Процесори Intel - як влаштовані основні принципи. Процесор. Типи та відмінності процесорів
Етапи розвитку МП, відповідні досягнення, основні архітектурні та інші характеристики природно розглянути з урахуванням МП фірми Intel (INTegrated ELectronics). Є також ряд фірм - AMD (Advanced Micro Devices), Cyrix, Texas Instruments та ін, які своїми виробами більш менш успішно конкурують з корпорацією Intel.
Основні параметри МП такі:
- тактова частота;
- ступінь інтеграції мікросхеми (скільки транзисторів міститься у чипі);
- внутрішня розрядність даних (кількість біт, які МП може обробляти одночасно);
- зовнішня розрядність даних (кількість біт, що одночасно передаються, в процесі обміну даними ЦП з іншими елементами);
- пам'ять, що адресується (залежить від числа адресних біт).
Процесори Intel
(22 березня 1993 р.). Pentium є  суперскалярний процесор з 32-бітовою адресною шиною та 64-бітовою шиною даних, виготовлений за субмікронною технологією з компліментарною МОП-структурою, що складається з 3,1 млн транзисторів (на площі 16,25 см2). Процесор включає такі блоки:
суперскалярний процесор з 32-бітовою адресною шиною та 64-бітовою шиною даних, виготовлений за субмікронною технологією з компліментарною МОП-структурою, що складається з 3,1 млн транзисторів (на площі 16,25 см2). Процесор включає такі блоки:
- Ядро (Core). Основний виконавчий устрій. Продуктивність МП при тактовій частоті 66 МГц становить близько 112 млн. команд на секунду (MIPS). У порівнянні з процесором 80486 DX було досягнуто 5-кратне збільшення продуктивності завдяки двом конвеєрам, які дозволяють виконати одночасно кілька команд.
- Провісник переходів (Branch Predictor) намагається вгадати напрямок розгалуження програми та заздалегідь завантажити інформацію до блоків передвиборки та декодування команд.
- Буфер адреси переходів (Branch Target Buffer BTB) забезпечує динамічний прогноз переходів. Принцип дії: «Якщо прогноз правильне, то ефективність збільшуємося, а якщо ні, то конвеєр доводиться скидати повністю». Згідно з даними Intel, вірогідність правильного прогнозування переходів у процесорах Pentium становить 75-80%.
- Блок плаваючої точки (Floating Point Unit) виконує обробку чисел із плаваючою точкою. Обробка графічної інформації, мультимедіа-додатків та інтенсивне використання ПК для вирішення обчислювальних завдань вимагають високої продуктивності при виконанні операцій із плаваючою точкою.
- Кеш-пам'ять 1-го рівня (Level I Cache). Процесор має два банки пам'яті по 8 Кбайт, 1-й - для команд, 2-й - для даних, які мають більшу швидкодію, ніж більш ємна зовнішня пам'ятькеш-пам'ять (L2 cache)
- Інтерфейс шини (Bus Interface). Передає ЦП потік команд і даних, і навіть передає дані з ЦП.
У процесорі Pentium введено режим керування системою SMM (System Management Mode). Цей режим дає можливість реалізовувати системні функції дуже високого рівня, включаючи керування живленням або захист, прозорі для ОС та додатків, що виконуються.
Перехід на тактову частоту 60 МГц і вище був значним досягненням, і відповідним чином вирішені проблеми охолодження (поверхня процесора при цьому нагрівається до 85 °С).
(1 листопада 1995 р.). У Pentium Pro для підвищення продуктивності було використано буферну пам'ять (кеш) другого рівня ємністю 256 Кбайт, розташовану в окремому чіпі та змонтовану в корпусі ЦП. В результаті стало можливим ефективне розвантаження п'яти виконавчих пристроїв: два блоки цілісної арифметики; блок завантаження; блок запису; FPU (Floating-Point Unit - пристрій арифметичних операцій із плаваючою точкою).
Pentium P55 (Pentium MMX), 8 січня 1997 р. Pentium MMX - версія Pentium з додатковими можливостями. Технологія ММХ мала додати/розширити мультимедіа можливості комп'ютерів. Реалізовано методику SIMD (ОКМД), орієнтовану на алгоритми та типи даних, характерні для програмного забезпеченнямультимедіа. ММХ оголошено січні 1997 р., тактова частота 166 і 200 МГц, у червні цього року з'явилася версія 233 МГц. Технологічний процес 0,35 мкм, 4,5 млн. транзисторів.
(7 травня 1997 р.). Процесор є модифікацією Pentium Pro з підтримкою можливостей ММХ. Перші PII оголошено як процесори для настільних високопродуктивних (high-end) комп'ютерів. Було змінено конструкцію корпусу - кремнієву пластину з контактами замінили на картридж, збільшено частоту шини та тактову частоту, розширено ММХ-команди.
Є також модель для ноутбуків – Pentium II РЕ та для робочих станцій – Pentium II Хеоn 450 МГц.
Celeron(15 квітня 1998 р.). Celeron – спрощений варіант Р2 для дешевих комп'ютерів. Основні відмінності цих процесорів обсягом кеша другого рівня частоті шини. Всі ці процесори виконані за 0,25 мкм технології та мають від 7,5 до 19 млн транзисторів.
(26 лютого 1999 р.). Р3 - один із найпродуктивніших процесорів Intel, але у своїй конструкції він мало чим відрізняється від Р2, збільшено частоту і додано близько 70 нових команд. У жовтні 1999 р. також випущено версію для мобільних комп'ютерів, Виконана за 0,18 мкм технології з частотами від 400 до 733 МГц. Для робочих станцій та серверів існує РЗ Хеоn, орієнтований на системну логіку GX з об'ємом кешу другого рівня 512 Кбайт, 1 або 2 Мбайт. Технологічний процес 0,25 мкм, системна шина працює на частоті 100 МГц, є 0,18 мкм версія із частотою шини 133 МГц, а також моделі на 600, 666 та 733 МГц.
(Willamette, 2000; Northwood, 2002). Звісно, рано чи пізно архітектура РIII мала застаріти. Справа в тому, що досягнувши частоти в 1 ГГц, Intel зіткнулася з проблемами в подальшому нарощуванні частоти своїх процесорів: Pentium III на 1.13 ГГц довелося відкликати через його нестабільність. Подальше нарощування частоти існуючих процесорів призводить до меншого зростання їхньої продуктивності. Проблема в тому, що латентності (затримки), що виникають при зверненні до тих чи інших вузлів процесора, Р6 вже занадто великі.
Таким чином з'явився Pentium IV - у його основі лежить архітектура, названа Intel NetBurst architecture. Цією назвою Intel хотіла підкреслити, що основна мета нового процесора - прискорити виконання завдань потокової обробки даних, що безпосередньо пов'язані з бурхливо розвиваються Internet і мультимедіа технологіями.
Архітектура NetBurst має у своїй основі кілька інновацій, що в комплексі дозволяють досягти кінцевої мети - забезпечити запас швидкодії та майбутню нарощуваність для процесорів сімейства Pentium IV. До основних технологій входять:
- Hyper Pipelined Technology – конвеєр Pentium IV включає 20 стадій;
- Advanced Dynamic Execution - покращене передбачення переходів і виконання команд зі зміною порядку їхнього прямування (out of order execution);
- Trace Cache - для кешування декодованих команд Pentium IV використовується спеціальний кеш;
- Rapid Execute Engine – ALU процесора Pentium IV працює на частоті, удвічі більшій, ніж сам процесор;
- SSE2 - розширений набір команд обробки потокових даних;
- 400 МГц System Bus – нова системна шина.
Pentium IV Prescott(Лютий 2004 р.). На початку лютого 2004 р. Intel анонсувала чотири нові процесори Pentium IV (2,8; 3,0; 3,2 і 3,4 ГГц), заснованих на ядрі Prescott, яке включає ряд нововведень. Разом з випуском чотирьох нових процесорів Intel представила процесор Pentium IV 3.4 ЕЕ (Extreme Edition), заснований на ядрі Northwood і 2 Мбайт кеш-пам'яті третього рівня, а також спрощену версію Pentium IV 2.8 А, засновану на ядрі Prescott з обмеженою частотою шини ( 533 МГц).
Нові процесори мають таку ж конструкцію, що і засновані на ядрі Northwood, тому для їх відмінності Intel ввела новий індекс у назві процесора - Е. Наприклад, процесор Pentium IV 3.2 С заснований на ядрі Northwood, має підтримку 800 МГц шини та технології НТ, той час, як Pentium IV 3.2 Е виконаний на ядрі Prescott і також підтримує 800 МГц шину та технологію НТ.
Prescott виконаний за технологією 90 нм, що дозволило зменшити площу самого кристала, при цьому загальна кількість транзисторів була збільшена більш ніж у 2 рази. У той час як ядро Northwood має площу 145 мм2 і на ньому розміщено 55 млн. транзисторів, ядро Prescott має площу 122 мм2 і містить 125 млн. транзисторів.
Процесори Cyrix
Оприлюднений у жовтні 1995 р., 6x86 був  першим сумісним з Pentium процесором, що дозволяло проникнути на ринок і досягти співпраці з IBM Microelectronics Division. Прийняття 6x86 було спочатку повільним, тому що Cyrix встановив занадто високі ціни, помилково думаючи, що оскільки ефективність процесора була порівнянна з Intel, його ціна могла бути такою ж. Як тільки Cyrix переглянув свої позиції, чіп став значно впливати на частку відповідного сектора ринку як високоефективна альтернатива серії Pentium.
першим сумісним з Pentium процесором, що дозволяло проникнути на ринок і досягти співпраці з IBM Microelectronics Division. Прийняття 6x86 було спочатку повільним, тому що Cyrix встановив занадто високі ціни, помилково думаючи, що оскільки ефективність процесора була порівнянна з Intel, його ціна могла бути такою ж. Як тільки Cyrix переглянув свої позиції, чіп став значно впливати на частку відповідного сектора ринку як високоефективна альтернатива серії Pentium.
Починаючи з 6x86, процесори Cyrix були здатні до рівня продуктивності, еквівалентного чіпу Pentium, але за більш низької частоти. Для оцінки продуктивності використовується Processor Performance Rating – Р-рейтинг (позначення Р100+, наприклад, символізує продуктивність, еквівалентну Pentium із частотою 100 МГц). Процесори Cyrix (як і AMD) традиційно працюють на нижчих частотах, ніж чисельне значення їхнього Р-рейтингу, без помітного зниження продуктивності. Наприклад, Р133+ (Р-рейтинг) працює на частоті 110 МГц, тоді як Р150+ та Р166+ працюють на 120 та 133 МГц відповідно.
Перевага 6x86 випливало з удосконалень архітектури чіпа, яка дозволила 6x86 отримувати доступ до її внутрішнього кешу та регістрів в одному циклі частоти (Pentium зазвичай задіює два або більше циклів для доступу до кешу). Крім того, первинний кеш 6х86 був об'єднаний, замість того, щоб включити дві окремі секції 8 Кбайт для команд і даних. Ця об'єднана модель була здатна зберігати команди та дані у будь-якому відношенні, забезпечуючи «ймовірність попадання» кешу в межах 90%. ЦП містить 3,5 млн. транзисторів, спочатку виготовлених за технологією п'яти 0,5-мікронних шарів. Інтерфейс - Socket 7. Напруга живлення ядра - 3,3 В. Характеристики 6x86 подібні до Pentium. Однак він включає і нові характеристики: видалення залежності даних, передбачення переходів, виконання команд поза природним порядком (можливість швидших команд виходити з черги конвеєра, не порушуючи процес виконання програми). Все це підвищує рівень продуктивності 6×86, на відміну від Pentium з такою самою частотою.
Однак процесори 6x86 стикалися з безліччю проблем, особливо перегрівом, низькою продуктивністю при роботі з комою, що плаває, і несумісністю з Windows NT. Це несприятливо вплинуло на успіх процесора, і конкуренція з Pentium виявилася недовгою і закінчилася із запуском Intel Pentium ММХ.
Cyrix MediaGX. Введення процесора MediaGX у лютому 1997 р. визначило першу нову архітектуру PC у десятилітті та визначило новий сегмент ринку – дешевий «Основний ПК». Зростання цього ринку було бурхливим, і технологія процесора Cyrix та нововведення рівня системи були ключовим елементом.
Чим більше процесів, що обробляються на центральному процесорі ПК безпосередньо, тим вища загальна продуктивність системи. У традиційних комп'ютерних розробках центральний процесор обробляє дані на частоті в мегагерці, у той час як шина, яка переміщає дані в (та й) інші компоненти, працює тільки на половинній швидкості або навіть менше. Це означає, що рух даних до (і від) центрального процесора займає більше часу. Cyrix усунув це вузьке місце запровадженням технологією MediaGX. Архітектура MediaGX поєднує графічні та звукові функції, інтерфейс PCI та диспетчера пам'яті в блок процесора, таким чином усуваючи потенційні конфлікти системи та проблеми конфігурації кінцевого користувача. Вона складається з двох чіпів – процесора MediaGX та співпроцесора MediaGX Cx5510. Процесор використовує спеціальне гніздо, що вимагає спеціально розробленої материнської плати. MediaGX - х86-сумісний процесор, який безпосередньо з'єднує на шині PCI та пам'ять EDO DRAM по виділеній 64-бітовій шині даних. Cyrix стверджує, що техніка стиснення, що використовується на шині даних, усуває потребу в кеші другого рівня. Є об'єднаний (16 Кбайт) кеш першого рівня на центральному процесорі – того ж обсягу, що й на стандартному чіпі Pentium. Графіка обробляється спеціальним конвеєром на центральному процесорі безпосередньо, і контролер монітора також знаходиться на головному процесорі. Немає жодної відеопам'яті, буфера кадрів, що зберігаються в головній пам'яті (традиційна Unified Memory Architecture - UMA), натомість використовується власна Cyrix Display Compression Technology (DCT). Операції з даними VGA виконуються апаратними засобами ЕОМ, але регістри VGA управляються програмами Cyrix – Virtual System Architecture (VSA). Супутній чіп MediaGX Cx5510 містить аудіоконтроллер і також використовує програми VSA, щоб емулювати можливості стандартних звукових карток. Цей чіп з'єднує процесор MediaGX через шину PCI з шиною ISA, а також з IDE та портами вводу-виводу, тобто виконує традиційні функції чіпсету.
Відповіддю Cyrix на технологію Intel MMX був 6х86МХ, запущений у середині 1997 р., незадовго до того, як компанія була придбана компанією National Semiconductor. Компанія залишилася вірною формату Socket 7 для свого нового чіпа, це підтримувало на потрібному рівні витрати виробників системи та, зрештою, споживачів, продовжуючи життя існуючого чіпа та системних плат.
Архітектура нового чіпа залишалася по суті тією самою, як і в його попередника, з доповненням команд ММХ, деякими покращеннями до Floating Point Unit, великим (64 Кбайт) універсальним кешем першого рівня та розширеним блоком управління пам'яттю.
Процесор 6х86МХ був добре прийнятий на ринку, оскільки 6х86MX/PR233 (працюючий на частоті 187 МГц) виявився швидше ніж Pentium II (233 МГц) і AMD Кб. MX був також першим провідним процесором, здатним до роботи на зовнішній шині 75 МГц, що забезпечувало очевидні переваги смуги пропускання та підвищувало загальну продуктивність. Однак 6х86МХ працював з плаваючою комою набагато гірше за конкурентів, що негативно позначалося на обробці тривимірної графіки.
