับ VLSI และ Fujitsu Nx586 เป็นโปรเซสเซอร์ระดับซุปเปอร์สเกลาร์และสามารถดำเนินการได้สองคำสั่งต่อรอบสัญญาณนาฬิกา แคช L1 แยกจากกัน (16 KB สำหรับคำแนะนำ + 16 KB สำหรับข้อมูล) ตัวควบคุมแคช L2 ถูกรวมเข้ากับโปรเซสเซอร์ในขณะที่แคชนั้นเปิดอยู่ เมนบอร์ด. เช่นเดียวกับ Pentium Pro Nx586 ก็เป็นโปรเซสเซอร์ RISC ที่อยู่ภายใน การขาดการสนับสนุนคำสั่ง CPUID ในการปรับเปลี่ยนโปรเซสเซอร์นี้ในช่วงแรกทำให้เกิดความจริงที่ว่ามันถูกกำหนดให้เป็นโปรเซสเซอร์ 386 ที่รวดเร็วในซอฟต์แวร์ นี่เป็นเพราะความจริงที่ว่า Windows 95 ปฏิเสธที่จะติดตั้งบนคอมพิวเตอร์ที่มีโปรเซสเซอร์ดังกล่าว เพื่อแก้ไขปัญหานี้ จึงมีการใช้ยูทิลิตี้พิเศษ (IDON.COM) ซึ่งนำเสนอ Nx586 สำหรับ Windows เป็น CPU คลาส 586 Nx586 ผลิตที่โรงงานของ IBM
ตัวประมวลผลร่วม Nx587 FPU ยังได้รับการพัฒนาและติดตั้งมาจากโรงงานที่ด้านบนของดายตัวประมวลผล “ส่วนประกอบ” ดังกล่าวมีป้ายกำกับว่า Nx586Pf เมื่อกำหนดประสิทธิภาพของ Nx586 จะใช้ระดับ P - ตั้งแต่ PR75 (70 MHz) ถึง PR120 (111 MHz)
โปรเซสเซอร์ NexGen รุ่นต่อไปซึ่งไม่เคยเปิดตัว แต่ทำหน้าที่เป็นพื้นฐานสำหรับ AMD K6
โปรเซสเซอร์ SiS
SiS550SoC ตระกูล SiS550 มีพื้นฐานมาจากคอร์ Rise mP6 ที่ได้รับอนุญาต และมีความถี่ตั้งแต่ 166 ถึง 266 MHz ในขณะเดียวกัน โซลูชันที่เร็วที่สุดใช้ไฟเพียง 1.8 วัตต์ แกนกลางมีไปป์ไลน์ 8 ขั้นตอนจำนวนเต็มสามท่อ แคช L1 แยก, 8+8 KB ตัวประมวลผลร่วมในตัวถูกไปป์ไลน์ นอกเหนือจากชุดพอร์ตมาตรฐานแล้ว SiS550 ยังมีแกนวิดีโอ UMA 128 บิต AGP 4x, เสียง 5.1 แชนเนล และรองรับ 2 คำสั่งที่เรียกว่า Code Morphing Software สิ่งนี้ทำให้โปรเซสเซอร์สามารถปรับตัวเข้ากับชุดคำสั่งใดก็ได้และปรับปรุงประสิทธิภาพการใช้พลังงาน แต่ประสิทธิภาพของโซลูชันดังกล่าวต่ำกว่าประสิทธิภาพของโปรเซสเซอร์ที่มีชุดคำสั่ง x86 แบบเนทีฟอย่างเห็นได้ชัด โปรเซสเซอร์ร่วมทางคณิตศาสตร์และตัวแปรที่มีโปรเซสเซอร์ร่วมควรจะเรียกว่า U5D แต่ไม่เคยได้รับการปล่อยตัว
Intel ได้รับคำสั่งศาลจากการขาย Green CPU ในสหรัฐอเมริกา โดยอ้างว่า UMC ใช้ไมโครโค้ดของ Intel ในโปรเซสเซอร์โดยไม่มีใบอนุญาต
นอกจากนี้ยังมีปัญหาบางอย่างกับซอฟต์แวร์ ตัวอย่างเช่น เกม Doom ปฏิเสธที่จะทำงานบนโปรเซสเซอร์นี้โดยไม่เปลี่ยนการกำหนดค่า และ Windows 95 ก็ค้างเป็นครั้งคราว นี่เป็นเพราะความจริงที่ว่าโปรแกรมพบตัวประมวลผลร่วมที่หายไปใน U5S และความพยายามในการเข้าถึงสิ้นสุดลงด้วยความล้มเหลว
โปรเซสเซอร์ที่ผลิตในสหภาพโซเวียตและรัสเซีย
KR1810VM86การออกแบบ BLX IC/โปรเซสเซอร์ ICT
การออกแบบและสถาบัน BLX IC เทคโนโลยีคอมพิวเตอร์ตั้งแต่ปี 2544 ประเทศจีนได้พัฒนาโปรเซสเซอร์ที่ใช้ MIPS พร้อมการแปลฮาร์ดแวร์คำสั่ง x86 โปรเซสเซอร์เหล่านี้ผลิตโดย STMicroelectronics กำลังพิจารณาความร่วมมือกับ TSMC
ก็อดสัน (หลงซิน, หลงสัน, มังกร)
Godson เป็นโปรเซสเซอร์ RISC ที่ใช้ MIPS 32 บิต เทคโนโลยี - 180 นาโนเมตร เปิดตัวในปี 2545 ความถี่ - 266 MHz หนึ่งปีต่อมา - เวอร์ชันที่มีความถี่ 500 MHz
ก็อดสัน 2
- Godson 2 เป็นโปรเซสเซอร์ RISC ที่ใช้ MIPS III 64 บิต เทคโนโลยี 90 นาโนเมตร ที่ความถี่เดียวกันจะเร็วกว่ารุ่นก่อนถึง 10 เท่า เปิดตัวเมื่อวันที่ 19 เมษายน พ.ศ. 2548
- Godson-2E - 500 MHz, 750 MHz ต่อมา - 1 GHz เทคโนโลยี - 90 นาโนเมตร ทรานซิสเตอร์ 47 ล้านตัว การใช้พลังงาน - 5...7.5 W. Godson ตัวแรกที่มีการแปลคำสั่ง x86 ด้วยฮาร์ดแวร์และใช้ประสิทธิภาพของโปรเซสเซอร์มากถึง 60% เปิดตัวในเดือนพฤศจิกายน พ.ศ. 2549