Cyrix MII. Процесор МII – розвиток 6х86МХ, що працює на більш високих частотах. До літа 1998 0,25-мікронні процесори МII-300 і МII-333 вироблялися на нових виробничих потужностях компанії National Semiconductor в шт. Мен, націлених на розвиток технології 0,22-мкм, просуваючись до своєї кінцевої мети – 0,18 мкм у 1999 р.
Процесори AMD
Тривалий час Advanced Micro Devices,  подібно до Cyrix, виробляв центральні процесори 286, 386 і 486, які були засновані на розробках Intel. K5 був першим незалежно створеним х86 процесором, який AMD покладав великі надії. Однак, купівля компанією AMD заснованого в Каліфорнії конкурента навесні 1996 р., здається, створила можливість краще підготуватися до наступної атаки на Intel. К6 почав життя як Nx686, перейменований після придбання NextGen. Серію ММХ-сумісних процесорів Кб було запущено в середині 1997 р., за кілька тижнів до Cyrix 6x86MX, і одразу було схвалено критиками.
подібно до Cyrix, виробляв центральні процесори 286, 386 і 486, які були засновані на розробках Intel. K5 був першим незалежно створеним х86 процесором, який AMD покладав великі надії. Однак, купівля компанією AMD заснованого в Каліфорнії конкурента навесні 1996 р., здається, створила можливість краще підготуватися до наступної атаки на Intel. К6 почав життя як Nx686, перейменований після придбання NextGen. Серію ММХ-сумісних процесорів Кб було запущено в середині 1997 р., за кілька тижнів до Cyrix 6x86MX, і одразу було схвалено критиками.
К6 був майже на 20% менше, ніж Pentium Pro і при цьому містив на 3,3 млн. транзисторів більше (8,8 проти 5,5 млн.). ЦП К6 підтримував технологію MMX Intel, включаючи 57 нових х86 команд, розроблених у розвиток мультимедійного програмного забезпечення. Рівень продуктивності K6 дуже схожий на Pentium Pro відповідних частот з його максимальним 512 Кбайт кешем другого рівня. Спільне з чіпом Cyrix MX (але дещо меншою мірою) - робота з плаваючою комою - була областю відносної слабкості проти Pentium Pro чи Pentium II.
AMD K6-2. Процесори AMD K6-2 з 9,3 млн. транзисторів вироблялися за 0,25-мікронною технологією AMD. Процесор був упакований у 100 МГц Super7 – сумісну, 321-контактну керамічну плату (ceramic pin grid array (CPGA) package). K6-2 включає інноваційну ефективну мікроархітектуру R1SC86, великий (64 Кбайт) кеш першого рівня (двопортовий кеш даних на 32 Кбайт, кеш команд на 32 Кбайт з додатковим кешем, що передрасшифровує, на 20 Кбайт), а також покращений модуль роботи з плаваючою комою.
Ефективна продуктивність при його запуску в середині 1998 була оцінена в 300 МГц, до початку 1999 найшвидшим з доступних процесорів була версія 450 МГц. Тривимірні можливості К6-2 представляли інше важливе досягнення. Вони були втілені в AMD технології 3DNow! як новий набір з 21 команди, який доповнював стандартні команди ММХ, вже включені в архітектуру Кб, що прискорювало обробку тривимірних додатків. Анонсований на початку 2001 р. процесор К6-2 (550 МГц) мав стати найшвидшим і заключнішим процесором AMD для застарілого форм-фактора Socket 7, який згодом замінювався в перспективному секторі ринку настільних комп'ютерів процесором Duron.
AMD K6-III. У лютому 1999 р. AMD оголосила початок випуску партії 400 МГц AMD K6-III процесора, під кодовою назвою narptooth і випробувала 450 МГц версію. Ключовою особливістюцього нового процесора була інноваційна розробка – трирівневий кеш.
Традиційно процесори ПК використовували два рівні кешу:
- кеш першого рівня (L1), який зазвичай розташований на кристалі;
- кеш другого рівня (L2), який міг розташовуватися або поза ЦП, на материнській платі або слоті або безпосередньо на чіпі ЦП.
Загальне емпіричне правило при проектуванні підсистеми кешу - чим більше і швидше кеш, тим вища продуктивність (ядро центрального процесора може швидше отримати доступ до інструкцій та даних).
Визнаючи вигоди великого та швидкого кешу в задоволенні потреб додатків, що все більш вимогливі до продуктивності ПК, «Трирівневий кеш» компанії AMD вводив архітектурні нововведення кешу, розроблені для збільшення продуктивності ПК на основі платформи Super7:
- внутрішній K2-кеш (256 Кбайт), що працює на повній швидкості процесора AMD-K6-III і доповнює кеш L1 (64 Кбайт), який був стандартним для всього сімейства процесорів AMD-K6;
- багатопортовий внутрішній кеш, що дозволяє одночасне 64-бітове читання та запис як кешу L1, так і L2;
- первинна процесорна шина (100 МГц), що забезпечує з'єднання з резидентною кеш-пам'яті системній платі, що розширюється від 512 до 2048 Кбайт.
Проект багатопортового внутрішнього кешу процесора AMD-K6-III дозволив як кешу L1 (64 Кбайт), так і кешу L2 (256 Кбайт) виконувати одночасне 64-бітове читання та запис операцій за один такт процесора. На додаток до цього багатопортового проекту кеша ядро процесора AMD-K6-III було в змозі отримати доступ до кешів L1 і L2 одночасно, що збільшує загальну пропускну здатність центрального процесора.
AMD стверджувала, що з повністю налаштованим кешем 3-го рівня K6-III мав перевагу у розмірі кешу в 435% перед Pentium III і, отже, істотна перевага у продуктивності. Однак, зрештою, йому судилося прожити відносно коротке життя на арені настільних комп'ютерів, будучи відсунутим на задній план ефективнішим процесором AMD Athlon через кілька місяців.
Випуск процесора Athlonвлітку 1999 р. був найбільш вдалим ходом AMD. Це дозволило їм пишатися тим, що вони зробили  перший процесор сьомого покоління (у нього було досить багато радикальних архітектурних відмінностей від Pentium II/III та K6-III, щоб заслужити назву процесора наступного покоління), і це означало також, що вони вирвали технологічне лідерство у Intel.
перший процесор сьомого покоління (у нього було досить багато радикальних архітектурних відмінностей від Pentium II/III та K6-III, щоб заслужити назву процесора наступного покоління), і це означало також, що вони вирвали технологічне лідерство у Intel.
Давньогрецьке слово Athlon означає "трофей", або "ігри". Athlon – процесор, за допомогою якого AMD сподівалася збільшити реальну конкурентоспроможну присутність у корпоративному секторі, крім його традиційної переваги на споживчому ринку та ринку тривимірних ігор. Ядро розміщується на кристалі 102 мм2 і містить приблизно 22 млн транзисторів.
Duron.У середині 2000 р. було випущено процесор Duron, призначений для дому та офісу. Назва походить від латинського "durare" - "вічний", "тривалий". Кеш-пам'ять L1 (128 Кбайт) та L2 (64 Кбайт) розміщується на платі. Первинна системна шина працює на частоті 200 МГц. Підтримується покращена технологія 3DNow! Технологія 0,18 мкм, частоти 600, 650 та 700 МГц. Інтерфейс – 462-контактний роз'єм Socket A.
Athlon 64.Восени 2003 р. вийшли дві  моделі процесора AMD - Athlon 64 для масового ринку та Athlon 64 FX-51 для мультимедіа та професійних додатків(Архітектура К8). У системі позначень AMD Athlon 64 має еквівалентну частоту 3200+, за фізичної частоти 2 ГГц, FX-51 трохи більше - 2,2 ГГц. Важлива архітектурна новація: інтеграція системного контролера пам'яті (system memory controller hub - MCH) безпосередньо в процесор. Це означає, що системна плата (точніше, чіпсет) не повинна містити окремий чіп контролера Northbridge. Крім того, зникає необхідність у первинній системній шині (FSB) разом з усіма затримками, які вона вносить. Натомість К8 використовує HyperTransport (системна шина пропускною здатністю до 6,4 Гбайт/с) для з'єднання з контролерами Southbridge, AGP або іншими ЦП. Це дозволяє пам'яті працювати з повною частотою процесора, знижує затримки (латентність) та підвищує ефективність пам'яті. Процесор пристосований як для 32-, так і для 64-бітових програм.
моделі процесора AMD - Athlon 64 для масового ринку та Athlon 64 FX-51 для мультимедіа та професійних додатків(Архітектура К8). У системі позначень AMD Athlon 64 має еквівалентну частоту 3200+, за фізичної частоти 2 ГГц, FX-51 трохи більше - 2,2 ГГц. Важлива архітектурна новація: інтеграція системного контролера пам'яті (system memory controller hub - MCH) безпосередньо в процесор. Це означає, що системна плата (точніше, чіпсет) не повинна містити окремий чіп контролера Northbridge. Крім того, зникає необхідність у первинній системній шині (FSB) разом з усіма затримками, які вона вносить. Натомість К8 використовує HyperTransport (системна шина пропускною здатністю до 6,4 Гбайт/с) для з'єднання з контролерами Southbridge, AGP або іншими ЦП. Це дозволяє пам'яті працювати з повною частотою процесора, знижує затримки (латентність) та підвищує ефективність пам'яті. Процесор пристосований як для 32-, так і для 64-бітових програм.
У той же час, коли AMD оголосив Athlon 64, компанія Microsoft заявила про випуск бета-версії Windows XP 64-Bit Edition для 64-бітових процесорів, яка може працювати природно як на процесорах AMD Athlon 64 (ПЕОМ), і AMD Opteron (робочі станції).
Робота з прайс-листом
При виборі мікропроцесора необхідно розглядати частину характеристик, наприклад
- Процесори Intel.
- Процесори AMD та Cyrix.
- Сучасні версії процесорів Intel та AMD (на відміну від старих).
- Альтернативні фірми-виробники мікропроцесорів.
- Охарактеризувати комплектуючі із прайс-листа
- AMD ATHLON-64 X2 6000+ BOX (ADV6000) 1Мб/2000МГц Socket AM2
- AMD ATHLON-64 2800+ (ADA2800) 512К/800МГц Socket-754
- Intel Core 2 Duo E6550 2.33 ГГц/4Мб/1333МГц 775-LGA
- Intel Pentium 4 1.5 ГГц/256K/400MHz 423-PGA
Процесор виконує такі функції:
1) обчислення адрес команд і операндів;
2) вибірку та дешифрацію команд з оперативної пам'яті;
3) вибірку даних з оперативної пам'яті, мікропроцесорної пам'яті та регістрів адаптерів зовнішніх пристроїв;
4) прийом та обробку запитів та команд від зовнішніх пристроїв;
5) обробку даних та їх запис в оперативну пам'ять, регістри мікропроцесора та регістри адаптерів зовнішніх пристроїв;
6) вироблення керуючих сигналів для всіх інших вузлів та блоків комп'ютера;
7) перехід до наступної команди.
Згідно з /4/, основними параметрами мікропроцесорів є: розрядність, робоча тактова частота, розмір кеш-пам'яті, склад інструкцій, конструктив.
1) Розрядність внутрішніх регістрів- Кількість біт, які процесор здатний обробити за один прийом. Розрядність шини данихвизначає кількість розрядів, з яких одночасно можуть виконуватися операції. Розрядність шини адресивизначає обсяг пам'яті (адресний простір), з яким може працювати процесор. Адресний простір- це максимальна кількість осередків пам'яті, яка може бути безпосередньо адресована мікропроцесором.
2) Робоча тактова частота (МГц)багато в чому визначає швидкодію процесора, оскільки кожна команда виконується за певну кількість тактів. Чим коротший машинний такт, тим вища продуктивність процесора. Швидкодія комп'ютера також залежить від тактової частоти шини системної плати, з якою працює процесор.
3) Кеш-пам'ять, що встановлюється на платі мікропроцесора, має два рівні:
3.1) L 1 - Пам'ять першого рівня, що знаходиться всередині основної мікросхеми (ядра) процесора і працює завжди на повній частоті процесора (вперше з'явилася в мікропроцесорах Intel 386SLC і 486).
3.2) L 2 - Пам'ять другого рівня, кристал, що розміщується на платі мікропроцесора і пов'язаний з ядром внутрішньою шиною (вперше введена в мікропроцесорах Pentium II). Ця пам'ять може працювати на повній чи половинній частоті процесора.
4) Склад інструкцій– перелік, вид та тип команд, що автоматично виконуються мікропроцесором. Визначає безпосередньо ті процедури, які можуть виконуватися над даними та категорії даних, над якими можуть виконуватися ці процедури. Суттєва зміна складу інструкцій відбулася в мікропроцесорах Intel 80386 (цей склад прийнятий за базовий), Pentium MMX, Pentium III, Pentium 4.
5) Конструктивмає на увазі ті фізичні роз'ємні сполуки, які встановлюється мікропроцесор. Різні роз'єми мають різну конструкцію (щілинний роз'єм – Slot, роз'єм-гніздо – Soket), різну кількість контактів.
Процесори класифікуються за різними ознаками. Відповідно до /4, 13/, можна виділити такі основні ознаки:
1) За призначеннюмікропроцесори поділяються на універсальніі спеціалізовані. Перші призначені на вирішення широкого кола завдань, у системі команд закладено алгоритмічна універсальність. Таким чином, продуктивність процесора слабо залежить від специфіки розв'язуваних завдань. Спеціалізовані процесори призначені для вирішення певного кола задач або навіть одного завдання, що мають обмежений набір команд. Серед них виділяються процесори для обробки даних, математичні процесориі мікроконтролери.
2) За кількості виконуваних програмпроцесори поділяються на однопрограмні(перехід до виконання наступної програми відбувається лише після завершення поточної програми) та мультипрограмні(одночасно виконуються кілька програм).
3) За структурномуознакою виділяють мікропроцесори з фіксованою розрядністю(мають строго певну розрядність) та мікропроцесори з нарощуваною розрядністю(дозволяють секціями збільшувати кількість розрядів).
4) За числу БІС (СВІС) у мікропроцесорному комплектіможна виділити однокристальні, багатокристальніі багатокристалічні секційніпроцесори. У першому випадку всі апаратні частини процесора реалізовані у вигляді однієї ВІС (НВІС); можливості таких процесорів обмежені ресурсами кристала та корпусу. Багатокристалічні процесори виходять в результаті розбиття логічної структури процесора на функціонально закінчені частини, кожна з яких реалізована у вигляді ВІС або НВІС. У разі функціонально закінчені частини логічної структури процесора розбиваються на секції, які реалізовані як БИС.
5) За розрядності оброблюваної інформаціїмікропроцесори можуть бути 4, 8, 12, 16, 24, 32 та 64-розрядними. Насправді найбільшого поширення мають 32-разрядные процесори; дедалі більше застосування знаходять 64-розрядні процесори.
6) На вигляд технології виготовлення БІС (НВІС)мікропроцесори поділяються на дві групи: процесори, побудовані на БІС, виготовлених за уніполярної технології, та процесори, побудовані на БІС, виготовлених по біполярної технології. Представники першої групи: p-канальні (p-МОП), n-канальні (n-МОП), компліментарні (КМОП)ВІС. (МОП – метал-окис-провідник). До другої групи належать БІС на базі транзисторно-транзисторної логіки (ТТЛ), емітерно-пов'язаної логіки (ЕСЛ)і інтегральної інжекторної логіки (І 2 Л). Вигляд технології виготовлення БІС багато в чому визначає ступінь інтеграції мікросхем, швидкодію, енергоспоживання, перешкодозахисність та вартість процесорів. За комплексом цих ознак можна віддати перевагу мікропроцесорам, виконаним за n-МОП та КМОП-технологіям, що забезпечують високу щільність компонування, високу швидкодію та відносно малу вартість. ЕСЛ забезпечує найвищу швидкодію процесорів, але низьку щільність компонування та високе енергоспоживання. Технологія І 2 Л дає усереднені властивості мікропроцесорів.