- Godson 2F - 1.2 GHz ผลิตตั้งแต่เดือนมีนาคม 2550 มีการประกาศประสิทธิภาพการผลิตเพิ่มขึ้น 20-30% เมื่อเทียบกับรุ่นก่อน
- Godson 2H - วางแผนเปิดตัวในปี 2554 โดยจะมาพร้อมกับแกนวิดีโอและตัวควบคุมหน่วยความจำในตัว และมีไว้สำหรับระบบผู้บริโภค
- Godson 3 - 4 คอร์, เทคโนโลยี 65 นาโนเมตร การใช้พลังงานประมาณ 20 วัตต์
- Godson 3B - 8 คอร์, เทคโนโลยี 65 นาโนเมตร (วางแผนเปลี่ยนเป็น 28 นาโนเมตร), ความถี่สัญญาณนาฬิกาภายใน 1 GHz พื้นที่คริสตัล - 300 มม. ² ประสิทธิภาพจุดลอยตัวคือ 128 GigaFLOPS การใช้พลังงานของ Godson 8-core คือ 3-40 W. การแปลเป็นโค้ด x86 ดำเนินการโดยใช้ชุดคำสั่ง 200 ชุด โดยมีการใช้ประสิทธิภาพของโปรเซสเซอร์ประมาณ 20% ในการแปล โปรเซสเซอร์มีหน่วยประมวลผล SIMD เวกเตอร์ 256 บิต โปรเซสเซอร์ได้รับการออกแบบเพื่อใช้ในเซิร์ฟเวอร์และระบบฝังตัว
โครงสร้างของคำสั่งตามอำเภอใจมีดังนี้:
- คำนำหน้า (แต่ละรายการเป็นทางเลือก):
- คำนำหน้าหนึ่งไบต์สำหรับการเปลี่ยนโหมดการกำหนดแอดเดรส AddressSize (ค่า 67h)
- คำนำหน้าการเปลี่ยนแปลงเซกเมนต์หนึ่งไบต์ (ค่า 26h, 2Eh, 36h, 3Eh, 64h และ 65h)
- คำนำหน้า BranchHint หนึ่งไบต์เพื่อระบุสาขาสาขาที่ต้องการ (ค่า 2Eh และ 3Eh)
- คำนำหน้า Vex ที่ซับซ้อนสองไบต์หรือสามไบต์ (ไบต์แรกจะมีค่า C4h สำหรับเวอร์ชันสองไบต์เสมอ หรือ C5h สำหรับเวอร์ชันสามไบต์)
- คำนำหน้าการล็อคแบบไบต์เดียวเพื่อป้องกันการแก้ไขหน่วยความจำโดยโปรเซสเซอร์หรือคอร์อื่น (ค่า F0h)
- คำนำหน้า OperandsSize หนึ่งไบต์เพื่อเปลี่ยนขนาดของตัวถูกดำเนินการ (ค่า 66h)
- คำนำหน้าบังคับหนึ่งไบต์เพื่อชี้แจงคำสั่ง (ค่า F2h และ F3h)
- คำนำหน้าการทำซ้ำแบบไบต์เดียวหมายถึงการทำซ้ำ (ค่า F2h และ F3h)
- จำเป็นต้องมีคำนำหน้า Rex ที่มีโครงสร้างหนึ่งไบต์เพื่อระบุการลงทะเบียนแบบ 64 บิตหรือแบบขยาย (มีค่า 40h..4Fh)
- คำนำหน้า Escape ประกอบด้วยไบต์ 0Fh อย่างน้อยหนึ่งไบต์เสมอ ไบต์นี้จะตามด้วยไบต์ 38h หรือ 3Ah หรือไม่ก็ได้ ออกแบบมาเพื่อชี้แจงคำแนะนำ
- ไบต์ที่กำหนดคำสั่งอย่างแม่นยำคือ:
- Opcode ไบต์ (ค่าคงที่โดยพลการ)
- Opcode2 ไบต์ (ค่าคงที่โดยพลการ)
- Params byte (มีโครงสร้างที่ซับซ้อน)
- ไบต์ ModRm ใช้สำหรับผู้ถูกดำเนินการในหน่วยความจำ (มีโครงสร้างที่ซับซ้อน)
- ไบต์ SIB ยังใช้สำหรับตัวถูกดำเนินการหน่วยความจำและมีโครงสร้างที่ซับซ้อน
- ข้อมูลที่อยู่ในคำแนะนำ (ไม่บังคับ):
- การแทนที่หรือที่อยู่ในหน่วยความจำ จำนวนเต็มที่มีเครื่องหมายขนาด 8, 16, 32 หรือ 64 บิต
- ตัวถูกดำเนินการทันทีตัวแรกหรือตัวเดียว (ทันที) สามารถมีขนาด 8, 16, 32 หรือ 64 บิต
- ตัวถูกดำเนินการทันทีที่สอง (Immediate2) หากมีอยู่ โดยปกติจะมีขนาด 8 บิต
ในรายการด้านบนและด้านล่าง สำหรับชื่อทางเทคนิค ชื่อ “เฉพาะเลขละติน เลขอารบิค” และเครื่องหมายลบ “-” พร้อมด้วยขีดล่าง “_” ได้รับการยอมรับ และกรณีนี้คือ CamelCase (คำใดๆ ที่ขึ้นต้นด้วยตัวพิมพ์ใหญ่ และตามด้วยตัวพิมพ์เล็กเท่านั้นแม้ว่าตัวย่อจะเป็น: “ UTF-8" → "Utf8" - ทุกคำรวมกัน) คำนำหน้า AddressSize, Segment, BranchHint, Lock, OperandsSize และ Repeat สามารถผสมเข้าด้วยกันได้ องค์ประกอบที่เหลือจะต้องเป็นไปตามลำดับที่ระบุทุกประการ และจะเห็นว่าค่าไบต์ของคำนำหน้าบางค่าเหมือนกัน วัตถุประสงค์และความพร้อมใช้งานจะขึ้นอยู่กับคำแนะนำด้วยตนเอง คำนำหน้าการแทนที่เซ็กเมนต์สามารถใช้ได้กับคำสั่งส่วนใหญ่ แต่คำนำหน้า BranchHint สามารถใช้ได้เฉพาะกับคำสั่งสาขาแบบมีเงื่อนไขเท่านั้น สถานการณ์คล้ายกับคำนำหน้าบังคับและทำซ้ำ - บางแห่งจะชี้แจงคำแนะนำและบางแห่งระบุว่าเป็นการซ้ำซ้อน คำนำหน้า OperandSize พร้อมด้วยคำนำหน้าบังคับ ยังจัดเป็นคำนำหน้าคำสั่ง SIMD อีกด้วย ควรพูดแยกกันเกี่ยวกับคำนำหน้า Vex โดยจะแทนที่คำนำหน้า Rex, Mandatory, Escape และ OperandsSize โดยกระชับเข้าไว้ในตัวมันเอง ไม่อนุญาตให้ใช้คำนำหน้าล็อคด้วย คุณสามารถเพิ่มคำนำหน้าการล็อคได้เมื่อปลายทางเป็นตัวถูกดำเนินการในหน่วยความจำ
รายการภาพรวมของโหมดทั้งหมดที่น่าสนใจในแง่ของการเข้ารหัสคำสั่ง:
- 16 บิต (“โหมดจริง”, โหมดจริงพร้อมการกำหนดแอดเดรสเซ็กเมนต์)
- 32 บิต (“โหมดที่ได้รับการป้องกัน”, โหมดที่ได้รับการป้องกันพร้อมกับรุ่นหน่วยความจำแบบแบน)
- 64 บิต (“โหมดยาว” เช่น 32 บิตที่ป้องกันด้วยรุ่นหน่วยความจำแบบแบน แต่ที่อยู่เป็นแบบ 64 บิตอยู่แล้ว)
ในวงเล็บ ชื่อภาษาอังกฤษของโหมดต่างๆ จะตรงกับชื่ออย่างเป็นทางการ นอกจากนี้ยังมีโหมดสังเคราะห์ เช่น โหมดไม่จริง (โหมด Unreal x86) แต่ทั้งหมดมีต้นกำเนิดมาจากโหมดทั้งสามนี้ (โดยพื้นฐานแล้ว โหมดเหล่านี้เป็นโหมดผสมที่แตกต่างกันเพียงขนาดของที่อยู่ ตัวถูกดำเนินการ ฯลฯ) แต่ละคนใช้โหมดการกำหนดแอดเดรส "ดั้งเดิม" แต่สามารถเปลี่ยนเป็นรูปแบบอื่นได้โดยใช้คำนำหน้า OperandsSize ในโหมด 16 บิต โหมดการกำหนดแอดเดรส 32 บิตจะถูกเปิดใช้งาน ในโหมด 32 บิต - 16 บิต และในโหมด 64 บิต - 32 บิต แต่ถ้าคุณทำเช่นนี้ ที่อยู่จะถูกขยายด้วยศูนย์ (หากมีขนาดเล็กกว่า) หรือบิตที่สำคัญที่สุดจะถูกรีเซ็ต (หากใหญ่กว่า)
4.6. คุณสมบัติของสถาปัตยกรรมของโปรเซสเซอร์ x86 ที่ทันสมัย
4.6.1. สถาปัตยกรรมโปรเซสเซอร์ Intel Pentium (P5/P6)
โปรเซสเซอร์ตระกูล Pentium มีคุณสมบัติทางสถาปัตยกรรมและโครงสร้างหลายประการเมื่อเทียบกับไมโครโปรเซสเซอร์รุ่นก่อนๆ จากอินเทล. ลักษณะเฉพาะมากที่สุดคือ:
สถาปัตยกรรมของฮาร์วาร์ดที่มีการแยกคำสั่งและข้อมูลออกโดยแนะนำบล็อกหน่วยความจำแคชภายในที่แยกจากกันสำหรับการจัดเก็บคำสั่งและข้อมูล เช่นเดียวกับบัสสำหรับการส่งข้อมูล
สถาปัตยกรรม Superscalar ช่วยให้มั่นใจได้ถึงการดำเนินการหลายคำสั่งพร้อมกันในอุปกรณ์ปฏิบัติการแบบขนาน
การดำเนินการคำสั่งแบบไดนามิก ซึ่งใช้การเปลี่ยนแปลงลำดับคำสั่ง โดยใช้ไฟล์รีจิสเตอร์แบบขยาย (การเปลี่ยนชื่อรีจิสเตอร์) และการทำนายสาขาที่มีประสิทธิภาพ
บัสอิสระคู่ที่มีบัสแยกต่างหากสำหรับการเข้าถึงหน่วยความจำแคช L2 (ทำงานที่ความเร็วสัญญาณนาฬิกาของโปรเซสเซอร์) และบัสระบบสำหรับการเข้าถึงหน่วยความจำและ อุปกรณ์ภายนอก(ทำงานที่ความเร็วสัญญาณนาฬิกาของเมนบอร์ด)
ลักษณะสำคัญของตระกูลโปรเซสเซอร์ Pentium มีดังนี้:
โครงสร้างภายในแบบ 32 บิต
การใช้งาน บัสระบบมี 36 บิตที่อยู่และ 64 บิตข้อมูล
แยกแคช L1 ภายในสำหรับคำแนะนำและข้อมูลที่มีความจุ 16 KB
รองรับคำสั่ง L2 ที่ใช้ร่วมกันและแคชข้อมูลสูงสุด 2 MB
การดำเนินการตามคำสั่งไปป์ไลน์
ทำนายทิศทางการแยกสาขาของซอฟต์แวร์ด้วยความแม่นยำสูง
เร่งการดำเนินการของการดำเนินการจุดลอยตัว
การควบคุมลำดับความสำคัญเมื่อเข้าถึงหน่วยความจำ
รองรับการใช้งานระบบมัลติโปรเซสเซอร์
ความพร้อมใช้งานของเครื่องมือภายในที่ให้การทดสอบตัวเอง การดีบัก และการตรวจสอบประสิทธิภาพ
สถาปัตยกรรมไมโครใหม่ของโปรเซสเซอร์ Pentium(ข้าว. 4.6)และต่อมาก็ขึ้นอยู่กับวิธีการ การประมวลผลซูเปอร์สเกลาร์ .