7) За характеру системи командвиділяють процесори з повним набором інструкційабо CISC-процесори(Complex Instruction Set Command), процесори із скороченим набором інструкційабо RISC-процесори(Reduced Insrruction Set Command), процесори з надвеликим командним словомабо VLIW-процесори(Very Long Instruction Word). CISC-процесори мають великий набір різноформатних команд, що дозволяє застосовувати ефективні алгоритми вирішення завдань, але в той же час ускладнює схему процесора і в загальному випадку не забезпечує максимальної швидкодії. Архітектура CISC властива класичним процесорам. RISC-процесори містять набір простих інструкцій, що найчастіше зустрічаються в програмах. При необхідності виконання складніших команд у мікропроцесорі проводиться їх автоматичне складання з простих команд. всі прості командимають однаковий розмір і на їх виконання витрачається один машинний такт (на виконання найкоротшої команди із системи CISC зазвичай витрачається чотири такти). Сучасні 64-розрядні RISC-процесори випускаються багатьма фірмами: Apple (PowerPC), IBM (PPC) тощо. У VLIW-процесорах одна інструкція містить кілька операцій, які мають виконуватися паралельно. Завдання розподілу між кількома обчислювальними пристроями процесора вирішується під час компіляції програми. Такий підхід дозволили зменшити габарити процесорів та споживання енергії. Прикладами VLIW-процесорів є Itanium фірми Intel, McKinley фірми Hewlett-Packard та інші.
8) За числу та способу використання внутрішніх регістріврозрізняють акумуляторні, багатоакумуляторніі стіковіпроцесори. Акумуляторні процесори- Це процесори з одним регістром результату. Їхньою відмінною характеристикою є відносна простота апаратної реалізації, а також спрощений формат команд (розглянуті в наступній лекції). У командах адреса операнда в акумуляторі не вказується, а адресується лише другий операнд. Недоліками таких процесорів є необхідність попереднього завантаження операнда в акумулятор перед виконанням операції та неможливість безпосереднього запису результату виконання команди довільну комірку пам'яті або регістр. У багатоакумуляторнихРегістри, якими є більшість сучасних процесорів, функції регістрів результату може виконувати будь-який регістр загального призначення або комірка пам'яті. У командах обидва операнди задаються явно, а результат операції найчастіше поміщається на місце одного з операндів. У стековихУ процесорах зазвичай використовується великий апаратний стек і додатковий зовнішній стек у пам'яті (при нестачі апаратного). Завдяки спеціальному розміщенню операндів у стеку обробку інформації можна виконувати безадресними командами, що дозволяє підвищити продуктивність процесора та заощаджувати пам'ять. Такі команди витягують із стека один або два операнди, виконують над ними відповідну арифметичну або логічну операцію і заносять результат у вершину стека. Недоліком є необхідність попередньої підготовки даних, які використовують адресні команди.
З історією розвитку процесорів та його порівняльною характеристикою докладніше можна ознайомитися у /4, 13/. Далі розглянемо фізичну та функціональну структуру процесора.
Фізична та функціональна організація ЦП (на прикладі ЦП Intel 8086). ШІ.
Фізична структура процесора є досить складною. Відповідно до /4/, ядро процесора містить головний керуючий та виконуючі модулі – блоки виконання операцій над цілими даними. До локальних управляючих схем відносяться: блок з плаваючою комою, модуль передбачення розгалужень, регістри мікропроцесорної пам'яті, регістри кеш-пам'яті 1-го рівня, шинний інтерфейс та багато іншого.
Примітка: Під логічним ядром розуміється схема, якою зроблено процесор. Фізично ядро є кристалом, у якому з допомогою логічних елементів реалізована принципова схема процесора.
У загальному випадку функціональну структуру процесора можна подати у вигляді композиції, згідно з одним джерелом /4, 5/, двох частин: операційного пристрою (ОУ) та шинного інтерфейсу (ШИ), згідно з іншими /2/,- трьох блоків: операційного блоку (ПРО), керуючого блоку (УБ) та інтерфейсного блоку (ІБ). Наявні незначні розбіжності у кількості та назві блоків аж ніяк не порушують число та принципи функціонування компонентів процесора. Тому розглянемо перший (наочніший) варіант із джерела /4/.
Спрощена типова структура процесора представлена малюнку 4.1.
ОУмістить пристрій управління (УУ), арифметико-логічний пристрій (АЛУ), регістр прапорів, регістри загального призначення (РН), регістри-покажчики, індексні регістри. ШИмістить адресні регістри, блок регістрів (буфер) команд, вузол формування адреси, схеми керування шиною та портами. Обидві частини мікропроцесора працюють паралельно, причому ШІ працює швидше за ОУ. Розглянемо ці блоки процесора докладніше.
ШИпризначений для зв'язку та узгодження мікропроцесора із системною шиною комп'ютера, а також для прийому, попереднього аналізу команд виконуваної програми та формування повних адрес операндів та команд.
Сегментні(Адресні) регістри спільно з вузлом формування адресиреалізують сегментацію пам'яті. Команди та дані зберігаються в комірках, та їх місцезнаходження у пам'яті визначається адресами відповідних осередків. Оскільки команди та дані на рівні кодів не відрізняються один від одного, то для відмінності команд і даних використовується їх розміщення у різних галузях пам'яті – сегментах. Сегмент- Це прямокутна область пам'яті, що характеризується початковою адресою та довжиною. Початкова адреса (адреса початку сегмента)– це номер (адреса) осередку пам'яті, з якого починається сегмент. Довжина сегмента – це кількість вхідних до нього осередків пам'яті. Сегменти можуть мати різну довжину. Усі осередки, розташовані всередині сегмента, перенумеровуються, починаючи з нуля. Адресація осередків усередині сегмента ведеться щодо початку сегмента; адреса осередку в сегменті називається зміщеннямабо ефективною адресою -EA(щодо початкової адреси сегмента). Поточний сегмент можна вказати за допомогою завантаження відповідного сегментного регістру:
1) CS (Code Segment) - Визначає початок поточного сегмента коду, в якому розташовуються команди програми. Вибірка команди проводиться з використанням як ефективна адреса вмісту регістру IP (Instruction Pointer) , а адресою сегмента – вмісту CS. Саме регістр IP зберігає усунення адреси поточної команди програми.
2) DS (Data Segment) - Визначає початок поточного сегмента даних. Посилання на дані (за деяким винятком) здійснюються щодо вмісту цього регістру.
3) SS (Stack Segment) - Визначає початок поточного сегмента стека. Як правило, всі адреси даних, пов'язаних зі стеком, задаються щодо цього регістру.
4) ES (Extended Segment) - Визначає початок додаткового поточного сегмента, який зазвичай розглядається як допоміжний сегмент даних (при міжсегментних пересиланнях).
Вузол формування адресиі регістр командфункціонально входять до складу УУ та були розглянуті вище.
При адресації пристроїв введення-виведення (УВВ) сегментні регістри не використовуються. Взаємодія із нею процесор здійснює через спеціальний адресний простір – порти. Кожен порт має номер, що відповідає адресі підключеного до нього пристрою. Порту пристрою відповідає апаратура пари та два регістри – для обміну даними та керуючої інформацією. Схема управління шиною та портамивиконує такі функції:
1) формування адреси порту та керуючої інформації для нього;
2) прийом керуючої інформації від порту, інформації про готовність порту та його стан;
3) організація наскрізного каналу в системному інтерфейсі передачі між портом УВВ і процесором.
Схема керування шиною та портами використовує для зв'язку з портами системну шину: шину адреси, шину даних та шину інструкцій.
Фізична та функціональна організація ЦП (на прикладі ЦП Intel 8086). ОУ.
У цілому нині ОУ виконує операції, зумовлені командами, і формує ефективні адреси.
УУвиробляє управляючі сигнали, які у всі блоки обчислювальної машини. У складі УУ можна виділити такі функціональні блоки:
1) регістр команд- Регістр, що запам'ятовує, в якому зберігається код команди: код операції та адреси операндів (розташований в інтерфейсній частині процесора);
2) дешифратор операцій- логічний блок, який відповідно до коду операції, що надходить з регістру команд, вибирає один з безлічі наявних у нього виходів;
3) постійний пристрій (ПЗУ) мікропрограмзберігає керуючі імпульси до виконання в блоках обчислювальної машини процедур обробки інформації; імпульс по обраному дешифратором операцій дроту зчитує з ПЗП мікропрограм необхідну послідовність сигналів, що управляють;
4) вузол формування адреси(Розташовується в ШІ) – пристрій для обчислення повної адреси осередку пам'яті (реєстру) по реквізитах, що надходять з мікропроцесорної пам'яті або регістру команд;
5) кодові шини даних, адреси та інструкцій- Частина внутрішньої інтерфейсної шини процесора.
Отже, УУ формує керуючі сигнали до виконання процесором своїх функцій, розглянутих вище.
Рисунок 4.1 – Спрощена типова структура процесора
АЛУпризначений для виконання арифметичних та логічних операцій перетворення інформації. Функціонально у найпростішому варіанті АЛУ складається з наступних компонентів:
1) суматорвиконує процедуру складання двійкових кодів, має розрядність подвійного машинного слова (32 біти);
2) регістри- Швидкодіючі осередки пам'яті різної довжини: регістр 1 має розрядність 32 біти, регістр 2 - 16 біт; при додаванні в регістр 1 міститься перший доданок, а потім результат, в регістр 2 - другий доданок;
3) схема управлінняприймає за кодовими шинами інструкцій керуючі сигнали від УУ і перетворює на сигнали для керування роботою регістрів та суматора.
АЛУ виконує арифметичні операції лише над двійковими числамиз фіксованою точкою. Для обробки чисел із плаваючою точкою залучається математичний співпроцесор чи спеціально складені програми.
Докладніші відомості про пристрій та функціонування УУ та АЛП можна знайти в /3 - 5/.
Реєстри ОУ- Частина мікропроцесорної пам'яті. Розглянемо регістри на прикладі базового процесора Intel 8086, який містить всього 14 двобайтових регістра. У сучасних процесорах їх набагато більше та більшої розрядності. Однак як базова модель, зокрема для мови Асемблера, використовується 14-реєстрова пам'ять процесора.
До складу ОУ входять такі регістри:
1) регістри загального призначення (РН)або універсальні: AX - (AH, AL), BX - (BH, BL), CX - (CH, CL), DX - (DH, DL) можуть використовуватися для тимчасового зберігання будь-яких даних, при цьому можна працювати з кожним регістром цілком, а можна окремо, з кожною його половиною; але кожен із РОН може використовуватися і як спеціальний при виконанні деяких конкретних команд;
2) регістри зсувів: SP, BP, SI, DI є неподільними та призначені для зберігання відносних адрес осередків пам'яті всередині сегментів (зміщень щодо початку сегментів);
2.1) SP (Stack Pointer) - Зміщення вершини стека;
2.2) BP (Base Pointer) - Зміщення початкової адреси поля пам'яті, безпосередньо відведеного під стек;
2.3) SI (Source Index) , DI (Destination Index) призначені для зберігання адрес індексу джерела та приймача даних при операціях над рядками та їм подібних.
Слово стану процесора (PSW – Processor State Word) або регістр прапори– має розмір 2 байти та містить однорозрядні ознаки або прапори. Всього в регістрі 9 прапорів: 6 з них умовніабо статусні, відображають результати операцій, виконаних ОУ, решта 3- керуючі, Визначають режим виконання програми.
1) Статусні прапори.
1.1) CF (Carry Flag) - Прапор перенесення. Встановлюється в 1, якщо під час виконання арифметичних та деяких операцій зсуву виникає «перенесення» зі старшого розряду.
1.2) PF (Parity Flag)- Прапор парності. Перевіряє молодші 8 біт результатів над даними. Чітне число одиниць призводить до встановлення цього прапора 1, непарне – 0.
1.3) AF (Auxiliary Carry Flag) - Прапор логічного перенесення в двійково-десятковій арифметиці. Встановлюється в 1, якщо арифметична операція призводить до перенесення або позики четвертого праворуч біта однобайтового операнда. Використовується при арифметичних операціях над двоично-десятковими кодами та кодами ASCII.
1.4) ZF (Zero Flag) - Прапор нуля. Встановлюється в 1, якщо результат операції дорівнює 0, інакше ZF обнулюється.
1.5) SF (Sign Flag)- Прапор знак. Встановлюється 1, якщо результат арифметичної операції є негативним, 0, якщо результат позитивний.
1.6) OF (Overflow Flag) - Прапор переповнення. Встановлюється в одиницю під час арифметичного переповнення, коли результат виходить за межі розрядної сітки.
2) Управляючі прапори.
2.1) TF (Trap Flag) - Прапор трасування. Одиничний стан цього прапора переводить процесор у режим покрокового виконання програми.
2.2) IF (Interrupt Flag)- Прапор переривань. При нульовому стані цього прапора переривання заборонені, при одиничному – дозволені (про механізм переривань йтиметься у наступній лекції).
2.3) DF (Direction Flag) - Прапор напряму. Використовується у рядкових операціях для завдання спрямування обробки даних; при одиничному стані рядка обробляються «праворуч наліво», при нульовому – «зліва направо».
Розташування прапорів у регістрі PSW показано малюнку 4.2. Вільні біти призначені для використання в майбутньому.
Рисунок 4.2 – Схема розташування прапорів у регістрі PSW
Архітектурні засади організації RISC-процесорів.
Як зазначається у /2, 14, 15/, список команд сучасного мікропроцесора може містити досить велику кількість команд. Однак не всі вони використовуються однаково часто та регулярно. Це властивість системи команд стало причиною розвитку процесорів з RISC-архитектурой. Основна ідея полягала в скороченні списку використовуваних команд і, внаслідок цього, спрощення керуючого блоку процесора і для організації більш швидкого виконання команд, що залишилися, за рахунок звільнених при цьому ресурсів кристала.
Перші процесори із скороченим набором команд були реалізовані на початку 80-х років 20 століття.
1) У 1980 році в Каліфорнійському університеті міста Берклі під керівництвом професорів Давида Паттерсона (David Patterson) та Карло Секуїна (Carlo Sequin) був розроблений процесор, який отримав назву RISC. Було розроблено моделі RISC-I, RISC-II, SOLAR.
2) У 1981 році в університеті міста Стенфорда під керівництвом Джона Хеннесі (Dohn Hennesy) був спроектований процесор, який отримав назву MIPS (Microprocessor Without Interlocked Pipeline Stages - мікропроцесор без блокування конвеєра). Докладніше про суть конвеєризації буде розглянуто у наступному питанні лекції.
Пізніше обидві моделі із скороченим набором команд стали називати RISC-процесорами. Відмінною особливістю цих процесорів є велика кількість РОН (близько 256).
Коротко охарактеризуємо основні засади RISC-архітектури /2, 15/.
1) Однакова довжина команд. Це полегшує їхню вибірку з основної пам'яті. Всі команди зчитуються за один такт, що дозволяє обробляти потік командних інструкцій за принципом конвеєру, тобто виконується синхронізація апаратних частин процесора з урахуванням послідовної передачі управління від одного апаратного блоку до іншого. У сучасних RISC-процесорах довжина команди становить 32 біти.