ภายใต้ ความเหลื่อมล้ำหมายถึงการมีอยู่ มากกว่า หนึ่งไปป์ไลน์สำหรับการประมวลผลคำสั่ง (ตรงข้ามกับสเกลาร์ - สถาปัตยกรรมไปป์ไลน์เดียว)
รูปที่ 4.6 – บล็อกไดอะแกรมของสถาปัตยกรรม Pentium MP
ใน Pentium MP คำสั่งจะถูกกระจายไปยังไปป์ไลน์การดำเนินการอิสระสองรายการ (U และ V) สายพานลำเลียงยูสามารถดำเนินการคำสั่งตระกูล IA-32 ใดก็ได้ รวมถึงคำสั่งจำนวนเต็มและจำนวนจุดลอยตัว สายพานลำเลียง Vออกแบบมาเพื่อดำเนินการคำสั่งจำนวนเต็มอย่างง่ายและคำสั่งจุดลอยตัวบางคำสั่งคำสั่งสามารถส่งไปยังอุปกรณ์แต่ละเครื่องได้พร้อมกัน และเมื่ออุปกรณ์ควบคุมส่งคำสั่งคู่หนึ่งในรอบสัญญาณนาฬิกาหนึ่งรอบ คำสั่งที่ซับซ้อนมากขึ้นจะไปที่ไปป์ไลน์ U และคำสั่งที่ซับซ้อนน้อยกว่าจะไปที่ไปป์ไลน์ V
อย่างไรก็ตาม การประมวลผลคำสั่งแบบคู่ (การจับคู่) ดังกล่าวสามารถทำได้สำหรับชุดคำสั่งจำนวนเต็มจำนวนจำกัดเท่านั้น คำสั่งทางคณิตศาสตร์จริงไม่สามารถรันร่วมกับคำสั่งจำนวนเต็มได้ การออกคำสั่งสองคำสั่งพร้อมกันสามารถทำได้ก็ต่อเมื่อไม่มีการขึ้นต่อกันของการลงทะเบียน
หนึ่งในคุณสมบัติหลักของไมโครโปรเซสเซอร์สถาปัตยกรรม IA-32 รุ่นที่หกคือ พลวัต(เก็งกำไร) การดำเนินการ. คำนี้หมายถึงชุดของความเป็นไปได้ดังต่อไปนี้:
- การทำนายสาขาลึก(ด้วยความน่าจะเป็น >90% คุณสามารถคาดการณ์การเปลี่ยนผ่าน 10-15 ครั้งถัดไป)
- การวิเคราะห์การไหลของข้อมูล(ดูโปรแกรม 20-30 ขั้นตอนข้างหน้าและพิจารณาการพึ่งพาคำสั่งกับข้อมูลหรือทรัพยากร)
- การดำเนินการคำสั่งไปข้างหน้า(MP P6 สามารถดำเนินการคำสั่งตามลำดับที่แตกต่างจากลำดับในโปรแกรม)
องค์กรภายในของ MP P6 สอดคล้องกับสถาปัตยกรรม RISC ดังนั้น บล็อกการดึงคำสั่งโดยอ่านสตรีมคำสั่ง IA-32 จาก L1 แคชคำสั่งถอดรหัสพวกมันออกเป็นชุดของการดำเนินการระดับย่อย กระแสของการปฏิบัติการระดับย่อยตกอยู่ในนั้น เรียงลำดับบัฟเฟอร์ใหม่ (กลุ่มคำสั่ง). ประกอบด้วยทั้งไมโครโอเปอเรชันที่ยังไม่ได้ดำเนินการและที่ดำเนินการแล้ว แต่ยังไม่ส่งผลกระทบต่อสถานะของโปรเซสเซอร์
เพื่อถอดรหัสคำสั่งสามขนาน ตัวถอดรหัส: สองอันสำหรับคำสั่งง่ายๆ และอีกอันสำหรับคำสั่งที่ซับซ้อน
คำสั่ง IA-32 แต่ละตัวจะถูกถอดรหัสเป็น 1-4 ไมโครออปส์ มีการดำเนินการแบบไมโคร แอคชูเอเตอร์แบบขนานห้าตัว: สองสำหรับ เลขคณิตจำนวนเต็มสองสำหรับ เลขคณิตจริงและ บล็อกอินเทอร์เฟซหน่วยความจำดังนั้นจึงเป็นไปได้ที่จะดำเนินการไมโครได้ถึงห้ารายการต่อรอบสัญญาณนาฬิกา
บล็อกแอคชูเอเตอร์ สามารถเลือกคำสั่งจากพูลตามลำดับใดก็ได้ ขณะเดียวกันก็ขอขอบคุณ บล็อกการทำนายสาขาเป็นไปได้ที่จะดำเนินการตามคำสั่งตามสาขาที่มีเงื่อนไข บล็อกความซ้ำซ้อนตรวจสอบในกลุ่มคำสั่งการดำเนินการไมโครที่พร้อมสำหรับการดำเนินการอย่างต่อเนื่อง (ข้อมูลต้นฉบับไม่ได้ขึ้นอยู่กับผลลัพธ์ของคำสั่งอื่นที่ยังไม่ได้ดำเนินการ) และนำพวกเขาไปยังอุปกรณ์ผู้บริหารฟรีในประเภทที่เหมาะสม ตัวกระตุ้นจำนวนเต็มตัวหนึ่งจะตรวจสอบเพิ่มเติมว่าการทำนายสาขานั้นถูกต้องหรือไม่ เมื่อตรวจพบสาขาที่คาดการณ์ไม่ถูกต้อง การดำเนินการย่อยทั้งหมดหลังจากการเปลี่ยนแปลงจะถูกลบออกจากพูล และไปป์ไลน์คำสั่งจะเต็มไปด้วยคำแนะนำในที่อยู่ใหม่
การพึ่งพาคำแนะนำร่วมกันเกี่ยวกับค่าของรีจิสเตอร์สถาปัตยกรรม IA-32 อาจต้องรอให้รีจิสเตอร์ถูกปล่อย เพื่อแก้ปัญหานี้จึงได้รับการออกแบบ ทะเบียนวัตถุประสงค์ทั่วไปภายใน 40 รายการใช้ในการคำนวณจริง
ลบบล็อก ติดตามผลลัพธ์ของการดำเนินการระดับย่อยที่ดำเนินการเชิงคาดเดา หากการดำเนินการระดับย่อยไม่ขึ้นอยู่กับการดำเนินการระดับย่อยอื่นๆ อีกต่อไป ผลลัพธ์จะถูกถ่ายโอนไปยังสถานะตัวประมวลผล และจะถูกลบออกจากบัฟเฟอร์การเรียงลำดับใหม่ บล็อกการลบจะยืนยันการดำเนินการตามคำสั่ง (สูงสุดสาม micro-ops ต่อรอบสัญญาณนาฬิกา) ตามลำดับที่ปรากฏในโปรแกรม โดยคำนึงถึงการขัดจังหวะ ข้อยกเว้น จุดพัก และการคาดการณ์สาขาที่พลาดไป
รูปแบบที่อธิบายไว้จะแสดงในรูป 4.7.
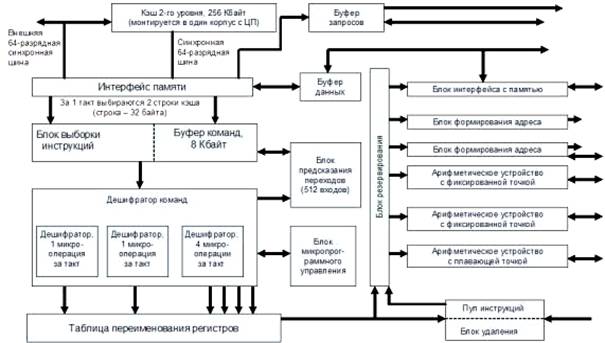
รูปที่ 4.7 – บล็อกไดอะแกรมของไมโครโปรเซสเซอร์ Pentium Pro
4.6.2. ส่วนขยาย SIMD ของ MMX
อัลกอริธึมจำนวนมากสำหรับการทำงานกับข้อมูลมัลติมีเดียอนุญาตให้มีองค์ประกอบที่ง่ายที่สุดของการขนานเมื่อการดำเนินการเดียวสามารถดำเนินการแบบขนานกับตัวเลขหลายตัวได้ วิธีนี้เรียกว่า SIMD – คำสั่งเดียวหลายข้อมูล (หนึ่งคำสั่ง – หลายข้อมูล). เทคโนโลยีนี้ถูกนำมาใช้ครั้งแรกในเจนเนอเรชั่น P55 (ไมโครโปรเซสเซอร์ Pentium MMX)
MMX (ส่วนขยายมัลติมีเดีย)เป็นส่วนขยาย SIMD สำหรับการประมวลผลสตรีมข้อมูลจำนวนเต็ม ซึ่งใช้งานบนพื้นฐานของบล็อก FPU (โดยใช้การลงทะเบียน FPU)
คำสั่ง MMX คำสั่งเดียวสามารถดำเนินการทางคณิตศาสตร์หรือการดำเนินการทางตรรกะกับ "แบทช์" ของจำนวนเต็มที่ถูกบรรจุในรีจิสเตอร์ MMX ตัวอย่างเช่น คำสั่ง PADDSB เพิ่ม 8 ไบต์ของ "แพ็กเก็ต" หนึ่งชุดพร้อมกับ 8 ไบต์ที่สอดคล้องกันของแพ็กเก็ตอื่น ซึ่งดำเนินการบวกตัวเลข 8 คู่ด้วยคำสั่งเดียวได้อย่างมีประสิทธิภาพ
4.6.3. โปรเซสเซอร์ Pentium Pro, Pentium II, Pentium III
โปรเซสเซอร์ Pentium II ผสมผสานคุณสมบัติที่ดีที่สุดของโปรเซสเซอร์ Intel: ประสิทธิภาพของโปรเซสเซอร์ Pentium Pro และความสามารถของเทคโนโลยี MMX การรวมกันนี้ช่วยเพิ่มประสิทธิภาพการทำงานของโปรเซสเซอร์ Pentium II อย่างมีนัยสำคัญ เมื่อเทียบกับโปรเซสเซอร์สถาปัตยกรรม IA-32 รุ่นก่อนหน้า
โปรเซสเซอร์ประกอบด้วยคำสั่งภายใน 16 KB แยกต่างหากและบล็อกแคชข้อมูล และแคช L2 แบบไม่บล็อกที่ใช้ร่วมกัน 512 KB
การเพิ่มประสิทธิภาพของ IA-32 ไม่เพียงทำได้โดยการเพิ่มประสิทธิภาพไปป์ไลน์คำสั่งและการเพิ่มหน่วยดำเนินการเท่านั้น แต่ยังทำได้โดยการแนะนำหน่วยความจำแคชในแกนประมวลผลอีกด้วย ตระกูล IA-32 เปิดตัวแคช L1 บนชิปขนาด 8 KB เป็นครั้งแรกในโปรเซสเซอร์ Intel-486 ในโปรเซสเซอร์ Pentium ขนาดแคชจะเพิ่มเป็นสองเท่า ตัวแทนแรกของ P6 (Pentium Pro) ยังมีแคช L2 ที่ 256 หรือ 512 KB อย่างไรก็ตาม วิธีแก้ปัญหาดังกล่าวในเวลานั้นมีราคาแพงเกินไปและไม่เกิดผลกำไร เทคโนโลยีนี้จึงถูกนำมาใช้ใน Pentium II บัสอิสระคู่ (DIB) –รถบัสอิสระคู่ เพื่อเข้าถึงแคชและเข้าถึง หน่วยความจำภายนอกมีการใช้ยางแยกกัน โซลูชันทางสถาปัตยกรรมแบบเดียวกันนี้ถูกใช้ใน Pentium III รุ่นแรก เริ่มต้นในปี 1999 (Pentium III Coppermine) แคช L2 ถูกส่งกลับอีกครั้งภายในชิปประมวลผล
การพัฒนาแนวคิดของ SIMD สำหรับตัวเลขจริงคือเทคโนโลยี SSE (ส่วนขยาย SIMD แบบสตรีม)เปิดตัวครั้งแรกในโปรเซสเซอร์ Pentium III บล็อก SSE เสริมเทคโนโลยี MMX ด้วยรีจิสเตอร์ XMM0-XMM7 128 บิตแปดตัว และรีจิสเตอร์ควบคุมและสถานะ MXCSR แบบ 32 บิต
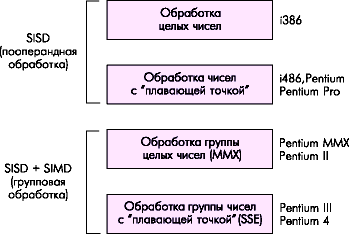
รูปที่ 4.9 - วิวัฒนาการของการประมวลผลข้อมูลในโปรเซสเซอร์ Intel Pentium
4.6.4. Pentium 4 (P7) – สถาปัตยกรรมไมโคร Net Burst
โปรเซสเซอร์ Pentium 4 เป็นตัวแทน 32 บิตของตระกูล IA-32 ในแง่ของสถาปัตยกรรมไมโครมันเป็นของเจนเนอเรชั่นใหม่ที่เจ็ด (ตามการจำแนกประเภทของ Intel) จากมุมมองของซอฟต์แวร์ มันคือโปรเซสเซอร์ IA-32 พร้อมส่วนขยายของระบบคำสั่งอื่น - เอสเอสอี2. ในแง่ของชุดรีจิสเตอร์ที่สามารถเข้าถึงซอฟต์แวร์ได้ Pentium 4 จะจำลองโปรเซสเซอร์ Pentium III จากมุมมองฮาร์ดแวร์ภายนอกนี่คือโปรเซสเซอร์ที่มีบัสระบบรูปแบบใหม่ซึ่งนอกเหนือจากการเพิ่มความถี่สัญญาณนาฬิกาแล้วยังใช้หลักการซิงโครไนซ์สองเท่า (2x) และสี่เท่า (4x) ที่คุ้นเคยอยู่แล้ว และมีมาตรการหลายอย่างเพื่อให้แน่ใจว่าการทำงานที่ความถี่ที่ไม่สามารถจินตนาการได้ก่อนหน้านี้ สถาปัตยกรรมไมโครโปรเซสเซอร์ที่เรียกว่า Net Burst ได้รับการออกแบบโดยคำนึงถึงความถี่สูงของทั้งคอร์ (มากกว่า 1.4 GHz) และบัสระบบ (400 MHz)