2) Скорочений набір дій над операндами, розміщеними у пам'яті. Прості способи адресації пам'яті забезпечують швидкий доступ до операндів пам'яті. Обробка даних, реалізована під час виконання команд RISC, будь-коли поєднується з операціями читання (запису) пам'яті (на відміну багатьох команд CISC). Обмін операндами між пам'яттю та регістрами виконується спеціальними командами завантаження (LOAD) та запам'ятовування (STORE). Велика кількість регістрів блоку РОН дозволяє зменшити кількість звернень до пам'яті.
3) Виконує всі обчислювальні операції над даними, розміщеними тільки в РОН.Оскільки регістрів багато, всі скалярні змінні і навіть невеликі масиви змінних найчастіше розміщуються в регістрах, що дозволяє прискорити обробку даних. Використання простих команд спрощує реалізацію їхньої конвеєрної обробки. У середньому, команди RISC виконуються за один такт.
4) Відносно прості схеми управління. Зменшення списку команд, використання команд, що реалізують лише прості операції, виняток у командах обробки даних звернень до пам'яті дозволили зменшити витрату ресурсів кристала управління. Завдяки цьому велика площа кристала виділяється для розміщення пристроїв, що дозволяють збільшити загальну продуктивність процесора: додаткових конвеєрів, збільшеної кеш-пам'яті 1-го рівня, більшого числа РОН.
Важливо, що з однакової технології виробництва RISC-процессоры мають вищі частоти роботи проти CISC-процесорами, що є важливою перевагою RISC-процессоров.
Згідно /15/, в архітектурі RISC-процесорів можна виділити наступні апаратні блоки, що утворюють щаблі конвеєра:
1) Блок завантаження інструкційвключає наступні складові: блок вибірки інструкцій з пам'яті, регістр інструкцій, куди поміщається команда після вибірки і блок декодування інструкцій. Цей ступінь називається ступенем вибірки інструкцій.
2) РОН спільно з блоками управління регістрамиутворюють другий ступінь конвеєра, який відповідає за читання операндів команд. Операнди можуть зберігатися у самій команді чи одному з РОН. Цей ступінь називається ступенем вибірки операндів.
3) АЛУ і, якщо в даній архітектурі реалізовано акумулятор, разом із логікою управління, Яка виходячи з вмісту регістру інструкцій визначає тип виконуваної мікрооперації. При виконанні операцій умовного та безумовного переходів джерелом даних може бути також лічильник команд. Даний ступінь називається виконавчим ступенем конвеєра.
4) Набір з РОН та логіки записуутворюють ступінь збереження даних. Тут результати виконання команд записуються в РОН чи основну пам'ять.
До RISC-процесорів зараховують мікропроцесори MIPS R4000, R8000, R100000 фірми MIPS Technologies Inc., UltraSPARC I, UltraSPARC II, UltraSPARC III фірми Sun, PowerPC фірми IBM-Motorola, Alpha AXP фірми DEC, PA-RISC фірми Hewlett Packard .
Незважаючи на очевидні переваги, RISC-процесори «в чистому вигляді» не набули широкого поширення на ринку персональних комп'ютерів, більшість з них використовується як центральні процесори робочих станцій. Однак більшість сучасних CISC-процесорів, наприклад Pentium, використовують досягнення RISC-архітектур, зокрема, RISC-ядра для виконання обчислювальних операцій.
Моделі RISC-процесорів активно розвиваються та вдосконалюються. В даний час на їх основі реалізуються комерційно важливі продукти: SPARC- та MIPS-системи.
Більш повні відомості про RISC-процесори, особливості їх архітектури та функціонування можна знайти в /2/, спеціальній літературі та відкритих джерелах Інтернету.
Архітектурні засоби підвищення продуктивності процесорів. Конвеєрна обробка інформації.
Продуктивність є однією з найважливіших характеристик процесора. Відповідно до /2/, у випадку вона визначається кількістю обчислювальної роботи, виконуваної в одиницю часу. До найважливіших факторів, що впливають на продуктивність, належать тактова частота, кількість команд програми, середній час виконання окремої команди. Для спрощеної оцінки продуктивності процесора часто використовують показник, що вказує на кількість команд, що виконуються за секунду. Він визначається як окреме від поділу тактової частоти на середній час виконання процесором окремої команди і вимірюється в MIPS (Meg Insruction Per Second) для цілісних завдань і MFLOPS (Meg Floating Point Operations Per Second) для обчислень з точкою, що плаває. При цьому оцінки показника, що визначає кількість команд, що виконуються за секунду, проводять для операцій з регістровими операндами, не прив'язуючи швидкодії основної пам'яті. Однак це показник не враховує особливості архітектури конкретних процесорів. Тому для порівняльних характеристик різних процесорів використовуються відносні оцінки продуктивності, щоб одержати яких використовуються спеціальні тестові програми.
Відповідно до /2/, підвищення продуктивності процесорів у більшості випадків досягається за рахунок застосування спеціальних технологічних та архітектурних рішень. Технологічні підходи (удосконалення технологій виробництва ІВ, збільшення ступеня інтеграції) було розглянуто раніше, у другому розділі. Тому докладніше зупинимося на архітектурних засобах підвищення продуктивності процесорів. Удосконалення архітектури процесорів, що забезпечує підвищення його продуктивності, нині пов'язано, передусім, з недостатнім розвитком засобів паралельної обробки даних. Тут можна виділити такі напрямки:
1) Збільшення «природного» паралелізму – підвищення розрядності обробки та передачі (розрядність процесорів підвищилася з 4 до 32 і 64 розрядів).
2) Конвеєрна (багатофазна) обробка даних - обчислювальний процес ділиться на кілька фаз, для кожної з яких використовуються свої засоби та буфер для зберігання результату (ступінь конвеєра).
3) Багатоелементна обробка даних – паралельна обробка даних у кількох операційних блоках (ОУ) процесора.
Способи паралельної обробки можуть поєднуватися. Наприклад, в одному процесорі можна організувати декілька операційних блоків, у кожному з яких використовувати конвеєризацію.
Розглянемо детальніше два останні напрями.
При багатофазнийобробці, як показано на малюнку 4.3, процес обробки даних розбивається на кілька стадій (фаз), що виконуються послідовно.
Малюнок 4.3 – Багатофазна обробка даних
Між фазами є буфери зберігання проміжних результатів. Після виконання першої фази результат запам'ятовується у буфері і починається обробка другої фази. Засоби виконання першої фази звільняються, і них надходить наступна порція даних. Якщо тривалість фаз обробки однакова і становить T/ n, то при такому способі продуктивність системи збільшиться в nразів. Цей спосіб відповідає конвеєрній обробці.
Розглянемо організацію конвеєра лише на рівні виконання машинної команди /2/. Кожен блок у конвеєрному ланцюжку здійснює лише один етап виконання команди. Повне опрацювання команди займає кілька тактів.
Типові етапи виконання команди: 1) вибірка команди IF (Instruction Fetch); 2) дешифрація команди ID (Instruction Decode); 3) читання операндів RD (Read Memory); 4) виконання заданої в команді операції EX (Execute); 5) запис результату WB (Write Back). У ході виконання команда просувається конвеєром, звільняючи черговий ступінь для наступної команди. Вміст буферів, які використовуються для зберігання інформації, що передається сходами конвеєра, оновлюється в кожному такті після завершення етапу виконання чергової команди. Проміжні буфери забезпечують паралельну незалежну роботу блоків конвеєрного ланцюжка: у той час, коли наступний блок починає виконувати етап чергової команди, попередній блок може розпочинати обробку наступної команди, що демонструє малюнок 4.4.
|
Такти роботи процесора |
||||||||||
|
Команда i | ||||||||||
|
Команда i+1 | ||||||||||
|
Команда i+2 | ||||||||||
|
Команда i+3 | ||||||||||
|
Команда i+4 | ||||||||||
|
Команда i+5 | ||||||||||
Малюнок 4.4 – Конвеєрна обробка команд
Слід зазначити, що конвеєрна обробка команд не зменшує час виконання окремої команди, яке у конвеєрному процесорі залишається таким самим, як і у звичайному неконвеєрному. Однак завдяки тому, що при конвеєрній обробці більша частина обчислювального процесу в режимі одночасного виконання команд, швидкість видачі результатів команд, що послідовно виконуються, збільшується пропорційно числу ступенів конвеєра. Тривалість виконання окремих етапів виконання команди у випадку залежить від типу команди і місця розміщення операндов. Конвеєрна обробка команд найефективніша у разі, якщо тривалість всіх фаз виконання команди приблизно однакова. На жаль, забезпечити безперервну роботу конвеєра не завжди вдається через різні конфлікти: за ресурсами, за даними, з управління. Докладніше про конфлікти – в /2, 7/.
Процесор, у якому процес виконання команди розбивається на 5-6 ступенів, називається звичайним конвеєрним процесором. Якщо збільшити кількість ступенів конвеєра, то кожен окремий ступінь виконуватиме меншу роботу, а отже, міститиме менше апаратної логіки. Завдяки більш коротким затримкам поширення сигналів у кожному окремо взятому ступені конвеєра досягається підвищення частоти роботи та відповідне підвищення продуктивності процесора. Процесор, що має конвеєр значно глибше 5-6 ступенів, називається суперконвеєрним. Наприклад, Pentium II містить 12 ступенів, UltraSPARC III – 14 ступенів, Pentium 4 – 20 ступенів.
багатоелементна
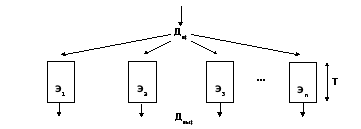
Tі в системі використовується n T/ n
A = B + C; D = E + F.
суперскалярнимскалярноїскалярними
Архітектурні засоби підвищення продуктивності процесорів. Багатоелементне оброблення інформації.
Як показано на малюнку 4.5 /2/, багатоелементнаобробка складає кількох паралельно працюючих ОУ. Кожен елемент виконує свою роботу, здійснюючи обробку порції даних від початку остаточно.
Малюнок 4.5 – Багатоелементна паралельна обробка даних
Якщо час виконання роботи на окремому елементі складає Tі в системі використовується nелементів, то за певної ідеалізації очікується, що середній час виконання такої роботи становитиме T/ n(Реально - менше). У сучасних процесорах такий спосіб обробки пов'язаний із поняттям суперскалярної архітектури.
Найпростішим прикладом обчислювального паралелізму є виконання двох команд, операнди яких не пов'язані між собою:
A = B + C; D = E + F.
Тому обидві команди можна виконувати одночасно. Для виконання незв'язаних операцій до складу процесора включають набір арифметичних пристроїв, кожен з яких має конвеєрну організацію.
Процесор, що містить кілька ОУ, що забезпечує одночасне виконання більше однієї скалярної команди, називається суперскалярнимпроцесором. Команда називається скалярноїякщо її вхідні операнди і результат є числами (скалярами). Традиційні процесори з одним ОУ називаються скалярними. У суперскалярному процесорі обробка команд розпаралелена не тільки в часі (конвеєр), а й у просторі (кілька конвеєрів). Продуктивність такого процесора оцінюється темпом сходу виконаних команд із усіх його конвеєрів.
В даний час використовуються два способи суперскалярної обробки. Перший спосіб базується на чисто апаратному механізмі вибірки незв'язаних команд програми з пам'яті (кеш-пам'яті, буфера передвиборки) та паралельному запуску їх на виконання. Відповідальність за ефективність завантаження паралельно функціонуючих конвеєрів покладається на апаратні засоби процесора, що є основною перевагою цього способу суперскалярної обробки. У цьому випадку процес трансляції програм для суперскалярного процесора нічим не відрізняється від трансляції програм для традиційного скалярного процесора. Відповідно до цього способу, порівняно легко реалізуються суперскалярні мікропроцесори різних сімейств програмно сумісні між собою. При цьому не виникає проблем із використанням раніше створеного програмного забезпечення. Усі процесори сімейства Pentium реалізовані цим способом.
У процесорах, що реалізують другий спосіб суперскалярної обробки, планування паралельного виконання кількох команд покладається на комплелятор, що розпаралелює. Спочатку він аналізує вихідну програму для виявлення команд, які можуть виконуватися одночасно. Потім компілятор групує такі команди пакети команд – довгі командні слова (VLIW), причому, число простих команд у команді VLIW приймається рівним числу виконавчих блоків процесора. Оскільки всю роботу з підготовки до виконання команд VLIW виконує компілятор, конфліктні ситуації при їх виконанні виключаються. Такий спосіб суперскалярної обробки реалізується у VLIW-процесорах, що мають статичну сперскалярну архітектуру. На жаль, для таких процесорів потрібне спеціальне програмне забезпечення. З іншого боку, програми, скомпільовані одного покоління мікропроцесорів, можуть виконуватися неефективно без перекомпіляції на процесорах наступного покоління. Це вимагає від розробників програмного забезпечення розробки модифікованих версій виконуваних файлівпродукт для різних поколінь процесорів. Ідеї VLIW запропоновані російськими інженерами та вченими на чолі з професором Б.А. Бабаяном розробки вітчизняної супер-ЕОМ «Эльбрус-3» (1990). В даний час VLIW-технологія реалізована в процесорі Ельбрус Е2К вітчизняної компанії «Ельбрус Інтернешнл», процесорах Crusoe фірми Transmeta, а також сімейства сигнальних процесорів (для цифрової обробки сигналів) TMS320C60xx фірми Texas Instruments.
Класифікація та структура команд процесора.
За функціональною ознакою всі команди процесора можна поділити на такі групи:
1) команди пересилання даних та введення-виведення;
2) команди арифметичних та порозрядних логічних операцій;
3) команди передачі керування.
Команди пересилання данихзабезпечують обмін інформацією між регістрами мікропроцесора, а також зовнішні обміни даними при передачі в процесор з пам'яті або пристрою введення та процесора в пам'ять або пристрій виведення. У цих командах зазвичай вказується напрямок передачі, джерело та (або) приймач даних. Наприклад, у мові Асемблера, до команд цієї групи можна віднести команду пересилання MOVкоманду завантаження LOAD, команди запису в порт та читання з порту УВВ, INі OUTвідповідно т.п. Також сюди часто включають команди приміщення даних у стек PUSHта вилучення даних зі стека POP.
До числа команд арифметичних та порозрядних логічних операційу більшості випадків входять команди найпростіших арифметичних операцій, наприклад, ADD (скласти), SUB (відняти), та логічних операцій, наприклад, AND («І»), OR («АБО») і т.п. До арифметичних команд також відносять команди арифметичних та логічних зрушень, а до команд логічних операцій – команди порівняння COMPARE (неруйнівного віднімання). До команд цієї групи можуть входити команди складних арифметичних операцій: множення, розподіл (є не у всіх процесорах), команди обробки даних з плаваючою точкою, команди мультимедійної обробки.
Команди передачі управліннявикористовуються для зміни послідовності виконання команд за наявності програмних розгалужень: команд умовних та безумовного (JMP) переходів, звернення до підпрограм (CALL) та виходу з них (RETURN). Команди умовних переходів реалізують передачі управління залежно від значення прапорів у регістрі PSW. З їх допомогою процесор має одну з можливих гілок продовження програми. Зазвичай у системі команд є кілька команд умовних переходів.
У сучасних процесорах системи команд поряд із традиційними командами, перерахованими вище, містять у своєму складі групи команд, що розширюють функціональні можливості мікропроцесора з обробки інформації, управління його роботою, а також забезпечують реалізацію багатозадачного захищеного режиму роботи.
До систем команд конкретних процесорів можуть входити команди, які не вписуються в запропоновану класифікацію. Подібні команди не відображають загальних принципів побудови програм та розглядаються як додаткові.
Виконання команди (машинної операції) розділено більш дрібні етапи - мікрооперації (мікрокоманди), під час яких виконуються певні елементарні дії. Конкретний склад мікрооперацій визначається системою команд та логічною структурою обчислювальної машини. Послідовність мікрокоманд, що реалізують цю операцію (команду), утворює мікропрограму операції. Інтервал часу, протягом якого виконується одна або одночасно кілька мікрооперацій, називається машинним тактом. Межі тактів задаються синхросигналами, які виробляються генератором синхросигналів.
У випадку команда мікропроцесора містить дві частини: операційну і адресну. Відповідно до /1/, угода про розподіл розрядів між цими частинами команди та спосіб кодування інформації визначає структуру (формат) команди. В операційній частині команди міститься код операції, який забезпечує кодування операцій (де n- Число двійкових розрядів, відведених під операційну частину команди) і визначальний, які при цьому будуть задіяні пристрої в процесорі або поза ним. У k-Розрядної адресної частини команди міститься інформація про адреси операндів, що беруть участь у виконанні операції. У загальному випадку адресна частина команди повинна містити чотири адресні поля A1 , A2 , A3 , A4 . Вони призначені для завдання адрес операнди (A1, A2), адреси результату (A3) та адреси наступної команди (A4). Як адреси A1, ..., A3 можуть використовуватися адреси осередків оперативної пам'яті та адреси регістрів мікропроцесорної пам'яті, в якості адреси A4 тільки адреси осередків оперативної пам'яті. При використанні повного набору адрес формат команди виявляється громіздким. Було зазначено, що для всіх операцій необхідний повний набір адрес A1-A4. Залежно від вказуваного числа адрес команди поділяються на 0-адресні (безадресні), 1-адресні, 2-адресні, 3-адресніі 4-адресні.
Практично у всіх мікропроцесорах виключено адресу A4. Це зумовлено тим, що більшість команд відносяться до лінійних ділянок алгоритмів, і такі команди можуть бути розміщені в осередках пам'яті з адресами, що послідовно зростають. У цьому випадку для отримання адреси наступної команди до початкової адреси сегмента коду достатньо додати її усунення в сегменті коду, що зручно реалізувати за допомогою покажчика команд. Такий спосіб адресації команд називається природним, а процесори, що його реалізують, називаються процесорами з природним способом адресації команд. При порушенні природного порядку проходження команд (розгалуження, цикли) використовуються спеціальні команди передачі управління, в яких міститься адреса переходу, але не використовуються адреси операндів. Процесори, в адресному полі команд яких використовується адреса A4, називаються процесорами із примусовим способом адресації команд.
Використання адреси результату A3 у багатьох випадках також виявляється надмірним. Це обґрунтовується тим, що результат арифметичних та логічних операцій над двома операндами зазвичай може бути поміщений на місце одного з операндів, який надалі, швидше за все, не використовуватиметься. При цьому в 2-адресних командах в адресне поле необхідно вводити додаткові розряди, які показують, хто є джерелом, а хто – приймачем інформації. У процесорах з акумуляторною архітектурою кількість адрес в адресній частині команди зменшено до одного. Вони один з операндів, розміщених в акумуляторі, неявно задається кодом команди, і результат поміщається в акумулятор.
У безадресних командах здійснюється неявне завдання операнда. До таких команд відносяться команди управління процесором (наприклад, пуску, зупинки і т.д.), команди для роботи зі стеком (операнд, адресований покажчиком SP, явно задається кодом команди). Безадресні команди мають максимально скорочений формат, але не можуть самостійно утворити функціонально повну систему команд і застосовуються тільки разом з адресними.
Формат команд впливає тимчасово вирішення завдань, витрати пам'яті, складність процесора і від класу розв'язуваних завдань. Зокрема, для науково-технічних розрахунків, у яких великий обсяг займають багатокрокові обчислення, ефективнішими виявляються 1-адресні команди, а за використанні стекового процесора – і безадресні команди. Для завдань управління, де більшу частку становлять пересилання та логічні операції ефективними є 2-адресні команди. Виходячи зі сказаного вище, слід зазначити, що в сучасних процесорах зазвичай використовуються безадресні, 1-адресні та 2-адресні команди. 3-адресні команди використовуються дуже рідко, а 4-адресні не використовуються зовсім.
Внаслідок різноманітності форматів команд і даних (числа, символи, структури тощо), а також їх розташування сформувалися різні способи адресації команд і операндів, які розглянемо нижче.
Методи адресації даних. Безпосередній, прямий, непрямий, регістровий відносний режим адресації.
Способи адресації даних визначають механізми обчислення ефективних адрес операндів у пам'яті та доступу до операндів. Виділяють такі способи (режими) адресації /2, 6/:
1)Безпосередній– дозволяє задавати фіксовані значення операнда безпосередньо в адресній частині команди, тобто це є частиною команди (Малюнок 5.1). Такий режим адресації зручний під час роботи з константами.
Малюнок 5.1 – Безпосередня адресація
Приклади: mov ax, 5564h
add al, 1101001100b
Слід пам'ятати, що безпосередній операнд може бути заданий лише як операнд-джерело. Недоліком безпосередньої адресації є необхідність розширення формату команд рахунок вказівки самого операнда в адресному полі команди.
2)Прямий– адреса операнда міститься у коді команди (Малюнок 5.2). Використовується при роботі зі змінними та константами, розташування яких у пам'яті не змінюється у процесі виконання завдання.
![]()
Малюнок 5.2 – Пряма адресація
Таким чином, у коді команди вказується усунення операнда в пам'яті.
Приклад: d_s segment
assume ds:d_s, cs:c_s
mov ax , mm ;за адресою mm пересилається 3154h
Після виконання третьої команди у регістрі axбуде записано значення за адресою mmу пам'яті, тобто, число 3154h.
3) Реєстровий- Це міститься в певному командою регістрі, тобто, в адресному полі команди вказується адреса регістру.
Приклади: mov ax, cx
Реєстрову адресацію легко відрізнити від інших за тією ознакою, що це операнди команд є регістрами. Такі команди є найбільш компактними і виконуються швидше за інші типи команд, оскільки відсутні звернення до пам'яті.
4) Реєстровий непрямий- є окремим випадком непрямої адресації, коли адреса, що вказується в команді, є вказівником осередку, що містить зміщення операнда в пам'яті (Малюнок 5.3).
Фактично в команді вказується адреса адреси, причому як регістр адреси може виступати базовий регістр BPабо індексні регістри SIабо DI.
Непряма адресація є більш ефективною, ніж пряма, оскільки в адресному полі команди вказується лише адреса регістра, який коротший за повну адресу операнда в пам'яті. Однак при цьому режимі адресації потрібно попереднє завантаження регістра непрямою адресою пам'яті, на що витрачається додатковий час.
Приклади: mov ax,
Якщо у регістрі siміститься 10, то в регістр axбуде вміщено значення, що знаходиться у зміщенні 10 в сегменті даних.
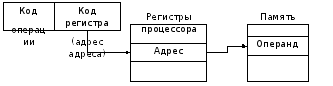
Рисунок 5.3 – Непряма адресація
Непряму адресацію зручно використовувати під час вирішення завдань, коли залишаючи незмінним адресу регістру у команді, можна змінювати вміст осередки з цією адресою.
5) Реєстровий відносний– є узагальненням методів адресації, які забезпечують обчислення ефективної адреси ( EA) операнда в пам'яті у вигляді суми базового значення адреси та зміщення disp, що вказується в команді (Малюнок 5.4) і (Формула 5.1).
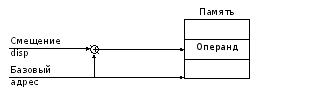
Рисунок 5.4 – Формування ефективної адреси при
відносної адресації
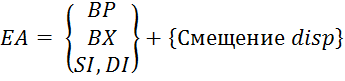 (5.1)
(5.1)
Відносну адресацію широко застосовують як адресації пам'яті, представленої як блоків (наприклад, сегментів), так адресації спеціальних структур даних: масивів, записів та інших. Залежно від способу використання адресованого в команді регістру, розрізняють базовий і індексний режими адресації.
5.1) Індексний- Застосовується для обробки впорядкованих масивів даних, кожне з яких визначається власним номером. Тоді базова адреса масиву задається усуненням disp, що вказується в команді, а значення індексу (номер елемента масиву) визначається вмістом індексного регістру (Формула 5.2).
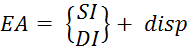 (5.2)
(5.2)
Приклад: d_s segment
mas db 3,5,1,8,9,'$'
assume ds:d_s, cs:c_s
mov si,0 ;в si-номер елемента масиву
m1: mov ah, mas ;mas-усунення
;в ah – значення елемента масиву mas з
номером в si
Індексна адресація зручна, якщо необхідно записати або рахувати список даних із послідовних осередків пам'яті не поспіль, а з деяким кроком, вказаним в індексі.
5.2) Базовий– застосовується доступу до структур даних змінної довжини. Тоді базова адреса, яка визначає початок набору елементів, зберігається в базовому регістрі, а зміщення в команді визначає відстань до певного елемента (Формула 5.3).
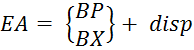 (5.3)
(5.3)
Цей режим адресації зручно використовувати для записів структур даних, що містять поля різної довжини і можливо різних типів.
Розглянемо приклад організації запису про співробітників деякого відділу та доступу до неї та її полів. Умовимося, що всі символічні поля.
worker struc ;інформація про співробітника
nam db 30 dup (" ") ;прізвище, ім'я, по батькові
position db 30 dup (" ") ;посада
age db 2 dup(' ') ;вік
standing db 2 dup(' ') ;стаж
salary db 5 dup(' ') ;оклад у рублях
;опис одного співробітника
sotr1 worker<‘Иванов Пётр Сергеевич’,
'програміст', '30', '8', '15000'>
assume ds:d_s, cs:c_s
;завантажуємо в bx адресу початку запису (базова адреса)
lea bx , sotr 1
;в ax – значення за адресою bx+зміщення по полю age
; тобто, від початку запису знаходимо комірки,
mov ax , слово ptr [ bx ]. age
У записах з полями різної довжини вміст регістру, що адресується, відповідає початку запису, а зміщення в команді - відстані в записі.
Методи адресації даних. Реєстровий, базовий індексний, відносний базовий індексний режим адресації.
6) Базово-індексний– використовується для доступу до елементів масиву, адресованого покажчиком. Базова адреса масиву задається вказівником бази (базовим регістром), а номер елемента масиву – вмістом індексного регістру (Формула 5.4).
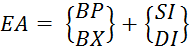 (5.4)
(5.4)
Приклад: mov ax, bx
Якщо в bxміститься 100, а в siзнаходиться 52, то за адресою (зміщення) 152 в сегменті даних знаходиться дане.
Такий режим адресації зручно використовувати під час роботи зі складними структурами даних, оскільки дозволяє змінювати дві адресні компоненти.
7) Відносний базовий індексний– використовується для адресації елементів у вказаному масиві записів. Базова адреса масиву задається покажчиком бази, номер запису (тобто елемента масиву) визначається вмістом індексного регістру, а зміщення в команді вказує відстань до запису (Формула 5.5).
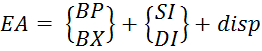 (5.5)
(5.5)
;опишемо масив з 5 співробітників зі значеннями по
;замовчанням
mas_sotr worker 5 dup (<>)
assume ds:d_s, cs:c_s
;в bx - адреса початку масиву співробітників
lea bx , mas _ sotr
;в si – зміщення другого запису
mov si , ( type worker )*2
; у ax – стаж другого співробітника
mov ax,.standing
Таким чином, щоб отримати доступ до конкретного поля масиву записів, спочатку необхідно визначити початок масиву, в ньому знайти потрібний запис, а вже в ньому – поле.
Вибір режиму адресації визначається конкретним завданням та у багатьох випадках очевидний. Однак виникають ситуації, коли для звернення до тих самих елементів даних допускається використання кількох способів адресації. Зрештою, під час написання програми сам користувач здійснює вибір конкретного режиму адресації.
Методи адресації команд.
Залежно від цього, у якому сегменті коду перебуває необхідна команда і явно чи ні вказується її адресу, виділяють такі режими адресації команд:
1) Внутрішньосегментний прямий– ефективна адреса переходу обчислюється як сума поточного вмісту покажчика команд IP та 8- або 16-бітного відносного зміщення. Даний режим допустимо в умовних та безумовних переходах. Наприклад,
Якщо вміст регістрів ahі alне рівні (команда jne), то здійснюється перехід до команди з міткою met.
2) Міжсегментний прямий- У команді вказується пара: сегмент і зсув. Сегмент завантажується в сегментний регістр CS, а усунення - в регістр IP. Цей режим допусти лише у командах безумовного переходу. Наприклад, call far ptr quickSort (виклик процедури quickSort, розташованої в іншому сегменті коду).
Таким чином, при прямій адресації в адресному полі команди міститься адреса переходу - адреса, за якою розміщується наступна команда, що виконується.
3) Внутрішньосегментний непрямий- Зміщення адреси переходу є вміст регістру або комірки пам'яті, вказані в будь-якому режимі адресації даних, крім безпосереднього. Вміст покажчика команд IP замінюється відповідним вмістом регістру або комірки пам'яті. Даний спосіб допустимо лише у командах безумовного переходу. Наприклад, jmp (перейти на команду, адреса якої знаходиться в осередку за адресою, вказаною в регістрі bx).
4) Міжсегментний непрямий – вміст регістрів CS та IP замінюється вмістом двох суміжних слів пам'яті, адреса яких вказана у будь-якому режимі адресації даних, крім безпосереднього та регістрового. Молодше слово завантажується в регістр IP, старше – у регістр CS. Цей режим допустимо лише у командах безумовного переходу. Наприклад, call far ptr (виклик процедури, розташованої за адресою, вказаною в регістрі BP плюс ще 4 байти).
Розглянуті способи адресації команд використовуються практично у всіх системах команд, розширюючи чи скорочуючи список команд конкретного мікропроцесора.
Як зазначалося раніше, однією з важливих характеристик будь-якого процесора є розрядність його внутрішніх регістрів, і навіть зовнішніх шин адрес і даних. Наприклад, процесор Intel 8086 має 16-розрядну архітектуру і таку ж розрядність шину даних. Таким чином, максимальне число, з яким може працювати процесор, становить ![]() . Однак, адресна шина процесора Intel 8086 містить 20 ліній, що відповідає адресному простору Мбайт. Для отримання 20-розрядної фізичної адреси осередку пам'яті потрібно скласти початкову адресу сегмента пам'яті, в якому розташовується ця осередок, і зміщення цього осередку щодо початку сегмента (Малюнок 5.5).
. Однак, адресна шина процесора Intel 8086 містить 20 ліній, що відповідає адресному простору Мбайт. Для отримання 20-розрядної фізичної адреси осередку пам'яті потрібно скласти початкову адресу сегмента пам'яті, в якому розташовується ця осередок, і зміщення цього осередку щодо початку сегмента (Малюнок 5.5).
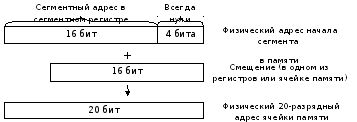
Рисунок 5.5 – Формування фізичної адреси осередку пам'яті
Сегментна адреса без 4 молодших бітів (тобто ділена на 16) зберігається в одному з сегментних регістрів (SS, DS, CS, ES).
При обчисленні фізичної адреси процесор множить вміст сегментного регістру на 16 і додає до отриманого 20-розрядного зсуву.