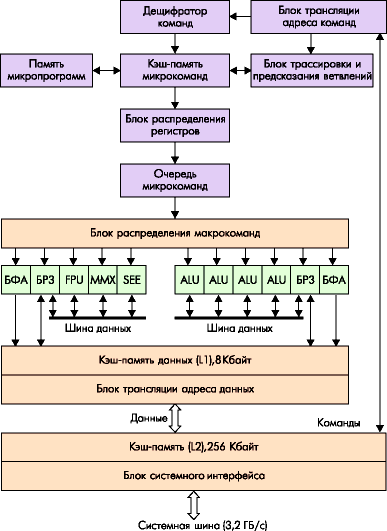
รูปที่ 4.10 – สถาปัตยกรรมไมโคร NetBurst
โปรเซสเซอร์ Pentium 4 เป็นแบบชิปตัวเดียว นอกจากแกนประมวลผลแล้ว ยังมีหน่วยความจำแคชสองระดับ แคชรองซึ่งใช้ร่วมกันระหว่างคำสั่งและข้อมูล มีขนาด 256 KB และมีความกว้างบัส 256 บิต (32 ไบต์) คล้ายกับโปรเซสเซอร์ Pentium III รุ่นล่าสุด แคชบัสรองทำงานที่ความถี่คอร์ ซึ่งให้ปริมาณงาน 32x1.4 = 44.8 GB/s ที่ 1.4 GHz แคชรองมีการควบคุม ECC เพื่อตรวจจับและแก้ไขข้อผิดพลาด แคชข้อมูลหลักมีปริมาณงานสูงเท่ากัน (44.8 GB/s) แต่ขนาดของแคชลดลงครึ่งหนึ่ง (8 KB เทียบกับ 16 ใน Pentium III) โดยทั่วไปแล้ว ไม่มีแคชคำสั่งหลัก แต่จะถูกแทนที่ด้วยแคชการติดตาม โดยจะจัดเก็บลำดับของการดำเนินการระดับย่อยที่มีการถอดรหัสคำสั่ง สามารถใส่คำสั่งย่อยได้ถึง 12K ที่นี่
อินเทอร์เฟซบัสระบบโปรเซสเซอร์ได้รับการออกแบบสำหรับการกำหนดค่าโปรเซสเซอร์ตัวเดียวเท่านั้น อินเทอร์เฟซมีลักษณะคล้ายกับบัส P6 ในหลาย ๆ ด้าน โปรโตคอลยังมุ่งเน้นไปที่การดำเนินการหลายธุรกรรมพร้อมกัน มีการใช้มาตรการหลายประการเพื่อให้แน่ใจว่ามีปริมาณงานสูง โปรเซสเซอร์ Pentium 4 มีความถี่บัส 400 MHz โดยมี "quad pumped" - ความถี่สัญญาณนาฬิกาบัสของระบบคือ 100 MHz แต่ความถี่ของที่อยู่และการถ่ายโอนข้อมูลจะสูงกว่า ข้อมูลใหม่สามารถส่งผ่านสายที่มีการซิงโครไนซ์ทั่วไปในแต่ละรอบสัญญาณนาฬิกาด้วยความถี่ 100 MHz สำหรับการส่ง 2 และ 4 ครั้ง จะใช้การซิงโครไนซ์จากแหล่งข้อมูล
แอคทูเอเตอร์ MP (ALU) ทำงานที่ความถี่สองเท่า ซึ่งทำให้สามารถดำเนินการคำสั่งจำนวนเต็มส่วนใหญ่ได้ในครึ่งรอบสัญญาณนาฬิกา เมื่อเปรียบเทียบกับ IA-32 รุ่นก่อนหน้า Pentium 4 มีไปป์ไลน์คำสั่งที่ยาวที่สุด ซึ่งประกอบด้วย 20 สเตจและเรียกว่า ไฮเปอร์ไปป์ไลน์. ผู้เชี่ยวชาญหลายคนทราบว่าสถาปัตยกรรมไมโคร NetBurst จะมีประสิทธิภาพสูงสุดสำหรับการดำเนินการในส่วนที่คาดเดาได้ (เชิงเส้นและแบบวน) ของโปรแกรม ซึ่งเป็นเรื่องปกติสำหรับแอปพลิเคชันที่มุ่งเป้าหมายไปที่ Pentium 4 สำหรับโปรแกรมที่แตกแขนงอย่างคาดเดาไม่ได้ ซึ่งรวมถึง ตัวอย่างเช่น แอปพลิเคชันในสำนักงาน ไฮเปอร์ไปป์ไลน์แบบยาวจะมีประสิทธิภาพน้อยกว่าไปป์ไลน์ P6 หากสามารถโอเวอร์คล็อกได้ที่ความถี่ 1.4 GHz และสูงกว่า เพื่อชดเชยข้อบกพร่องนี้บางส่วน กลไกการดำเนินการเชิงคาดเดาและการคาดการณ์สาขาจึงได้รับการปรับปรุงให้เหมาะสมอย่างมีนัยสำคัญ
เนื้อหาในบทที่ 4 อิงจากการสังเคราะห์ผลงาน
ปัจจุบันมีสถาปัตยกรรมโปรเซสเซอร์ที่ได้รับความนิยมมากที่สุดสองแห่ง นี่คือ x86 ซึ่งได้รับการพัฒนาย้อนกลับไปในยุค 80 และถูกนำมาใช้ คอมพิวเตอร์ส่วนบุคคลและ ARM - ทันสมัยกว่าซึ่งช่วยให้คุณทำให้โปรเซสเซอร์มีขนาดเล็กลงและประหยัดยิ่งขึ้น ใช้ในอุปกรณ์เคลื่อนที่หรือแท็บเล็ตส่วนใหญ่
สถาปัตยกรรมทั้งสองมีข้อดีและข้อเสีย รวมถึงขอบเขตการใช้งาน แต่ก็มีคุณสมบัติทั่วไปเช่นกัน ผู้เชี่ยวชาญหลายคนกล่าวว่า ARM คืออนาคต แต่ก็ยังมีข้อเสียบางอย่างที่ x86 ไม่มี ในบทความของเราวันนี้ เราจะดูว่าสถาปัตยกรรมของแขนแตกต่างจาก x86 อย่างไร ลองดูความแตกต่างพื้นฐานระหว่าง ARM และ x86 แล้วลองพิจารณาว่าอันไหนดีกว่ากัน
สถาปัตยกรรมคืออะไร?