Сучасні 32-розрядні процесори мають 32-розрядну адресну шину, що відповідає адресному простору Гбайта. Однак описаний вище спосіб формування фізичної адреси не дозволяє вийти за межі 1 Мбайт. Для подолання цього обмеження у 32-розрядних процесорах використовуються два режими роботи: реальний та захищений. У реальному режиміпроцесор функціонує фактично так само, як Intel 8086 з підвищеною швидкодією і може звертатися лише до 1 Мбайту адресного простору. Пам'ять, що залишилася, навіть якщо вона встановлена на комп'ютері, використовуватися не може. У захищеному режимітакож використовуються сегменти та зміщення, але фізичні початкові адреси сегментів вилучаються з таблиць сегментних дескрипторів, що індексуються за допомогою тих же сегментних регістрів. Кожен сегментний дескриптор займає 8 байт, з яких 4 байти (32 біти) відводяться під сегментну адресу. Такий механізм дозволяє забезпечити повне використання 32-розрядного адресного простору. У 64-розрядних процесорах також застосовується сегментна організація пам'яті і може використовуватися сегментно-сторінкова організація пам'яті; під фізичну адресу відводиться 40, 44, 48, 64 розряди. Таким чином, обсяг адресного простору в 64-розрядних мікропроцесорах може становити від 1Тбайта (1 терабайт – байт) до кількох Ебайтів (1 ексабайт – байт).
У попередніх розділах згадувалося, що процесор, з одного боку, координує функціонування окремих пристроїв обчислювальної машини, з іншого,- сам виконує обчислення відповідно до програмою користувача (принцип програмного управління). Далі розглянемо, як здійснюється виконання команд процесором та її взаємодію Космосу з іншими пристроями.
Передача керування. Переходи та процедури.
Згідно з /8/, потік управління– це послідовність, у якій команди виконуються динамічно (під час виконання програми). Більшість команд не змінюють потік управління: після виконання однієї команди виконується команда, розташована за нею пам'яті. Лічильник команд (IP) після виконання кожної команди збільшується на число, що відповідає довжині команди. Зміна потоку управління відбувається за наявності команд переходів (умовних та безумовного), виклику процедур, співпрограм, а також при виникненні винятків та переривань.
1)Команди переходу. Під час виконання команд переходу в лічильник команд IP примусово записується нове значення – нову адресу пам'яті, починаючи з якого виконуватимуться команди.
Команда безумовного переходузабезпечує перехід за заданою адресою без перевірки будь-яких умов. Наприклад, jmp met означає перехід до команди, яка починається з адреси metу тексті програми. При цьому всі попередні команди пропускаються.
Умовний перехід(розгалуження) відбувається тільки при дотриманні певної умови, інакше виконується наступна по порядку команда програми. Умовою, виходячи з якого здійснюється перехід, найчастіше виступають ознаки результату виконання попередньої арифметичної чи логічної команди. Кожен із ознак фіксується у своєму розряді регістру прапорів PSW. Можливий і такий підхід, коли рішення про перехід приймається залежно стану одного з регістрів загального призначення, куди попередньо поміщається результат операції порівняння /3/. Розглянемо приклади:
|
jz m1 m1: add al,2 |
cmp ah,al je m1 m1: add al,2 |
Лівий фрагмент ілюструє перевірку вмісту регістрів AH та AL на рівність, використовуючи прапори, зокрема, прапор нуля ZF. Попередньо виконується віднімання вмісту регістрів: якщо їх значення дорівнюють, то в результаті утворюється нуль і змінюється значення прапора ZF. Команда JZ перевіряє, якщо прапор ZF дорівнює 1, то виконується перехід на команду з адресою M1(add al,2), інакше виконується команда додавання add ah,3. Команда з адресою M2 виконується у будь-якому випадку. Правий фрагмент виконує ту ж саму перевірку, але з використанням команди порівняння (cmp ah,al) та команди переходу по рівності (je m1).
2) Процедури. Відповідно до /3,8/, важливим способом структурування програм є процедура. Вона може бути викликана у будь-якій точці програми. Але на відміну від команд переходу після виконання процедури управління повертається до команди, що йде за командою виклику процедури.
Процедурний механізм базується на командах виклику процедури, що забезпечують перехід з поточної точки програми до початкової команди процедури, і командах повернення з процедури для повернення в точку, що безпосередньо розташована за командою виклику. Для роботи з процедурами використовується стек (додаткова пам'ять, організована у вигляді черги), в який команда виклику містить поточне значення лічильника команд (IP) при внутрішньосегментних переходах (або значення регістрів IP і CS при міжсегментних переходах) – адреса точки повернення. При виході з процедури старі значення відповідних регістрів відновлюються зі стека. Процедура обмежується операторами PROC та ENDP.
Особливий інтерес представляє рекурсивна процедура - процедура, яка викликає сама себе або безпосередньо, або через ланцюжок інших процедур. Для таких процедур також використовується стек, в якому, крім адреси повернення, зберігаються параметри та локальні змінні для кожного виклику.
Розглянемо як приклад програму, яка використовує виклик процедури. Оскільки процедура розташована в тому ж сегменті коду, що й основна програма і описана як процедура ближнього виклику (директива NEAR), перехід буде внутрішньосегментним.
s_s segment stack "stack"
assume ss:s_s,ds:d_s,cs:c_s
call pr 1 ;виклик підпрограми
mov ah ,4 ch
pr1 procnear;початок підпрограми (ближній виклик)
push ax ;записати в стек вміст регістру AX
pop ax ;вибрати зі стека вміст регістру AX
ret команда повернення на наступну команду після
;виклику процедури
pr1 endp;кінець підпрограми
При виконанні виклику процедури PR1 (команда call pr1) у стек міститься адреса повернення – вміст лічильника команд IP, що містить даний моментадреса команди, яка повинна виконуватись після поточної (mov ah,4ch). Значення регістру IP замінюється новим значенням – адресою першої команди процедури. При досягненні команди повернення з процедури (ret) зі стека в регістр IP записується старе значення, що забезпечує повернення в основну програму на команду mov ah, 4ch, яка безпосередньо слідує за командою виклику процедури.
Взаємодія процедури, що викликає і викликається, ілюструє малюнок 5.6 /8/.
Передача керування. Співпрограми. Винятки та переривання
Співпрограми. У звичайній послідовності викликів існує чітка відмінність між викликаною процедурою і процедурою, що викликає. Викликана процедура щоразу починається спочатку, скільки б разів до неї не відбувалося звернення. Для виходу з процедури використовується команда повернення RET, як описано в попередньому пункті. Нехай є дві процедури A і B, кожна з яких викликає іншу як процедуру. При поверненні з B до A процедура B здійснює перехід до оператора, що йде за командою виклику процедури B. Коли процедура A передає управління процедурі B, вона повертається не до самого початку B (за винятком першого разу), а до того місця, де стався попередній виклик A. Процедури, що працюють подібним чином, називаються співпрограмами.
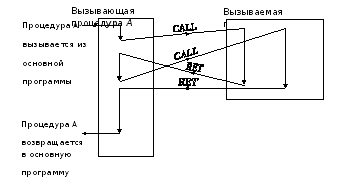
Рисунок 5.6 – Взаємодія зухвалої та викликаної
процедур
Зазвичай співпрограми використовуються для того, щоб проводити паралельну обробку даних на одному процесорі. Звичайні команди CALL і RET не підходять для виклику співпрограм, оскільки адреса для переходу береться зі стека, як і при поверненні, але, на відміну від повернення, при виклику програми адреса повернення поміщається в певному місці, щоб в подальшому до нього повернутися. Для цього спочатку необхідно виштовхнути стару адресу повернення зі стека і помістити її у внутрішній регістр, потім помістити лічильник команд IP у стек і, нарешті, скопіювати вміст внутрішнього регістру в лічильник команд. Оскільки одне слово виштовхується зі стека, а інше поміщається у стек, стан покажчика стека не змінюється. Схема взаємодії співпрограм показано малюнку 5.7 /8/.
Рисунок 5.7 – Взаємодія співпрограм
4) Винятки та перериваннязабезпечують примусову передачу управління спеціальною процедурою - обробнику системних переривань, що виконує певні дії. Після завершення дій обробник переривання повертає керування перерваною програмою. Вона повинна продовжити виконання перерваного процесу в тому самому стані, в якому перебувала в момент переривання. Обробник переривань відрізняється від звичайної процедури тим, що замість зв'язування з конкретною програмою він розміщується у фіксованій області пам'яті.
Виняток- це особливий тип виклику процедури, який відбувається за певної умови – важливою, але такою, що рідко зустрічається. Найбільш поширені умови, які можуть викликати винятки, - переповнення і зникнення значущих розрядів при операціях з плаваючою точкою, переповнення при операціях з цілими числами, порушення захисту, невизначений код операції, переповнення стека, спроба запустити неіснуюче УВВ, спроба викликати слово з комірки адресою, поділ на нуль. Якщо результат перебуває у межах допустимого, виняток немає. Важливо, що це вид переривання викликається якимось винятковим умовою, викликаним самої програмою і виявленим апаратним забезпеченням чи мікропрограмою. Винятки, у свою чергу, поділяються на збої, пасткиі аварійні завершення.
Збій– це виняток, повідомлення про який видається на межі команди, що передує команді, що викликала цей виняток. Після повідомлення про збій, стан обчислювальної машини відновлюється в ситуацію, коли можна виконати рестарт команди. Прикладом збою може бути звернення до неіснуючого УВВ.
Пастка– це виняток, повідомлення про яке видається на межі команди, безпосередньо розташованої після команди, для якої було виявлено цей виняток. Наприклад, переповнення під час обробки цілих чисел.
Аварійне завершення- Це виняток, що не дозволяє ні точно визначити команду, що викликала його, ні перезапустити програму, в якій відбувся цей виняток. Аварійні завершення використовуються для повідомлення про серйозних помилок: апаратні помилки, суперечливі або неприпустимі значення в системних таблицях.
Переривання- це зміни у потоці управління, викликані не самої програмою, а якимись асинхронними подіями, і пов'язані зазвичай із процесом вводу-вывода. Переривання дають можливість здійснювати операції введення-виведення незалежно від процесора. Оскільки швидкодія мікропроцесора вище, ніж УВВ, процесор має можливість виконувати інші програми або здійснювати інші функції замість постійного контролю стану приєднаних до нього периферійних пристроїв. Коли УВВ вимагає обслуговування з боку процесора, воно повідомляє йому про це шляхом формування відповідного запиту (сигналу), яким процесором може бути перерване виконання поточної програми. Управління перериваннями від УВВ здійснюється контролером переривань, який підключений до процесора та структурно входить до його складу.
Відмінність між винятками і перериваннями у тому, що винятки синхронні стосовно програмі, а переривання асинхронні. Винятки викликаються програмою безпосередньо, а переривання – опосередковано. Якщо багаторазово перезапускати програму з одними й тими самими вхідними даними, винятки виникатимуть щоразу у одних і тих місцях програми, а переривання - немає.
Наявність сигналу переривання не обов'язково має викликати переривання програми, що виконується, процесор може мати систему захисту від переривань: відключення системи переривань, заборона або маскування окремих сигналів переривань. Програмне керування цими засобами дозволяє операційній системі регулювати обробку сигналів переривань. Процесор може обробляти переривання відразу після їхнього приходу, відкладати їхню обробку певний час, повністю ігнорувати. Наприклад, якщо встановлений в одиницю прапорець трасування TF, процесор виконує одну команду програми, а потім генерує переривання типу 1, тобто, програма виконується по кроках. Якщо скинутий прапор переривань IF, процесор не реагує на зовнішні переривання (за винятком немаскируемых). Для маскування окремих видів переривань використовується регістр масок. Керується командами CLI (заборонити переривання) та STI (дозволити переривання).
З кожним окремим типом переривання або винятком пов'язаний номер, що його ідентифікує, в діапазоні від 0 до 255 і відповідний обробник. Виняткам і немаскируемым перериванням присвоєні номери з інтервалу від 0 до 31, а перериванням, що маскуються, – від 32 до 255. Не всі з цих значень використовуються процесорами в даний час; непризначені номери зарезервовані для використання у майбутньому. Номери переривань, винятків та адреси (вектори) відповідних обробників зберігаються у спеціальній таблиці – таблиці векторів перериваньв пам'яті. У разі переривання чи виключення за його номером у таблиці векторів переривань визначається адресу відповідної процедури обробки переривання чи виключення, до якої здійснюється перехід. Розглянемо докладніше, як виконується виклик і повернення з обробника переривань чи винятків.
Механізми обробки переривань та винятків багато в чому схожі, але є деякі відмінності, пов'язані з поверненням з оброблювача. Механізм обробки переривань включає наступні етапи:
1) Встановлення факту переривання.
2) Запам'ятовування в стеку стану перерваного процесу, що визначається вмістом регістру прапорів PSW, лічильника команд IP, сегментного регістру CS. При необхідності також запам'ятовується вміст регістрів, які будуть використовуватися процедурою переривання і, отже, змінюватися. Деякі типи винятків і переривань також поміщають у стек код помилки для того, щоб діагностувати причину, що викликала виняток.
3) Визначення адреси процедури обробки переривання за номером переривання у таблиці векторів переривань та здійснення переходу до цього оброблювача шляхом завантаження адреси у регістри CS та IP.
4) Обробка переривання. Процедура обробки переривання виконує свої команди.
5) Відновлення стану перерваної програми. Після успішного виконання процедури обробки переривання при досягненні команди IRET (цією командою завершуються обробники переривань) з стека відновлюється старий вміст регістрів, що зберігаються в ньому (старий стан), в т.ч., і адреса повернення– значення регістрів CS та IP.
6) Повернення у перервану програму. З адреси повернення здійснюється перехід до перерваного процесу. Повернення повинно здійснюватися на команду, яка йде за командою, виконаною до виникнення переривання. Процедура обробки переривань, що має таку властивість, називається прозорою.
При виникненні збою адреса повернення є адресою команди, що викликала збій, тому повернення здійснюється знову до цієї команди для спроби її повторного виконання (рестарту). Обробка пасток аналогічна обробці переривань. При аварійних завершеннях обчислювальний процес завершується без можливості відновлення вихідного стану програми, у якій стався виняток.
Оскільки сигнали переривань виникають у довільні моменти часу, то на момент переривання може існувати кілька сигналів переривань, які можуть бути оброблені тільки послідовно. Для цього перериванням надаються пріоритети. Існують дві дисципліни обслуговування пріоритетних переривань: 1) переривання з більш високим пріоритетом може перервати обробку переривання з нижчим пріоритетом та 2) переривання з нижчим пріоритетом обслуговується до кінця, після чого обробляється переривання з більш високим пріоритетом.
У наступному розділі розглянемо питання щодо організації пам'яті ВМ.
Архітектурні особливості процесорів Pentium.
Відповідно до /2/, мікропроцесор Pentium (1993 рік) є першим суперскалярним процесором для персональних комп'ютерів. Включає такі функціональні блоки:
1) блок ШІ;
2) два 5-ступінчасті конвеєри (U і V) виконання команд цілочисленних обчислень;
3) роздільні кеші команд та даних рівня L1 об'ємом 8 Кбайт кожен;
4) блок обчислень з плаваючою точкою FPU, організований у вигляді конвеєра;
5) блок передбачення розгалужень;
6) блок керування пам'яттю.
Більшість команд виконуються за один такт. У разі виконання складних команд використовується розширений мікрокод із ПЗУ мікропрограм складних команд.
Конвеєри Pentium реалізують традиційні 5 етапів виконання команд (вибірку, декодування операції, читання операндів, запис результатів). При обчисленні операцій з плаваючою точкою додаються ще три кроки: X1 – перетворення даних у форматі розширеної складності, X2 – виконання FPU-команди, WF – округлення результату та його запис у регістровий файл FPU. Конвеєр U може виконувати як цілі команди, так і команди з плаваючою точкою. При цьому команди арифметики з плаваючою точкою не можуть запускатися в парі з цілими командами. Крім того, конвеєр U містить багаторозрядний зсув, що використовується при виконанні арифметичних, логічних, циклічних зрушень, операцій множення та поділу. Конвеєр V виконує лише цілі команди.
Використання незалежних кешів забезпечує одночасний безконфліктний доступ до них. Кеш-пам'ять команд пов'язана з буфером попередньої вибірки 256-бітовою шиною. Якщо команда, що вибирається, в кеш-пам'яті відсутня, то виконується читання шуканої команди з основної пам'яті і її завантаження в буфер передвиборки з одночасним записом в кеш команд.
Кеш-пам'ять даних з'єднується з конвеєрами U та V за допомогою двох 32-розрядних шин, що забезпечує можливість одночасного звернення до неї з боку кожного конвеєра.
Блок управління пам'яттю здійснює двоступінчасте формування фізичної адреси осередку пам'яті спочатку в межах сегмента, а потім у межах сторінки. Для керування роботою зовнішнього кешу використовуються спеціальні апаратні засоби.
Архітектурним нововведенням Pentium є спеціальний режим системного управління (SMM – System Management Mode), який розроблений для переведення системи у стан зниженого енергоспоживання. Цей режим недоступний додатків і керується програмою з ПЗП на кристалі процесора. У режимі SMM Pentium використовує інший, ізольований від інших режимів простір пам'яті.
Блок ШІ забезпечує зв'язок процесора з іншими пристроями через системну шину, що включає 64-розрядну шину даних і 32-розрядну шину адреси і шину управління. Процесор Pentium підтримує роботу систем із фізичною пам'яттю до 4 Гбайт.
Розвиток процесорів Pentium пов'язане, передусім, із удосконаленням технології їх виробництва, розширенням системи команд, удосконаленням алгоритмів передбачення переходів, методів завантаження конвеєрів, способів взаємодії з кеш-пам'яттю.
Відмінною особливістю процесорів Pentium 6-го (Pentium Pro, Pentium II, Pentium III) та 7-го (Pentium IV) поколінь від ранніх моделей Pentium є інший підхід до реалізації принципу багатоопераційної обробки даних. Він полягає в тому, що замість збільшення числа конвеєрів виконання команд, що потребує значних апаратних витрат, використовується один конвеєр з великою кількістю виконавчих блоків. Наприклад, обробка команд Pentium IV здійснюється 20-ступінчастим конвеєром (гіперконвеєром), який умовно можна розділити на 3 відносно незалежних конвеєра:
1) Вхідний конвеєр упорядкованої обробки, який забезпечує вибірку команд із пам'яті, декодування їх у внутрішні RISC-команди та усунення хибних взаємозв'язків за даними та ресурсами.
2) Конвеєр невпорядкованої обробки, який реалізує власне виконання команд. При невпорядкованій обробці інтенсивніше завантаження конвеєрів суперскалярного процесора. Щоб гарантувати правильне виконання програми, результати команд, виконаних позачергово, повинні записуватися за цільовими адресами у тому порядку, як вони йдуть у вихідної програмі. Цю роботу здійснює спеціальний блок процесора – блок тимчасового зберігання результатів, виконаних позачергово.
3) Конвеєр виведення результатів виконання команд, який здійснює запис результатів до архітектурних регістрів процесора та пам'ять у порядку, передбаченому програмою.
Ефективна робота гіперконвеєра Pentium IV також забезпечується рахунок спекулятивного виконання команд, коли безперервної завантаження конвеєра виконуються дії, не передбачені програмним кодом.
У блоці передбачення розгалужень використовується більш досконалий, порівняно з попередніми моделями процесорів Pentium, алгоритм передбачення розгалужень. Адреси команд переходів та мітки розгалужень з детальною передісторією зберігаються в буфері (об'ємом 4 Кбайта) блоку передбачення розгалужень.
Ще однією важливою відмінністю процесора Pentium IV від ранніх моделей є використання у його структурі замість кешу команд кешу трас. Траси– це послідовності мікрокоманд, в які декодовані команди x86, що належать до однієї або кількох гілок вихідної програми. У кеші можуть розміщуватись до 12 Кбайт мікрокоманд. У кеш трас не потрапляють команди, які ніколи не використовуватимуться. Кеш трас спільно з блоком вибірки утворюють пристрій попередньої обробки.
Використання гіперконвеєра, кешу трас і більш продуктивного виконавчого ядра дозволило досягти Pentium IV істотного підвищення продуктивності.
Програмна модель процесорів Pentium.
Об'єднуючою характеристикою розглянутих мікропроцесорів Pentium і те, що вони, незважаючи на суттєві відмінності в архітектурі, мають однакову програмну модель. Сукупність всіх програмно доступних регістрів процесора утворює його програмну модель/2/. Вона показує ресурси процесора, якими може користуватися програміст.
Програмна модель підрозділяється на прикладну та системну. До складу прикладної програмної моделі(ППМ) процесора входять повний набір регістрів, які доступні прикладним програмістам; особливості організації пам'яті та доступні способи адресації; типи даних та команд. Системна програмна модель(СПМ) процесора об'єднує його програмно доступні системні ресурси, за допомогою яких забезпечується доступ до вбудованих механізмів захисту та багатозадачності. СПМ процесора переважно використовується системними програмістами.
Всі існуючі на сьогоднішній день мікропроцесори можна умовно розділити на 4 групи:CISC (ComplexInstructionSetCommand) - з повним набором інструкцій;RISC (ReducedInstructionSetCommand) - з усіченим набором інструкцій;VLIW (VeryLongIntegerWord) - З надвеликим командним словом;MISC (MinimumInstructionSetCommand) - з мінімальним набором інструкцій.
Основні представники процесорів типуCISC - МП фірми Intelпредставлені у таблиці 3.2.
МП типу RISC містять скорочений набір інструкцій, що найчастіше використовуються в програмах. Якщо необхідно виконати якусь складну інструкцію, МП збирає її з простих. Особливістю цих МП є те, що всі прості команди виконуються за однакову кількість часу, що дорівнює одному машинному такту.
ПРИМІТКА
RISC процесори випускаються різними фірмами: IBM (Power PC), DEC (Alpha), HP (PA), Sun (Ultra SPARC) та іншими.
Найбільш відомий представникRISC процесорів - МПPowerPC (PerformanceOptimizedWithEnhancedPC) застосовується в настільних та професійних рішеннях від компаніїAppleПроте нещодавно «яблучники» оголосили про перехід на архітектуру.Intel. МП RISCхарактеризуються високою швидкодією, але програмно не сумісні з процесорамиCISC. Тому для запуску додатків розроблених дляIBMPCсумісних ЕОМ на машинах типуAppleMacintoshпотрібно «емулятор», що різко знижує їх ефективність.
Таблиця 3.2.Характеристики мікропроцесорів фірми Intel
|
Модель |
Розряд- ність даних/ адреси (біт) |
Тактова Частота (МГц) |
Адресний простір (байт) |
Склад команд |
Ступінь інтеграції/ техпроцес |
Напруження Харчування (В) |
Рік випуску |
|
4004 |
4 /4 |
0,108 |
2 300/10 мкм |
1971 |
|||
|
8080 |
8 /8 |
64К |
10 000/6 мкм |
1974 |
|||
|
8086 |
16 /16 |
4,77 та 8 |
70 000/3 мкм |
1979 |
|||
|
8088 |
8 , 16 /16 |
4,77 та 8 |
70 000/3 мкм |
1978 |
|||
|
80186 |
16/20 |
8 та 10 |
140 000 |
1981 |
|||
|
80286 |
16/24 |
8-20 |
16М |
180 000/ 1,5 мкм |
1982 |
||
|
80386 |
32/32 |
16-50 |
4G |
275 000/1 мкм |
1985 |
||
|
80486 |
32/23 |
25-100 |
1,2 млн./ 1 мкм |
1989 |
|||
|
Pentium |
64/32 |
60-233 |
3,3 млн./ 0,5 та 0,35 мкм |
1993 |
|||
|
Pentium Pro |
64/32 |
150-200 |
5,5 млн./ 0,5 та 0,35 мкм |
1995 |
|||
|
Pentium MMX |
64/36 |
166-233 |
57 (MMX) |
5 млн./ 0,35 мкм |
1997 |
||
|
Pentium II (ядро Katmai) |
64/36 |
233-600 |
MMX+(MMX2) |
7,5 млн./ 0,25 мкм |
1997 |
||
|
Celeron (ядро Mendocino) |
64/32 |
300-800 |
MMX2 |
19 млн./ 0,25 та 0,22 мкм |
1998 |
||
|
Pentium III (Coppermine) |
64/36 |
500-1000 |
MMX+70 |
28 млн./ 0,18 мкм |
1,65 |
1999 |
|
|
Pentium III Xeon |
64/36 |
500-1000 |
MMX2 |
30 млн./ 0,18 та 0,13 мкм |
1,65 |
1999 |
|
|
Pentium 4 (Willamette) |
64/36 |
1000-3500 |
64G |
MMX 2+144 |
42 млн./ 0,13 мкм |
1,1-1,85 |
2000 |
МП типу VLIW на відміну від суперскалярнихCISCпроцесорів мають значно простішу схемну реалізацію і спираються на програмне забезпечення. Програмісти не мають доступу до внутрішніхVLIW-командам, тому всі прикладні програми та операційна системапрацюють поверх спеціального низькорівневого програмного забезпечення (CodeMorphing), що здійснює трансляцію інструкційCISC-процесора у командиVLIW. Спрощена апаратна частинаVLIWдозволяє суттєво знизити розміри МП та забезпечити знижене тепловиділення та енергоспоживання.
VLIWпроцесори випускає фірмаTransmeta- МП під торговою маркоюCrusoe, перший МП VLIWвід Intelна ядрі Mercedвикористовував повний набір інструкційIA-64, ця технологія називаєтьсяEPIC (ExplicitlyParallelInstructionComputing- Обчислення з явною паралельністю інструкцій).
ПРИМІТКА
До VLIW процесорам можна віднести очікуваний до появи в 2002 МП Elbrus 2000 - E 2k, розроблений російською компанією «Ельбрус». Він мав невеликий розмір (повністю ховався за монетою 1 карбованець). На даний момент усі розробки компанії, а також її співробітники працюють на благо корпорації Intel.
Значна частина наукових та технічних обчислень передбачає роботу з векторами замість скалярних величин, що значно спрощує обчислення. Розглянемо дві моделі організації обчислень великих наукових программасивно-паралельний процесор (array processor ) та векторний процесор (vector processor ). Масивно-паралельний процесор складається з великої кількості подібних процесорів, що виконують одні й самі обчислення з різними наборами даних. Він являє собою структуру, що складається з декількох секторів, що являють собою ґратиNxNелементів процесора/пам'яті. Кожен сектор має власний блок управління.
ПРИМІТКА
Перший у світі масивно-паралельний процесор - ILLIAC IV (Університет Іллінойсу), мав ґрати 8х8 елементів процесор/пам'ять (один сектор, передбачалося побудувати 4 сектори) із швидкодією 50 млн. операцій на секунду. Векторні процесори випускає відома Cray Research, засновником якої був Сеймур Крей.
Відмінність векторного процесора полягає в тому, що всі операції додавання виконуються в одному блоці підсумовування, який має конвеєрну структуру. Цей процесор маєвекторний регістр , Що складається з набору стандартних регістрів. Ці регістри послідовно завантажуються з пам'яті з допомогою однієї команди. Команда складання попарно складає елементи двох таких векторів, завантажуючи їх із двох векторних регістрів у сумирний пристрій з векторною структурою. У результаті підсумовує пристрою виходить вектор.
Опис та призначення процесорів
Визначення 1
центральний процесор (ЦП) – основний компонент комп'ютера, який виконує арифметичні та логічні операції, задані програмою, керує процесом обчислень та координує роботу всіх пристроїв ПК.
Чим потужніший процесор, тим вища швидкодія ПК.
Зауваження
Центральний процесор часто називають просто процесором, ЦПУ (Центральний процесорний пристрій) або CPU (Central Processing Unit), рідше – кристалом, каменем, хост-процесором.
Сучасні процесори є мікропроцесорами.
Мікропроцесор має вигляд інтегральної схеми- тонкої пластинки з кристалічного кремнію прямокутної форми площею кілька квадратних міліметрів, на якій розміщені схеми з мільярдами транзисторів і каналів для проходження сигналів. Кристал-пластинка поміщений у пластмасовий або керамічний корпус та з'єднаний золотими проводками з металевими штирьками для підключення до системної плати ПК.
Малюнок 1. Мікропроцесор Intel 4004 (1971)

Малюнок 2. Мікропроцесор Intel Pentium IV (2001). Зліва – вид зверху, праворуч – вид знизу
ЦП призначений для автоматичного виконання програми.
Пристрій процесора
Основними компонентами ЦП є:
- арифметико-логічний пристрій(АЛУ) виконує основні математичні та логічні операції;
- керуючий пристрій(УУ), від якого залежить узгодженість роботи компонентів ЦП та його зв'язок з іншими пристроями;
- шини даних та адресні шини;
- регістри, у яких тимчасово зберігається поточна команда, вихідні, проміжні та кінцеві дані (результати обчислень АЛП);
- лічильники команд;
- кеш-пам'ятьзберігає часто використовувані дані та команди. Звернення в кеш-пам'ять набагато швидше, ніж в оперативну пам'ять, тому чим вона більша, тим вище швидкодія ЦП.
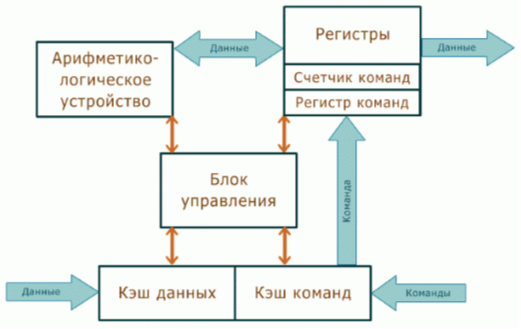
Рисунок 3. Спрощена схема процесора
Принципи роботи процесора
ЦП працює під управлінням програми, що знаходиться в оперативній пам'яті.
АЛУ отримує дані та виконує зазначену операцію, записуючи результат в один із вільних регістрів.
Поточна команда знаходиться у спеціальному регістрі команд. Працюючи з поточної командою значення так званого лічильника команд збільшується, який потім свідчить про наступну команду (виключенням може лише команда переходу).
Команда складається із запису операції (яку потрібно виконати), адреси осередків вихідних даних та результату. За вказаними в команді адресами беруться дані і поміщаються в звичайні регістри (у сенсі не в регістр команди), результат теж спочатку поміщається в регістр, а вже потім переміщається за своєю адресою, вказаною в команді.
Характеристики процесора
Тактова частотавказує частоту, де працює ЦП. За $1$ такт виконується кілька операцій. Чим вища частота, тим вища швидкодія ПК. Тактова частота сучасних процесоріввимірюється у гігагерцях (ГГц): $1$ ГГц = $1$ мільярд тактів на секунду.
Для підвищення продуктивності ЦП почали використовувати кілька ядер, кожне з яких є окремим процесором. Чим більше ядер, тим вища продуктивність ПК.
Процесор пов'язаний з іншими пристроями (наприклад, з оперативною пам'яттю) через шини даних, адреси та управління. Розрядність шин кратна 8 (т.к. маємо справу з байтами) і відрізняється для різних моделей, а також різна для шини даних та шини адреси.
Розрядність шини даних вказує на кількість інформації (у байтах), яку можна передати за $1$ разів (за $1$ такт). Від розрядності адресної шини залежить максимальний обсяг оперативної пам'яті, із яким може працювати ЦП.