โปรเซสเซอร์เป็นส่วนประกอบหลักของอุปกรณ์คอมพิวเตอร์ ไม่ว่าจะเป็นสมาร์ทโฟนหรือคอมพิวเตอร์ ประสิทธิภาพจะกำหนดว่าอุปกรณ์จะทำงานได้เร็วแค่ไหนและใช้พลังงานจากแบตเตอรี่ได้นานเพียงใด พูดง่ายๆ ก็คือ สถาปัตยกรรมโปรเซสเซอร์คือชุดคำสั่งที่สามารถใช้เพื่อเขียนโปรแกรมและนำไปใช้ในฮาร์ดแวร์โดยใช้การผสมผสานเฉพาะของทรานซิสเตอร์โปรเซสเซอร์ สิ่งเหล่านี้คือสิ่งที่อนุญาตให้โปรแกรมโต้ตอบกับฮาร์ดแวร์และกำหนดวิธีการถ่ายโอนและอ่านข้อมูลจากหน่วยความจำ
ในขณะนี้ มีสถาปัตยกรรมสองประเภท: CISC (คอมพิวเตอร์ชุดคำสั่งที่ซับซ้อน) และ RISC (คอมพิวเตอร์ชุดคำสั่งที่ลดลง) ประการแรกถือว่าโปรเซสเซอร์จะใช้คำสั่งในทุกโอกาส ประการที่สอง RISC กำหนดให้นักพัฒนามีหน้าที่สร้างโปรเซสเซอร์ด้วยชุดคำสั่งขั้นต่ำที่จำเป็นสำหรับการดำเนินการ คำสั่ง RISC มีขนาดเล็กลงและง่ายกว่า

สถาปัตยกรรม x86
สถาปัตยกรรมโปรเซสเซอร์ x86 ได้รับการพัฒนาในปี 1978 และปรากฏตัวครั้งแรกในโปรเซสเซอร์ Intel และเป็นประเภท CISC ชื่อของมันนำมาจากโปรเซสเซอร์รุ่นแรกที่มีสถาปัตยกรรมนี้ - Intel 8086 เมื่อเวลาผ่านไปเนื่องจากขาด ทางเลือกที่ดีที่สุดผู้ผลิตโปรเซสเซอร์รายอื่นๆ เช่น AMD ก็เริ่มสนับสนุนสถาปัตยกรรมนี้เช่นกัน ตอนนี้มันเป็นมาตรฐานสำหรับ คอมพิวเตอร์ตั้งโต๊ะ, แล็ปท็อป เน็ตบุ๊ก เซิร์ฟเวอร์ และอุปกรณ์อื่นๆ ที่คล้ายคลึงกัน แต่บางครั้งมีการใช้โปรเซสเซอร์ x86 ในแท็บเล็ตซึ่งถือเป็นวิธีปฏิบัติทั่วไป
โปรเซสเซอร์ Intel 8086 ตัวแรกมีความจุ 16 บิตจากนั้นในปี 2000 โปรเซสเซอร์สถาปัตยกรรม 32 บิตได้เปิดตัวและต่อมาก็มีสถาปัตยกรรม 64 บิตปรากฏขึ้นในภายหลัง เราได้พูดคุยเรื่องนี้โดยละเอียดในบทความแยกต่างหาก ในช่วงเวลานี้สถาปัตยกรรมได้รับการพัฒนาอย่างมากโดยมีการเพิ่มชุดคำสั่งและส่วนขยายชุดใหม่ซึ่งสามารถเพิ่มประสิทธิภาพของโปรเซสเซอร์ได้อย่างมาก
x86 มีข้อเสียที่สำคัญหลายประการ ประการแรกนี่คือความซับซ้อนของคำสั่งความซับซ้อนซึ่งเกิดขึ้นเนื่องจากประวัติศาสตร์อันยาวนานของการพัฒนา ประการที่สองโปรเซสเซอร์ดังกล่าวใช้พลังงานมากเกินไปและสร้างความร้อนมากด้วยเหตุนี้ วิศวกร x86 เริ่มใช้เส้นทางการได้มา ประสิทธิภาพสูงสุดและความเร็วต้องใช้ทรัพยากร ก่อนที่เราจะดูความแตกต่างระหว่าง arm x86 เรามาพูดถึงสถาปัตยกรรม ARM กันก่อน
สถาปัตยกรรม ARM
สถาปัตยกรรมนี้เปิดตัวช้ากว่า x86 ในปี 1985 เล็กน้อย ได้รับการพัฒนาโดย Acorn บริษัท อังกฤษที่มีชื่อเสียง จากนั้นสถาปัตยกรรมนี้เรียกว่า Arcon Risk Machine และเป็นของประเภท RISC แต่จากนั้น Advanted RISC Machine เวอร์ชันปรับปรุงก็ได้เปิดตัว ซึ่งปัจจุบันรู้จักกันในชื่อ ARM
เมื่อพัฒนาสถาปัตยกรรมนี้ วิศวกรตั้งเป้าหมายที่จะขจัดข้อบกพร่องทั้งหมดของ x86 และสร้างสถาปัตยกรรมใหม่ทั้งหมดและมีประสิทธิภาพมากที่สุด ชิป ARM ได้รับการใช้พลังงานน้อยที่สุดและราคาต่ำ แต่มีประสิทธิภาพต่ำเมื่อเทียบกับ x86 ดังนั้นในตอนแรกจึงไม่ได้รับความนิยมมากนักในคอมพิวเตอร์ส่วนบุคคล
ต่างจาก x86 ตรงที่นักพัฒนาพยายามลดต้นทุนทรัพยากรให้น้อยที่สุดในตอนแรก คำแนะนำน้อยลงโปรเซสเซอร์, ทรานซิสเตอร์น้อยลง แต่มีคุณสมบัติเพิ่มเติมน้อยลงตามลำดับ แต่ประสิทธิภาพของโปรเซสเซอร์ ARM ได้รับการปรับปรุงในช่วงไม่กี่ปีที่ผ่านมา เมื่อพิจารณาถึงสิ่งนี้และการใช้พลังงานต่ำ พวกเขาจึงเริ่มมีการใช้กันอย่างแพร่หลาย อุปกรณ์เคลื่อนที่เช่นแท็บเล็ตและสมาร์ทโฟน
ความแตกต่างระหว่าง ARM และ x86
และตอนนี้เราได้ดูประวัติความเป็นมาของการพัฒนาสถาปัตยกรรมเหล่านี้และความแตกต่างพื้นฐานแล้ว เรามาทำการเปรียบเทียบโดยละเอียดของ ARM และ x86 ตามคุณลักษณะต่างๆ เพื่อดูว่าอันไหนดีกว่าและแม่นยำกว่าเพื่อทำความเข้าใจว่าความแตกต่างคืออะไร
การผลิต