Від частоти системної шинизалежить кількість даних, які передаються за час. Для сучасних ПК за $1$ такт можна передати кілька бітів. Важлива також пропускна здатність шини, рівна частоті системної шини, помноженої на кількість біт, які можна передати за $1$. Якщо частота системної шини дорівнює $100$ Мгц, а й за $1$ такт передається $2$ біта, то пропускна спроможність дорівнює $200$ Мбіт/сек.
Пропускна здатність сучасних ПК обчислюється в гігабітах (або десятках гігабіт) за секунду. Що цей показник, то краще. На продуктивність ЦП впливає також обсяг кеш-пам'яті.
Дані до роботи ЦП надходять з оперативної пам'яті, але т.к. пам'ять повільніше ЦП, він може часто простоювати. Щоб уникнути цього між ЦП і оперативної пам'яттю мають кеш-пам'ять, яка швидше оперативної. Вона працює як буфер. Дані з оперативної пам'яті надсилаються в кеш, а потім у ЦП. Коли ЦП вимагає наступне дане, то за наявності його в кеш-пам'яті воно береться з нього, інакше відбувається звернення до оперативної пам'яті. Якщо в програмі виконується послідовно одна команда за іншою, то під час виконання однієї команди коди наступних команд завантажуються з оперативної пам'яті в кеш. Це прискорює роботу, т.к. очікування ЦП скорочується.
Зауваження 1
Існує кеш-пам'ять трьох видів:
- Кеш-пам'ять $1$-го рівня найшвидша, знаходиться в ядрі ЦП, тому має невеликі розміри ($8–128$ Кб).
- Кеш-пам'ять $2$-го рівня знаходиться в ЦП, але не в ядрі. Вона швидше за оперативну пам'ять, але повільніше кеш-пам'яті $1$-го рівня. Розмір від $ 128 $ Кбайт до кількох Мбайт.
- Кеш-пам'ять $3$-го рівня швидше за оперативну пам'ять, але повільніше кеш-пам'яті $2$-го рівня.
Від обсягу цих видів пам'яті залежить швидкість роботи ЦП і комп'ютера.
ЦП може підтримувати роботу лише певного виду оперативної пам'яті: $DDR$, $DDR2$ чи $DDR3$. Чим швидше працює оперативна пам'ять, Тим вище продуктивність роботи ЦП.
Наступна характеристика – сокет (роз'єм), куди вставляється ЦП. Якщо ЦП призначений для певного виду сокету, його не можна встановити в інший. Тим часом, на материнській платі знаходиться лише один сокет для ЦП і він має відповідати типу цього процесора.
Типи процесорів
Основною компанією, що випускає ЦП для ПК є компанія Intel. Першим процесором для ПК був процесор $8086$. Наступною моделлю була $80286$, далі $80386$, згодом цифру $80$ стали опускати і ЦП почали називати трьома цифрами: $286$, $386$ тощо. Покоління процесорів часто називають сімейством $x86$. Випускаються інші моделі процесорів, наприклад, сімейства Alpha, Power PC та інших. Компаніями-виробниками ЦП також є AMD, Cyrix, IBM, Texas Instruments.
У назві процесора часто можна зустріти символи $X2$, $X3$, $X4$, що означає кількість ядер. Наприклад, у назві Phenom $X3$ $8600$ символи $X3$ вказують на наявність трьох ядер.
Отже, основними типами ЦП є $8086$, $80286$, $80386$, $80486$, Pentium, Pentium Pro, Pentium MMX, Pentium II, Pentium III та Pentium IV. Celeron є урізаним варіантом процесора Pentium. Після назви зазвичай вказується тактова частота ЦП. Наприклад, Celeron $450$ позначає тип ЦП Celeron та його тактову частоту – $450$ МГц.
Процесор потрібно встановлювати на материнську платуіз відповідною процесору частотою системної шини.
У останніх моделяхЦП реалізовано механізм захисту від перегріву, тобто. ЦП у разі підвищення температури вище критичної перетворюється на знижену тактову частоту, коли він споживається менше електроенергії.
Визначення 2
Якщо в обчислювальної системикілька паралельно працюючих процесорів, то такі системи називаються багатопроцесорними .
Вихідний варіант комп'ютера IBM PC та модель IBM PC XT використовували мікропроцесор Intel-8088. На початку 80-х ці мікропроцесори випускалися з тактовою частотою 4,77 МГц, потім були створені моделі з тактовою частотою 8, 10 і 12 МГц. Моделі зі збільшеною продуктивністю (тактовою частотою) іноді називають TURBO-XT. Зараз мікропроцесори типу Intel-8088 виробляються в невеликих кількостях, і для використання не в комп'ютері, а в спеціалізованих пристроях.
Модель IBM PC AT використовує потужніший мікропроцесор Intel-80286, і її продуктивність приблизно 4-5 разів більше, ніж в IBM PC XT. Вихідні варіанти IBM PC AT працювали на мікропроцесорах з тактовою частотою від 12 до 25 МГц, тобто працюють у 2-3 рази швидше. Мікропроцесор Intel-80286 має дещо більше можливостей у порівнянні з Intel-8088, але ці додаткові можливості використовуються дуже рідко, тому більшість програм, що працюють на AT, працюватиме і на XT. Зараз мікропроцесори типу Intel-80286 також вважаються застарілими та для застосування в комп'ютерах не виробляються.
У 1988-1991 pp. Більшість комп'ютерів, що випускаються, була заснована на досить потужному мікропроцесорі Intel-80386, розробленому фірмою Intelв 1985 р. Цей мікропроцесор (називається також 80386DX) працює вдвічі швидше, ніж працював би 80286 з тією ж тактовою частотою. Звичайний діапазон тактової частоти 80386DX – від 25 до 40 МГц. Крім того, фірмою Intel був розроблений також мікропроцесор Intel-80386SX, він ненабагато дорожче Intel-80286, але володіє тими ж можливостями, що і Intel-80386, тільки при більш низькій швидкій дії (приблизно в 1, 5-2 рази).
Мікропроцесор Intel-80386 не тільки працює швидше за Intel-80286, але й має значно більше можливостей, зокрема, він містить потужні засоби для 32-розрядних операцій (на відміну від 16-розрядних 80286 і 8088).
Ці засоби активно використовуються виробниками програмного забезпечення, тому багато програм, що випускаються зараз, призначені для використання тільки на комп'ютерах з мікропроцесорами моделі Intel-80386 або старшої.
При створенні мікропроцесора Intel-80386 фірма Intel розглядала його як передовий мікропроцесор, що забезпечує достатню продуктивність для більшості розв'язуваних завдань. Однак набула найширшого поширення починаючи з 1990-1991 р.р. операційна оболонка Windows фірми Microsoft різко збільшила вимоги до обчислювальних ресурсів комп'ютера, і в багатьох випадках робота Windows-програм на комп'ютері з процесором Intel-80386 виявилася занадто повільною. Тому протягом 1991-1992 рр. більшість виробників комп'ютерів переорієнтувалися використання більш потужного мікро процесора Intel-80486 (чи 80486DX). Цей мікропроцесор мало відрізняється від Intel-80386, але його продуктивність у 2-3 рази вища. Серед його особливостей слід зазначити вбудовану кеш-пам'ять та вбудований математичний співпроцесор. Фірмою Intel також розроблені більш дешевий, але менш продуктивний варіант -80486SX і дорожчі та швидші варіанти -80486DX2 і DX4. Тактова частота 80486 зазвичай знаходиться в діапазоні 25-50 МГц, 80486DX2-50-60 МГц, а DX4-до 100 МГц.
У 1993 р. фірмою Intel був випущений новий мікропроцесор Pentium (який раніше анонсувався під назвою 80586). Цей мікропроцесор ще потужніший, особливо при обчисленнях над речовими числами. Як і Intel-80486, він містить вбудований математичний співпроцесор, причому значно ефективніший, ніж у Intel-80486. Для збільшення продуктивності в Pentium застосовані й інші удосконалення: швидша і ширша магістраль передачі даних (шина даних), великий розмір вбудованої кеш-пам'яті, можливість виконання двох інструкцій одночасно і т. д. Тактова частота мікропроцесорів Pentium, що випускаються, - від 60 до 233 МГц. При цьому мікропроцесори Pentium працюють в 1,5-2 рази швидше за мікропроцесори типу 80486 з тією ж тактовою частотою, а для завдань, що вимагають інтенсивних обчислень над речовими числами -в 3-4 рази швидше.
Наприкінці 1996 - на початку 1997 років Intel випустила покращений процесор Pentium ММХ (MMX - Multimedia Extension). Хоча зовні він мало відрізняється від свого попередника, архітектура команд зазнала сильних змін. У наборі інструкцій мікросхеми з'явилося 57 нових. Вони призначені для виконання завдань, пов'язаних із обробкою аудіо-, відео-, графічних та телекомунікаційних даних.
Щоб розмістити в корпусі існуючого Pentium нові можливості, компанії довелося піти на деякі компроміси, а саме - процесори з ММХ не можуть одночасно виконувати інструкції ММХ та операції з плаваючою комою, так як і для ММХ команд, і для чисел з плаваючою комою використовуються одні та ті ж регістри вбудованого співпроцесора. Зроблено це для збереження повної сумісності Pentium ММХ з існуючим програмним забезпеченням. Це не така вже й велика проблема, оскільки співпроцесор використовують небагато програм. Однак якщо знайдуться програми, що вимагають від процесора частого перемикання між операціями з плаваючою комою і ММХ, вони виконуватимуться на ММХ - процесорі повільніше, ніж на звичайному процесорі з тактовою частотою.
Корпорація Intel 7 травня 1997 офіційно представила процесор Pentium II. Випускаються варіанти процесора з тактовою частотою 233 МГц і 300 МГц, розраховані харчування 2.8 У. Головною новиною стало те, що Pentium II не сумісний з існуючими материнськими платами для Pentium. Новий процесормонтуватиметься в S.E.C-картриджі (Single Edge Contact). Повністю закритий корпус картриджа захищає компоненти, пластина, що відводить тепло, дозволяє використовувати будь-які радіатори для пасивного або активного тепловідведення. Завдяки цьому тепловиділення для моделі з тактовою частотою 233 МГц не перевищує 38,2 Вт (для порівняння: Pentium 200МГц виділяє 37,9 Вт). Картридж S.E.C буде вставлятися в роз'єм Slot 1, запропонований Intel як новий технологічний стандарт форм-фактора компонування комп'ютера.
У січні 1999 р. корпорація Intel офіційно представила свій мікропроцесор для PC Pentium III. За словами представника компанії Сета Волкера, Pentium III має просунути технологію вперед відразу на декількох фронтах, включаючи тактову частоту (перші моделі процесора працюватимуть на частоті 450 і 500 МГц), обробку графіки, швидкість та надійність роботи з Інтернетом. План подальшого розвитку сімейства виробів Pentium III передбачає перехід із технологічної норми 0,25 мкм на 0,18 мкм (робоча назва відповідного мікропроцесора - Coppermine). Перехід з 0,25 мкм на 0,18 мкм призведе до підвищення його продуктивності та зниження споживаної потужності. Це дозволить довести швидкодію кристалів до 600 МГц і від. Тактова частота перших 0,25-мкм процесорів Pentium III становитиме 450 і 500 МГц. До процесора додано нові інструкції. Цей набір команд з кодовою назвою Katmai New Instructions має на меті підвищення продуктивності обробки графіки. Крім того, він допоможе прискорити роботу програм відео, аудіо, розпізнавання мови та інших подібних технологій. У березні 2001 р. Intel випустила процесор Xeon 900 МГц – він став останнім членом сімейства Pentium III. Цей процесор оснащений 2 Мбайт кешем другого рівня, що підвищує його продуктивність.
У листопаді 2000 р. корпорація Intel підтвердила свій намір випустити мікропроцесор Pentium 4 та оголосила про плани переведення масових настільних PC з Pentium III на Pentium 4 вже до кінця 2001 року. Процесор Pentium 4 збудовано на основі мікроархітектури Intel NetBurst. Це перша принципово нова мікроархітектура процесорів для настільних ПК, розроблена фірмою за останні п'ять років, відколи в 1995 році був випущений процесор Pentium Pro з мікроархітектурою P6. В архітектурі NetBurst використовується кілька нових технологій: гіперконвеєрна технологія (Hyper Pipelined Technology) з глибиною конвеєра, що вдвічі перевищує таку в Pentium III; ядро швидкого виконання (Rapid Execution Engine), що підвищує продуктивність при роботі з цілими даними за рахунок роботи на подвійній тактовій частоті в порівнянні з частотою основного ядра; і кеш-пам'ять з відстеженням виконання (Execution Trace Cache), що зберігає вже декодовані команди; таким чином усувається затримка при аналізі ділянок коду, що повторно виконуються.
Процесор Pentium 4 містить 42 млн. транзисторів на кристалі, забезпечений кеш-пам'яттю об'ємом 256 Кбайт і має 144 нові інструкції - так звані потокові SIMD-розширення-2 (SSE2), що прискорюють обробку блоків даних з плаваючою комою. Як основа платформ на базі Pentium 4 застосовується чіпсет Intel 850. Це поки що єдиний набір мікросхем на ринку, розроблений для нового процесора. Чіпсет підтримує двоканальну пам'ять Rambus Direct RAM (RDRAM) з пропускною здатністю 1,6 Гбайт/с по кожному каналу та системну шину з тактовою частотою 400 МГц та пропускною здатністю до 3,2 Гбайт/с. Насправді тактова частота системної шини дорівнює 100 МГц, а один такт виконується чотири операції (аналогічне рішення застосовується в AGP 4x). Intel також представила першу системну плату ATX D850GB для настільних комп'ютерів на базі нового чіпсету. В даний час випускаються 1.4-, 1.5- та 1.7-ГГц версії Pentium 4. Вони виробляються за 0,18-мікронною технологією.
На думку провідних аналітиків, у 2001 році виробники мікрочіпів зроблять перехід 2-ГГц рубежу: нові технології виробництва напівпровідникових мікросхем, включаючи нанесення на полімерну плівку та надмініатюризацію, дозволять виробникам перейти рубіж у 2 ГГц.
Структура мікропроцесора.
Мікропроцесор-це напівпровідниковий пристрій, що складається з однієї або декількох програмно-керованих БІС, що включають всі засоби, необхідні для обробки інформації та управління, і розрахований на спільну роботу з пристроями пам'яті та введення-виведення інформації.
Мікропроцесор складається із трьох основних блоків:
Арифметично-логічного
Блоку регістрів
Пристрої керування
Арифметично-логічний пристрій (АЛП) - виконує всі арифметичні та логічні перетворення даних.
Пристрій управління - електронний блок комп'ютера, що включає роботу пристрою, блоки, електронні елементи і ланцюги в залежності від змісту поточної команди.
Регістр - комірка пам'яті у вигляді сукупності тригерів, призначених для зберігання одного даного в двійковому коді.
Кількість розрядів у регістрі визначається розрядністю мікропроцесора
Регістри загального призначення - утворюють надоперативну та служать для зберігання операндів, що беруть участь у обчисленнях, а також результатів обчислень.
Операндом називаються - вихідні дані, над якими виробляються різні дії арифметичному пристрої.
Регістр команд - служить зберігання команди, виконуваної у час.
Лічильник команд - регістр, що вказує адресу осередку пам'яті, де зберігається наступна команда.
Стек (стекова пам'ять) - сукупність пов'язаних між собою регістрів на зберігання упорядкованих даних. Перший вибирається зі стека це потрапило туди останнім, і навпаки.