การผลิต x86 vs arm นั้นแตกต่างกัน มีเพียงสองบริษัทเท่านั้นที่ผลิตโปรเซสเซอร์ x86: Intel และ AMD ในตอนแรก นี่เป็นบริษัทเดียว แต่นั่นเป็นเรื่องราวที่แตกต่างไปจากเดิมอย่างสิ้นเชิง มีเพียงบริษัทเหล่านี้เท่านั้นที่มีสิทธิ์ผลิตโปรเซสเซอร์ดังกล่าว ซึ่งหมายความว่ามีเพียงพวกเขาเท่านั้นที่จะควบคุมทิศทางของการพัฒนาโครงสร้างพื้นฐาน
ARM ทำงานแตกต่างออกไปมาก บริษัทที่พัฒนา ARM จะไม่เปิดเผยอะไรเลย พวกเขาเพียงแค่ออกใบอนุญาตในการพัฒนาโปรเซสเซอร์ของสถาปัตยกรรมนี้ และผู้ผลิตก็สามารถทำทุกอย่างที่ต้องการได้ เช่น ผลิตชิปเฉพาะด้วยโมดูลที่พวกเขาต้องการ
จำนวนคำแนะนำ
นี่คือความแตกต่างที่สำคัญระหว่างสถาปัตยกรรม arm และ x86 โปรเซสเซอร์ x86 พัฒนาอย่างรวดเร็วและมีประสิทธิภาพมากขึ้น นักพัฒนาได้เพิ่มคำสั่งโปรเซสเซอร์จำนวนมากและไม่ได้มีเพียงชุดพื้นฐานเท่านั้น แต่มีคำสั่งมากมายที่สามารถทำได้โดยไม่ต้องใช้ เริ่มแรกทำเพื่อลดจำนวนหน่วยความจำที่โปรแกรมบนดิสก์ครอบครอง ตัวเลือกมากมายสำหรับการป้องกันและการจำลองเสมือน การเพิ่มประสิทธิภาพ และอื่นๆ อีกมากมายยังได้รับการพัฒนาอีกด้วย ทั้งหมดนี้ต้องการทรานซิสเตอร์และพลังงานเพิ่มเติม
ARM นั้นง่ายกว่า มีคำสั่งโปรเซสเซอร์น้อยกว่ามากที่นี่ เฉพาะคำสั่งที่จำเป็นเท่านั้น ระบบปฏิบัติการและนำไปใช้จริง หากเราเปรียบเทียบ x86 จะมีการใช้คำแนะนำที่เป็นไปได้ทั้งหมดเพียง 30% เท่านั้น เรียนรู้ได้ง่ายกว่าหากคุณตัดสินใจเขียนโปรแกรมด้วยมือ และยังต้องใช้ทรานซิสเตอร์น้อยลงอีกด้วย
การใช้พลังงาน
ข้อสรุปอีกประการหนึ่งเกิดขึ้นจากย่อหน้าก่อนหน้า ยิ่งมีทรานซิสเตอร์บนบอร์ดมาก พื้นที่และการใช้พลังงานก็จะยิ่งใหญ่ขึ้น และสิ่งที่ตรงกันข้ามก็เป็นจริงเช่นกัน
โปรเซสเซอร์ x86 ใช้พลังงานมากกว่า ARM มาก แต่ขนาดของทรานซิสเตอร์เองก็ได้รับผลกระทบจากการใช้พลังงานเช่นกัน ตัวอย่างเช่น โปรเซสเซอร์ Intel i7 ใช้พลังงาน 47 วัตต์ และโปรเซสเซอร์สมาร์ทโฟน ARM ใดๆ ใช้พลังงานไม่เกิน 3 วัตต์ ก่อนหน้านี้ มีการผลิตบอร์ดที่มีองค์ประกอบเดียวขนาด 80 นาโนเมตร จากนั้น Intel ก็ประสบความสำเร็จในการลดขนาดลงเหลือ 22 นาโนเมตร และในปีนี้ นักวิทยาศาสตร์สามารถสร้างบอร์ดที่มีองค์ประกอบขนาด 1 นาโนเมตรได้ ซึ่งจะช่วยลดการใช้พลังงานได้อย่างมากโดยไม่สูญเสียประสิทธิภาพ

ในช่วงไม่กี่ปีที่ผ่านมา การใช้พลังงานของโปรเซสเซอร์ x86 ลดลงอย่างมาก ตัวอย่างเช่น โปรเซสเซอร์ Intel Haswell ใหม่สามารถใช้แบตเตอรี่ได้นานขึ้น ตอนนี้ความแตกต่างระหว่าง arm กับ x86 ก็ค่อยๆหายไป
การกระจายความร้อน
จำนวนทรานซิสเตอร์ส่งผลต่อพารามิเตอร์อื่น - การสร้างความร้อน อุปกรณ์ที่ทันสมัยไม่สามารถเปลี่ยนพลังงานทั้งหมดให้เป็นพลังงานที่มีประสิทธิผลได้ส่วนหนึ่งจึงสลายไปในรูปของความร้อน ประสิทธิภาพของบอร์ดจะเท่าเดิม ซึ่งหมายความว่ายิ่งทรานซิสเตอร์น้อยลงและมีขนาดเล็กลง โปรเซสเซอร์ก็จะสร้างความร้อนน้อยลงเท่านั้น คำถามนี้จะไม่เกิดขึ้นอีกต่อไปว่า ARM หรือ x86 จะสร้างความร้อนน้อยลงหรือไม่
ประสิทธิภาพของโปรเซสเซอร์
เดิมที ARM ไม่ได้ออกแบบมาเพื่อประสิทธิภาพสูงสุด แต่นี่คือจุดที่ x86 เหนือกว่า ส่วนหนึ่งเนื่องมาจากจำนวนทรานซิสเตอร์ที่น้อยลง แต่เมื่อเร็ว ๆ นี้ ประสิทธิภาพของโปรเซสเซอร์ ARM เพิ่มขึ้น และสามารถใช้งานได้อย่างเต็มที่ในแล็ปท็อปหรือเซิร์ฟเวอร์แล้ว
ข้อสรุป
ในบทความนี้ เราได้ดูว่า ARM แตกต่างจาก x86 อย่างไร ความแตกต่างค่อนข้างร้ายแรง แต่ช่วงนี้เส้นแบ่งระหว่างสถาปัตยกรรมทั้งสองเริ่มไม่ชัดเจน โปรเซสเซอร์ ARM มีประสิทธิผลมากขึ้นและเร็วขึ้น และด้วยการลดขนาดขององค์ประกอบโครงสร้างของบอร์ด โปรเซสเซอร์ x86 จึงเริ่มใช้พลังงานน้อยลงและสร้างความร้อนน้อยลง คุณสามารถค้นหาโปรเซสเซอร์ ARM บนเซิร์ฟเวอร์และแล็ปท็อปและ x86 บนแท็บเล็ตและสมาร์ทโฟนได้แล้ว
คุณคิดอย่างไรเกี่ยวกับ x86 และ ARM เหล่านี้ คุณคิดว่าเทคโนโลยีแห่งอนาคตคืออะไร? เขียนในความคิดเห็น! อนึ่ง, .
เพื่อสรุปวิดีโอเกี่ยวกับการพัฒนาสถาปัตยกรรม ARM: