Processeurs Intel - comment ils fonctionnent et les principes de base. CPU. Types et différences de processeurs
Il est naturel de considérer les étapes de développement des MP, les réalisations correspondantes, leurs principales caractéristiques architecturales et autres sur la base des MP d'Intel (INTegrated ELectronics). Il existe également un certain nombre de sociétés - AMD (Advanced Micro Devices), Cyrix, Texas Instruments, etc., qui concurrencent plus ou moins avec succès Intel Corporation avec leurs produits.
Les principaux paramètres du MP sont les suivants :
- fréquence d'horloge;
- le degré d'intégration du microcircuit (combien de transistors sont contenus dans la puce);
- la largeur des données internes (le nombre de bits que le MP peut traiter simultanément) ;
- capacité de données externes (le nombre de bits transmis simultanément dans le processus d'échange de données entre la CPU et d'autres éléments);
- mémoire adressable (dépend du nombre de bits d'adresse).
Processeurs Intel
(22 mars 1993). Pentium est  processeur superscalaire avec bus d'adresses 32 bits et bus de données 64 bits, fabriqué en technologie submicronique avec une structure MOS complémentaire, composé de 3,1 millions de transistors (sur une surface de 16,25 cm2). Le processeur comprend les blocs suivants :
processeur superscalaire avec bus d'adresses 32 bits et bus de données 64 bits, fabriqué en technologie submicronique avec une structure MOS complémentaire, composé de 3,1 millions de transistors (sur une surface de 16,25 cm2). Le processeur comprend les blocs suivants :
- Coeur. Le principal appareil exécutif. Les performances du MP à une fréquence d'horloge de 66 MHz sont d'environ 112 millions d'instructions par seconde (MIPS). Par rapport au processeur 80486 DX, les performances ont été multipliées par 5 avec deux pipelines permettant l'exécution simultanée de plusieurs instructions.
- Le prédicteur de branche essaie de deviner la direction de branchement du programme et précharge les informations dans les blocs de prélecture et de décodage.
- Le tampon cible de branche (BTB) fournit une prédiction de branche dynamique. Principe de fonctionnement : « Si la prédiction est correcte, alors l'efficacité augmente, et sinon, le convoyeur doit être complètement abandonné. Selon Intel, la probabilité de prédire correctement les transitions dans les processeurs Pentium est de 75 à 80 %.
- L'unité à virgule flottante effectue un traitement en virgule flottante. Le traitement graphique, les applications multimédias et l'utilisation intensive du PC pour les tâches informatiques nécessitent des performances élevées lors de l'exécution d'opérations en virgule flottante.
- Cache de niveau I. Le processeur dispose de deux banques de mémoire de 8 Ko chacune, la 1ère pour les instructions, la 2ème pour les données plus rapides que les plus volumineuses mémoire externe mémoire cache (cache L2)
- Interface de bus. Transmet un flux de commandes et de données à la CPU, et transfère également les données de la CPU.
Le processeur Pentium a introduit le SMM (System Management Mode). Ce mode permet de mettre en œuvre des fonctions système de très haut niveau, dont la gestion de l'alimentation ou la sécurité, en toute transparence pour l'OS et les applications en cours d'exécution.
Le passage à 60 MHz et plus était une réalisation importante, et les problèmes de refroidissement ont été résolus en conséquence (la surface du processeur chauffe jusqu'à 85 ° C).
(1er novembre 1995). Le Pentium Pro utilise un tampon L2 de 256 Ko (cache) situé dans une puce séparée et monté dans un boîtier CPU pour améliorer les performances. En conséquence, il est devenu possible de décharger efficacement cinq dispositifs exécutifs : deux blocs d'arithmétique d'entiers ; bloc de chargement; bloc d'enregistrement ; FPU (unité à virgule flottante).
Pentium P55 (Pentium MMX), 8 janvier 1997 Pentium MMX - Version Pentium avec caractéristiques supplémentaires... La technologie MMX était censée ajouter/étendre les capacités multimédia des ordinateurs. La technique SIMD (SMD) est mise en œuvre, axée sur les algorithmes et les types de données typiques pour Logiciel multimédia. Le MMX a été annoncé en janvier 1997, cadencé à 166 et 200 MHz, et la version 233 MHz est apparue en juin de la même année. Processus technologique 0,35 microns, 4,5 millions de transistors.
(7 mai 1997). Le processeur est une modification du Pentium Pro avec prise en charge des capacités MMX. Les premiers PII sont annoncés comme des processeurs pour ordinateurs de bureau haut de gamme. La conception du boîtier a été modifiée - la plaquette de silicium avec contacts a été remplacée par une cartouche, la fréquence du bus et la fréquence d'horloge ont été augmentées et les commandes MMX ont été étendues.
Il existe également un modèle pour ordinateurs portables - Pentium II PE et pour postes de travail - Pentium II Heon 450 MHz.
Céleron(15 avril 1998). Celeron est un P2 simplifié pour les ordinateurs bon marché. Les principales différences entre ces processeurs résident dans la taille du cache L2 et la fréquence du bus. Tous ces processeurs sont fabriqués en technologie 0,25 micron et comportent de 7,5 à 19 millions de transistors.
(26 février 1999). P3 est l'un des plus productifs Processeurs Intel, mais dans sa conception, il n'est pas très différent de P2, la fréquence a été augmentée et environ 70 nouvelles commandes ont été ajoutées. En octobre 1999, une version pour ordinateurs portables, fabriqué selon la technologie 0,18 micron avec des fréquences de 400 à 733 MHz. Pour les postes de travail et les serveurs, il y a RZ Heon, axé sur la logique système GX avec un cache L2 de 512 Ko, 1 ou 2 Mo. Le processus technologique est de 0,25 micron, le bus système fonctionne à une fréquence de 100 MHz, il existe une version 0,18 micron avec une fréquence de bus de 133 MHz, ainsi que des modèles pour 600, 666 et 733 MHz.
(Willamette, 2000; Northwood, 2002). Naturellement, tôt ou tard, l'architecture de PIII devait devenir obsolète. Le fait est qu'ayant atteint la fréquence de 1 GHz, Intel a rencontré des problèmes pour augmenter encore la fréquence de ses processeurs : le Pentium III à 1,13 GHz a dû être retiré en raison de son instabilité. Une nouvelle augmentation de la fréquence des processeurs existants entraîne une augmentation toujours plus faible de leurs performances. Le problème est que les latences (retards) qui surviennent lors de l'accès à certains nœuds de processeur sont déjà trop élevées dans P6.
Ainsi, le Pentium IV est né - il est basé sur une architecture appelée architecture Intel NetBurst. Avec ce nom, Intel a tenu à souligner que l'objectif principal du nouveau processeur est d'accélérer l'exécution des tâches de streaming de données directement liées aux technologies Internet et multimédia en plein essor.
L'architecture NetBurst est basée sur plusieurs innovations, ensemble pour atteindre l'objectif ultime de fournir une marge de performance et une évolutivité future pour la famille de processeurs Pentium IV. Les technologies clés comprennent :
- Technologie Hyper Pipelined - Le pipeline Pentium IV comprend 20 étages ;
- Exécution dynamique avancée - prédiction de transition améliorée et exécution dans le désordre ;
- Trace Cache - un cache spécial est utilisé pour mettre en cache les instructions décodées dans le Pentium IV ;
- Moteur d'exécution rapide - L'ALU du Pentium IV fonctionne à deux fois la fréquence du processeur lui-même ;
- SSE2 - ensemble étendu de commandes pour le traitement des données en continu ;
- Le bus système 400 MHz est un nouveau bus système.
Pentium IV Prescott(février 2004). Début février 2004, Intel a annoncé quatre nouveaux processeurs Pentium IV (2,8, 3,0, 3,2 et 3,4 GHz) basés sur le noyau Prescott, qui comprend un certain nombre d'innovations. Parallèlement à la sortie de quatre nouveaux processeurs, Intel a présenté le processeur Pentium IV 3.4 EE (Extreme Edition) basé sur le noyau Northwood et doté de 2 Mo de cache L3, ainsi qu'une version simplifiée du Pentium IV 2.8 A basée sur le Prescott noyau avec une fréquence de bus limitée ( 533 MHz).
Les nouveaux processeurs ont le même design que ceux basés sur le noyau Northwood, donc, pour les distinguer, Intel a introduit un nouvel indice dans le nom du processeur - E. Par exemple, le processeur Pentium IV 3.2 C est basé sur le noyau Northwood , prend en charge le bus 800 MHz et la technologie HT, tandis que le Pentium IV 3.2 E est basé sur le noyau Prescott et prend également en charge le bus 800 MHz et la technologie HT.
Prescott est fabriqué à l'aide de la technologie 90 nm, ce qui a permis de réduire la surface du cristal lui-même, tandis que le nombre total de transistors a plus que doublé. Alors que le noyau Northwood mesure 145 mm2 et contient 55 millions de transistors, le noyau Prescott mesure 122 mm2 et contient 125 millions de transistors.
Processeurs Cyrix
Dévoilé en octobre 1995, 6x86 était  le premier processeur compatible Pentium pour permettre la pénétration du marché et la collaboration avec la division IBM Microelectronics. L'adoption du 6x86 a d'abord été lente car Cyrix fixait des prix trop élevés, pensant à tort que puisque l'efficacité du processeur était comparable à celle d'Intel, son prix pourrait être le même. Dès que Cyrix a redéfini sa position, la puce a commencé à exercer une influence significative sur sa part de marché en tant qu'alternative haute performance à la série Pentium.
le premier processeur compatible Pentium pour permettre la pénétration du marché et la collaboration avec la division IBM Microelectronics. L'adoption du 6x86 a d'abord été lente car Cyrix fixait des prix trop élevés, pensant à tort que puisque l'efficacité du processeur était comparable à celle d'Intel, son prix pourrait être le même. Dès que Cyrix a redéfini sa position, la puce a commencé à exercer une influence significative sur sa part de marché en tant qu'alternative haute performance à la série Pentium.
À partir du 6x86, les processeurs Cyrix étaient capables de niveaux de performances équivalents à la puce Pentium, mais à une fréquence inférieure. Le Processor Performance Rating - P-rating est utilisé pour évaluer les performances (la désignation P100 +, par exemple, symbolise les performances équivalentes à un Pentium avec une fréquence de 100 MHz). Les processeurs Cyrix (comme AMD) fonctionnent traditionnellement à des fréquences inférieures à la valeur numérique de leur P-rating, sans dégradation notable des performances. Par exemple, P133 + (P-rating) fonctionne à 110 MHz, tandis que P150 + et P166 + fonctionnent respectivement à 120 et 133 MHz.
La supériorité du 6x86 provenait des améliorations de l'architecture de la puce, qui ont permis au 6x86 d'accéder à son cache interne et de s'enregistrer en un cycle d'horloge (le Pentium utilise généralement deux cycles ou plus pour accéder au cache). De plus, le cache principal 6x86 a été fusionné, plutôt que d'inclure deux sections 8K distinctes pour les instructions et les données. Ce modèle combiné était capable de stocker des instructions et des données à tous égards, offrant un taux de réussite du cache de 90 %. Le processeur contient 3,5 millions de transistors, fabriqués à l'origine avec une technologie à cinq couches de 0,5 micron. Interface - Socket 7. Tension de base - 3,3 V. Les caractéristiques du 6x86 sont similaires à celles du Pentium. Cependant, il inclut également de nouvelles fonctionnalités : suppression des dépendances de données, prédiction de branchement et exécution d'instructions dans le désordre (la possibilité pour des instructions plus rapides de quitter la file d'attente du pipeline sans perturber le processus d'exécution du programme). Tout cela augmente le niveau de performance du 6x86, contrairement au Pentium avec la même fréquence.
Cependant, les processeurs 6x86 étaient confrontés à de nombreux problèmes, notamment une surchauffe, de mauvaises performances en virgule flottante et une incompatibilité avec Windows NT. Cela a nui au succès du processeur, et la concurrence avec le Pentium a été de courte durée et s'est terminée avec le lancement de l'Intel Pentium MMX.
Cyrix MediaGX... L'introduction du processeur MediaGX en février 1997 a défini la première nouvelle architecture de PC en une décennie et a défini un nouveau segment de marché - le "PC de base" à faible coût. La croissance de ce marché a été explosive et la technologie des processeurs Cyrix et l'innovation au niveau du système ont été un élément clé.
Plus le nombre de processus traités directement sur le processeur central du PC est élevé, plus les performances globales du système sont élevées. Dans les conceptions informatiques traditionnelles, l'unité centrale de traitement traite les données à une fréquence en mégahertz, tandis que le bus qui déplace les données vers et depuis d'autres composants ne fonctionne qu'à la moitié de la vitesse ou moins. Cela signifie qu'il faut plus de temps pour que les données se déplacent vers (et depuis) le processeur. Cyrix a supprimé ce goulot d'étranglement avec l'introduction de la technologie MediaGX. L'architecture MediaGX intègre les graphiques, l'audio, le PCI et le gestionnaire de mémoire dans un bloc processeur, éliminant ainsi les conflits potentiels du système et les problèmes de configuration de l'utilisateur final. Il se compose de deux puces - le processeur MediaGX et le coprocesseur MediaGX Cx5510. Le processeur utilise un socket spécial qui nécessite une carte mère spécialement conçue. MediaGX est un processeur compatible x86 qui connecte directement le bus PCI et la DRAM EDO via un bus de données dédié 64 bits. Cyrix affirme que la technique de compression utilisée sur le bus de données élimine le besoin de cache L2. Il y a un cache L1 combiné (16 Ko) sur le processeur central - de la même taille que sur une puce Pentium standard. Les graphiques sont traités directement par un pipeline spécial sur le processeur et le contrôleur de moniteur se trouve également sur le processeur principal. Il n'y a pas de mémoire vidéo, pas de mémoire tampon d'images stockée dans la mémoire principale (architecture traditionnelle de mémoire unifiée - UMA), à la place, il utilise sa propre technologie de compression d'affichage Cyrix (DCT). Les données VGA sont gérées par le matériel informatique, mais les registres VGA sont contrôlés par les programmes Cyrix - Virtual System Architecture (VSA). La puce compagnon MediaGX Cx5510 contient un contrôleur audio et utilise également le logiciel VSA pour émuler les capacités des cartes son standard. Cette puce connecte le processeur MediaGX via le bus PCI au bus ISA, ainsi qu'aux ports IDE et I/O, c'est-à-dire qu'elle remplit les fonctions traditionnelles d'un chipset.
La réponse de Cyrix à Technologie Intel MMX était 6x86MX, lancé à la mi-1997, peu de temps avant l'acquisition de la société par National Semiconductor. L'entreprise est restée fidèle au format Socket 7 pour sa nouvelle puce, qui a maintenu les coûts des fabricants de systèmes et, finalement, des consommateurs au niveau requis, prolongeant la durée de vie de la puce et des cartes mères existantes.
L'architecture de la nouvelle puce est restée essentiellement la même que celle de son prédécesseur, avec l'ajout d'instructions MMX, quelques améliorations au Floating Point Unit, un grand cache universel (64 Ko) de premier niveau et une unité de gestion de mémoire étendue.
Le processeur 6x86MX a été bien reçu sur le marché, car le 6x86MX / PR233 (cadencé à 187 MHz) était plus rapide que le Pentium II (233 MHz) et AMD KB. Le MX a également été le premier processeur phare à pouvoir fonctionner sur un bus frontal de 75 MHz, offrant des avantages évidents en matière de bande passante et des performances globales accrues. Cependant, le 6x86MX fonctionnait en virgule flottante bien moins bien que ses concurrents, ce qui affectait négativement le traitement des graphiques 3D.
Cyrix MII... Le processeur МII est un développement du 6x86МХ fonctionnant à des fréquences plus élevées. À l'été 1998, les processeurs de 0,25 micron MII-300 et MII-333 étaient fabriqués dans les nouvelles installations de production de National Semiconductor en pcs. Le Maine visait à développer la technologie 0,22 micron, se dirigeant vers son objectif ultime de 0,18 micron en 1999.
Processeurs AMD
Micro-appareils avancés de longue date,  comme Cyrix, il a produit les unités centrales de traitement 286, 386 et 486 basées sur des conceptions Intel. Le K5 était le premier processeur x86 construit de manière indépendante pour lequel AMD avait de grands espoirs. Cependant, le rachat par AMD d'un concurrent californien au printemps 1996 semble avoir créé une opportunité de mieux préparer sa prochaine attaque contre Intel. Le K6 a commencé sa vie sous le nom de Nx686, renommé après l'acquisition de NextGen. La série KB de processeurs compatibles MMX a été lancée à la mi-1997, quelques semaines avant le Cyrix 6x86MX, et a immédiatement été saluée par la critique.
comme Cyrix, il a produit les unités centrales de traitement 286, 386 et 486 basées sur des conceptions Intel. Le K5 était le premier processeur x86 construit de manière indépendante pour lequel AMD avait de grands espoirs. Cependant, le rachat par AMD d'un concurrent californien au printemps 1996 semble avoir créé une opportunité de mieux préparer sa prochaine attaque contre Intel. Le K6 a commencé sa vie sous le nom de Nx686, renommé après l'acquisition de NextGen. La série KB de processeurs compatibles MMX a été lancée à la mi-1997, quelques semaines avant le Cyrix 6x86MX, et a immédiatement été saluée par la critique.
Le K6 était presque 20 % plus petit que le Pentium Pro et contenait en même temps 3,3 millions de transistors de plus (8,8 contre 5,5 millions). Le processeur K6 prend en charge la technologie MMX d'Intel, y compris 57 nouvelles instructions x86 conçues pour le développement de logiciels multimédias. Le niveau de performance du K6 est très similaire au Pentium Pro des fréquences correspondantes avec son cache L2 maximum de 512 Ko. La similitude avec la puce Cyrix MX (mais dans une moindre mesure) - opération en virgule flottante - était une zone de faiblesse relative par rapport au Pentium Pro ou Pentium II.
AMD K6-2... Les processeurs AMD K6-2 avec 9,3 millions de transistors ont été fabriqués en utilisant la technologie AMD 0,25 micron. Le processeur était conditionné dans un boîtier CPGA (Ceramic Pin Grid Array) compatible Super7 à 100 MHz. Le K6-2 comprend la microarchitecture R1SC86 innovante et efficace, un grand cache L1 de 64 Ko (cache de données à double port 32 Ko, cache d'instructions de 32 Ko avec cache de pré-déchiffrement de 20 Ko en option) et un module à virgule flottante amélioré.
Ses performances effectives étaient estimées à 300 MHz lors de son lancement à la mi-1998, et au début de 1999, le processeur le plus rapide disponible était la version 450 MHz. Les capacités 3D du K6-2 étaient différentes. réalisation importante... Elles ont été incorporées dans la technologie AMD 3DNow!, sous la forme d'un nouvel ensemble de 21 instructions complétant les instructions MMX standard déjà incluses dans l'architecture KB, ce qui a accéléré le traitement des applications 3D. Annoncé début 2001, le processeur K6-2 (550 MHz) devait être le processeur le plus rapide et le dernier d'AMD pour le facteur de forme Socket 7 vieillissant, remplacé plus tard par le processeur Duron sur le marché prometteur des ordinateurs de bureau.
AMD K6-III... En février 1999, AMD annonce le lancement d'un lot de processeurs AMD K6-III 400 MHz, nom de code narptooth, et teste la version 450 MHz. Caractéristique clé Ce nouveau processeur était un développement innovant - Cache à trois niveaux.
Traditionnellement, les processeurs PC utilisent deux niveaux de cache :
- le cache de premier niveau (L1), qui est généralement situé sur la puce ;
- un cache de deuxième niveau (L2) qui peut être situé hors du processeur, sur la carte mère ou le slot, ou directement sur la puce du processeur.
Une règle générale lors de la conception d'un sous-système de cache est que plus le cache est grand et rapide, meilleures sont les performances (le cœur du processeur peut accéder aux instructions et aux données plus rapidement).
Reconnaissant les avantages d'un cache large et rapide pour répondre aux demandes d'applications de performances PC de plus en plus exigeantes, le cache à trois niveaux d'AMD a introduit des innovations architecturales de cache conçues pour améliorer les performances sur les PC basés sur Super7 :
- Cache K2 interne (256 Ko) fonctionnant à pleine vitesse du processeur AMD-K6-III et complétant le cache L1 de 64 Ko qui était standard dans la famille de processeurs AMD-K6 ;
- cache interne multiport, permettant la lecture et l'écriture simultanées de 64 bits dans les caches L1 et L2 ;
- bus de processeur principal (100 MHz), fournissant une connexion à la mémoire cache résidente sur carte mère extensible de 512 à 2048 Ko.
La conception du cache interne multiport du processeur AMD-K6-III a permis à la fois au cache L1 (64 Ko) et au cache L2 (256 Ko) d'effectuer simultanément des opérations de lecture et d'écriture 64 bits par cycle de processeur. En plus de cette conception de cache multiport, le cœur du processeur AMD-K6-III était capable d'accéder simultanément aux caches L1 et L2, augmentant ainsi la bande passante globale du processeur.
AMD a affirmé qu'avec un cache L3 entièrement réglé, le K6-III avait un avantage de taille de cache de 435% par rapport au Pentium III et donc un avantage significatif en termes de performances. En fin de compte, cependant, il était destiné à vivre une vie relativement courte dans le domaine des ordinateurs de bureau, étant poussé à l'arrière-plan par le processeur AMD Athlon plus efficace quelques mois plus tard.
Sortie Processeur Athlon l'été 1999 a été le coup le plus réussi d'AMD. Cela les a rendus fiers de ce qu'ils ont produit  le premier processeur de septième génération (il présentait suffisamment de différences architecturales radicales par rapport aux Pentium II / III et K6-III pour mériter le nom de processeur de prochaine génération), et cela signifiait également qu'ils arrachaient le leadership technologique à Intel.
le premier processeur de septième génération (il présentait suffisamment de différences architecturales radicales par rapport aux Pentium II / III et K6-III pour mériter le nom de processeur de prochaine génération), et cela signifiait également qu'ils arrachaient le leadership technologique à Intel.
Le mot grec ancien Athlon signifie trophée ou jeux. L'Athlon est le processeur avec lequel AMD espérait accroître sa réelle présence concurrentielle dans le secteur des entreprises, au-delà de son avantage traditionnel sur les marchés des jeux grand public et 3D. Le noyau est placé sur une puce de 102 mm2 et contient environ 22 millions de transistors.
Duron.À la mi-2000, le processeur Duron est sorti pour la maison et le bureau. Le nom vient du latin "durare" - "éternel", "à long terme". Les mémoires cache L1 (128 Ko) et L2 (64 Ko) sont situées sur la carte. Le bus système principal fonctionne à 200 MHz. Technologie 3DNow! améliorée prise en charge Technologie 0,18 micron, fréquences 600, 650 et 700 MHz. Interface - Prise A 462 broches.
Athlon 64.À l'automne 2003, deux  Modèles de processeurs AMD - Athlon 64 pour le grand public et Athlon 64 FX-51 pour le multimédia et candidatures professionnelles(architecture K8). Dans le système de notation AMD Athlon 64 a une fréquence équivalente de 3200+, avec une fréquence physique de 2 GHz, FX-51 est légèrement plus élevée - 2,2 GHz. Une innovation architecturale importante est l'intégration du concentrateur de contrôleur de mémoire système (MCH) directement dans le processeur. Cela signifie que la carte mère (plus précisément, le chipset) ne devrait plus contenir de puce de contrôleur Northbridge distincte. Il supprime également le besoin d'un bus système principal (FSB), ainsi que toutes les latences qu'il introduit. Au lieu de cela, le K8 utilise HyperTransport (jusqu'à 6,4 Go / s de bus système) pour se connecter à Southbridge, aux contrôleurs AGP ou à d'autres processeurs. Cela permet à la mémoire de fonctionner à pleine fréquence du processeur, réduit la latence (latence) et améliore l'efficacité de la mémoire. Le processeur convient aux applications 32 et 64 bits.
Modèles de processeurs AMD - Athlon 64 pour le grand public et Athlon 64 FX-51 pour le multimédia et candidatures professionnelles(architecture K8). Dans le système de notation AMD Athlon 64 a une fréquence équivalente de 3200+, avec une fréquence physique de 2 GHz, FX-51 est légèrement plus élevée - 2,2 GHz. Une innovation architecturale importante est l'intégration du concentrateur de contrôleur de mémoire système (MCH) directement dans le processeur. Cela signifie que la carte mère (plus précisément, le chipset) ne devrait plus contenir de puce de contrôleur Northbridge distincte. Il supprime également le besoin d'un bus système principal (FSB), ainsi que toutes les latences qu'il introduit. Au lieu de cela, le K8 utilise HyperTransport (jusqu'à 6,4 Go / s de bus système) pour se connecter à Southbridge, aux contrôleurs AGP ou à d'autres processeurs. Cela permet à la mémoire de fonctionner à pleine fréquence du processeur, réduit la latence (latence) et améliore l'efficacité de la mémoire. Le processeur convient aux applications 32 et 64 bits.
En même temps qu'AMD annonçait l'Athlon 64, Microsoft annonçait une version bêta de Windows XP 64-Bit Edition pour les processeurs 64 bits, qui peut naturellement fonctionner sur les deux Processeurs AMD Athlon 64 (PC) et AMD Opteron (postes de travail).
Travailler avec la liste de prix
Lors du choix d'un microprocesseur, il est nécessaire de prendre en compte certaines caractéristiques, par exemple
- Processeurs Intel.
- Processeurs AMD et Cyrix.
- Versions modernes des processeurs Intel et AMD (contrairement aux plus anciens).
- Fabricants alternatifs de microprocesseurs.
- Décrire les composants de la liste de prix
- AMD ATHLON-64 X2 6000+ BOX (ADV6000) 1Mb / 2000MHz Socket AM2
- AMD ATHLON-64 2800+ (ADA2800) 512K / 800MHz Socket-754
- Intel Core 2 Duo E6550 2,33 GHz / 4 Mo / 1333 MHz 775-LGA
- Intel Pentium 4 1.5GHz / 256K / 400MHz 423-PGA
Le processeur remplit les fonctions suivantes :
1) calculer les adresses des commandes et des opérandes ;
2) récupérer et décoder les commandes de la RAM ;
3) récupérer les données de la RAM, de la mémoire du microprocesseur et des registres des adaptateurs d'appareils externes ;
4) recevoir et traiter des demandes et des commandes provenant d'appareils externes ;
5) traitement et enregistrement des données dans la RAM, les registres de microprocesseur et les registres d'adaptateurs de périphériques externes ;
6) génération de signaux de commande pour tous les autres nœuds et blocs de l'ordinateur ;
7) passez à la commande suivante.
Selon / 4 /, les principaux paramètres des microprocesseurs sont : mordant, fréquence d'horloge de fonctionnement, taille du cache, composition d'instructions, constructif.
1) Profondeur de bits des registres internes- le nombre de bits que le processeur est capable de traiter à la fois. Largeur du bus de données détermine le nombre de bits sur lesquels des opérations peuvent être effectuées simultanément. Largeur du bus d'adresses détermine la quantité de mémoire (espace d'adressage) avec laquelle le processeur peut travailler. Espace d'adressage C'est le nombre maximum de cellules mémoire qui peuvent être directement adressées par le microprocesseur.
2) Fréquence d'horloge de travail (MHz) détermine en grande partie la vitesse du processeur, puisque chaque commande est exécutée dans un certain nombre de cycles d'horloge. Plus le cycle d'horloge de la machine est court, plus les performances du processeur sont élevées. La vitesse de l'ordinateur dépend également de la fréquence d'horloge du bus de la carte système avec lequel le processeur fonctionne.
3) Mémoire cache installé sur la carte microprocesseur a deux niveaux :
3.1) L 1 - mémoire du premier niveau, située à l'intérieur du microcircuit principal (noyau) du processeur et fonctionnant toujours à la pleine fréquence du processeur (apparu pour la première fois dans les microprocesseurs Intel 386SLC et 486).
3.2) L 2 - mémoire de second niveau, un cristal situé sur la carte du microprocesseur et connecté au coeur par un bus interne (introduit pour la première fois dans les microprocesseurs Pentium II). Cette mémoire peut fonctionner à pleine ou à mi-fréquence du processeur.
4) Composition des instructions- liste, type et type de commandes exécutées automatiquement par le microprocesseur. Spécifie directement les procédures qui peuvent être exécutées sur les données et les catégories de données sur lesquelles ces procédures peuvent être exécutées. Un changement significatif dans la composition des instructions s'est produit dans les microprocesseurs Intel 80386 (cette composition est considérée comme la composition de base), Pentium MMX, Pentium III, Pentium 4.
5) Constructif fait référence aux connecteurs physiques dans lesquels le microprocesseur est installé. Différents connecteurs ont une conception différente (connecteur à fente - Slot, connecteur-prise - Soket), un nombre de contacts différent.
Les processeurs sont classés selon différents critères. Conformément à / 4, 13 /, les principales caractéristiques suivantes peuvent être distinguées :
1) Par rendez-vous les microprocesseurs sont divisés en universel et spécialisé... Les premiers sont conçus pour résoudre un large éventail de problèmes ; l'universalité algorithmique est incorporée dans le système de commande. Ainsi, les performances du processeur dépendent faiblement des spécificités des tâches à résoudre. Les processeurs spécialisés sont conçus pour résoudre un certain nombre de tâches ou même une seule tâche, ils ont un ensemble limité d'instructions. Parmi eux se démarquer processeurs de données, processeurs mathématiques et microcontrôleurs.
2) Par le nombre de programmes en cours d'exécution les processeurs sont classés en programme unique(le passage à l'exécution du programme suivant n'a lieu qu'après la fin du programme en cours) et multi-programme(plusieurs programmes fonctionnent en même temps).
3) Par de construction la fonction se distingue par des microprocesseurs bit fixe(ont une capacité en bits strictement définie) et des microprocesseurs avec une profondeur de bits incrémentielle(autoriser les sections à augmenter le nombre de chiffres).
4) Par le nombre de LSI (VLSI) dans l'ensemble de microprocesseurs peut être distingué puce unique, multipuce et sectionnel multipuce processeurs. Dans le premier cas, toutes les parties matérielles du processeur sont implémentées comme un seul LSI (VLSI) ; les capacités de ces processeurs sont limitées par les ressources du cristal et du boîtier. Les processeurs multipuces sont obtenus en divisant la structure logique du processeur en parties fonctionnellement complètes, dont chacune est implémentée sous la forme d'un LSI ou d'un VLSI. Dans ce dernier cas, les parties fonctionnellement complètes de la structure logique du processeur sont divisées en sections, qui sont mises en œuvre sous la forme d'un LSI.
5) Par bitness des informations traitées les microprocesseurs peuvent être 4, 8, 12, 16, 24, 32 et 64 bits. En pratique, les processeurs 32 bits sont les plus courants ; Les processeurs 64 bits sont de plus en plus utilisés.
6) Par type Technologie de fabrication LSI (VLSI) les microprocesseurs sont divisés en deux groupes : les processeurs basés sur des LSI fabriqués selon technologie unipolaire, et les processeurs basés sur LSI fabriqués par technologie bipolaire... Représentants du premier groupe : p-canaliser (p-MOS), m-canaliser (m-MOS), gratuit (CMOS) BIS. (MOS - Conducteur d'oxyde métallique). Le deuxième groupe comprend les LSI basés sur logique transistor-transistor (TTL), logique à couplage d'émetteur (ECL) et logique d'injection intégrale (ET 2 L)... Le type de technologie de fabrication LSI détermine en grande partie le degré d'intégration des microcircuits, la vitesse, la consommation électrique, l'immunité au bruit et le coût des processeurs. Par la complexité de ces caractéristiques, on peut privilégier les microprocesseurs réalisés à l'aide des technologies n-MOS et CMOS, qui offrent une densité de compactage élevée, une vitesse élevée et un coût relativement faible. ESL offre les performances de processeur les plus rapides, mais une faible densité d'emballage et une consommation d'énergie élevée. La technologie I 2 L donne les caractéristiques moyennes des microprocesseurs.
7) Par la nature du système de commande allouer processeurs de jeux d'instructions complets ou SCRC-processeurs(Commande de jeu d'instructions complexe), processeurs à jeux d'instructions réduits ou RISC-processeurs(Commande d'ensemble d'instructions réduite), traitement de texte ultra-large ou VLIW-processeurs(Très long mot d'instruction). Les processeurs CISC ont un grand nombre d'instructions multi-formats, ce qui permet d'utiliser des algorithmes efficaces pour résoudre des problèmes, mais en même temps complique le circuit du processeur et, en général, n'offre pas des performances maximales. L'architecture CISC est inhérente aux processeurs classiques. Les processeurs RISC contiennent un ensemble d'instructions simples que l'on trouve le plus souvent dans les programmes. S'il est nécessaire d'exécuter des commandes plus complexes dans le microprocesseur, elles sont automatiquement assemblées à partir de commandes simples. Tout commandes simples sont de la même taille et prennent un cycle machine à exécuter (l'instruction CISC la plus courte prend généralement quatre cycles à exécuter). Les processeurs RISC 64 bits modernes sont produits par de nombreuses entreprises : Apple (PowerPC), IBM (PPC) etc. Dans les processeurs VLIW, une instruction contient plusieurs opérations qui doivent être exécutées en parallèle. La tâche de répartition du travail entre plusieurs appareils informatiques du processeur est résolue lors de la compilation du programme. Cette approche a permis de réduire la taille des processeurs et la consommation d'énergie. Des exemples de processeurs VLIW sont l'Itanium d'Intel, le McKinley de Hewlett-Packard et d'autres.
8) Par le nombre et le mode d'utilisation des registres internes distinguer rechargeable, multi-batterie et empiler processeurs. Processeurs de batterie Sont des processeurs avec un seul registre de résultat. Leur caractéristique distinctive est la relative simplicité de la mise en œuvre matérielle, ainsi que le format de commande simplifié (sera discuté dans la prochaine leçon). Dans les commandes, l'adresse de l'opérande dans l'accumulateur n'est pas indiquée, et seul le deuxième opérande est adressé. Les inconvénients de tels processeurs sont la nécessité de précharger l'opérande dans l'accumulateur avant d'effectuer l'opération et l'impossibilité d'écrire directement le résultat de l'exécution de la commande dans une cellule mémoire ou un registre arbitraire. V multi-batterie registres, qui constituent la majorité des processeurs modernes, la fonction des registres de résultats peut être assurée par n'importe quel registre ou cellule mémoire à usage général. Dans les commandes, les deux opérandes sont spécifiés explicitement, et le résultat d'une opération est le plus souvent placé à la place de l'un des opérandes. V empiler les processeurs utilisent généralement une grande pile matérielle et une pile externe supplémentaire en mémoire (en cas de manque de matériel). En raison de la disposition spéciale des opérandes dans la pile, le traitement de l'information peut être effectué par des instructions non adressées, ce qui améliore les performances du processeur et économise de la mémoire. De telles instructions extraient un ou deux opérandes de la pile, effectuent une opération arithmétique ou logique appropriée dessus et poussent le résultat vers le haut de la pile. L'inconvénient est la nécessité d'une préparation préalable des données à l'aide de commandes d'adresse.
L'histoire du développement des processeurs et de leurs caractéristiques comparatives peut être trouvée plus en détail dans / 4, 13 /. Examinons ensuite la structure physique et fonctionnelle du processeur.
Organisation physique et fonctionnelle du CPU (par exemple, CPU Intelligence 8086). SHI.
La structure physique du processeur est assez complexe. Conformément à / 4 /, le cœur du processeur contient les principaux modules de commande et d'exécution - des unités permettant d'effectuer des opérations sur des données entières. Les circuits de contrôle locaux comprennent : un bloc à virgule flottante, un module de prédiction de branchement, des registres de mémoire de microprocesseur, des registres de cache de niveau 1, une interface de bus et bien plus encore.
Remarque : Le noyau logique est compris comme le schéma selon lequel le processeur est fabriqué. Physiquement, le noyau est un cristal sur lequel le schéma électrique du processeur est implémenté à l'aide d'éléments logiques.
Dans le cas le plus général, la structure fonctionnelle du processeur peut être représentée comme une composition, selon une source / 4, 5 /, en deux parties : appareil de commande (OU) et interface de bus (SHI), selon d'autres / 2 /, - trois blocs : unité opérant (À PROPOS), Unité de contrôle (UB) et bloc d'interface (IB). Les écarts insignifiants existants dans le nombre et le nom des blocs ne violent en aucun cas le nombre et les principes de fonctionnement des composants du processeur. Par conséquent, nous considérerons la première option (plus visuelle) de la source / 4 /.
Une structure de processeur typique simplifiée est illustrée à la figure 4.1.
OU contient une unité de contrôle (UU), une unité arithmétique et logique (ALU), un registre d'indicateurs, des registres à usage général (RON), des registres de pointeurs, des registres d'index. SHI contient des registres d'adresses, un bloc de registres (tampon) de commandes, une unité de génération d'adresses, des circuits de contrôle de bus et de ports. Les deux parties du microprocesseur fonctionnent en parallèle et le SHI fonctionne plus rapidement que l'ampli-op. Examinons de plus près ces blocs de processeur.
SHI est destiné à la communication et à la coordination du microprocesseur avec le bus système de l'ordinateur, ainsi qu'à la réception, à l'analyse préliminaire des commandes du programme en cours d'exécution et à la formation des adresses complètes des opérandes et des commandes.
Segmentaire(adresse) s'inscrit avec nœud de la formation de l'adresse implémenter la segmentation de la mémoire. Les commandes et les données sont stockées dans des cellules, et leur emplacement en mémoire est déterminé par les adresses des cellules correspondantes. Étant donné que les instructions et les données au niveau du code sont indiscernables les unes des autres, pour distinguer les instructions et les données, elles sont placées dans différentes zones de mémoire - segments. Segment est une zone de mémoire rectangulaire, caractérisée par une adresse de début et une longueur. Adresse de début (adresse de début de segment) Numéro (adresse) de la cellule mémoire à partir de laquelle le segment commence. Longueur des segments – c'est le nombre de cellules mémoire qu'il contient. Les segments peuvent être de différentes longueurs. Toutes les cellules situées à l'intérieur du segment sont renumérotées à partir de zéro. Les cellules d'un segment sont adressées par rapport au début du segment ; l'adresse de la cellule dans le segment est appelée déplacement ou adresse effective -EA(par rapport à l'adresse de début du segment). Le segment actuel peut être spécifié en chargeant le registre de segment approprié :
1) CS (Code Segment) - définit le début du segment de code courant, dans lequel se trouvent les commandes du programme. La commande est récupérée en utilisant le contenu du registre comme adresse effective IP (Instruction Aiguille) , et comme adresse de segment - le contenu de CS. C'est le registre IP qui stocke l'offset de l'adresse de la commande de programme en cours.
2) DS (Données Segment) - définit le début du segment de données actuel. Les références aux données (à quelques exceptions près) sont faites par rapport au contenu de ce registre.
3) SS (Empiler Segment) - définit le début du segment courant de la pile. Typiquement, toutes les adresses de données associées à la pile sont relatives au contenu de ce registre.
4) ES (Élargi Segment) - définit le début du segment courant supplémentaire, qui est généralement considéré comme un segment de données auxiliaire (pour les transferts inter-segments).
Nœud de génération d'adresses et registre de commandes fonctionnellement font partie de l'UU et ont été discutés ci-dessus.
Lors de l'adressage des périphériques d'entrée-sortie (IO), les registres de segment ne sont pas utilisés. Le processeur interagit avec eux via un espace d'adressage spécial - les ports. Chaque port a un numéro qui correspond à l'adresse de l'appareil qui lui est connecté. Le port de l'appareil correspond à l'équipement d'interface et à deux registres - pour l'échange de données et d'informations de contrôle. Circuit de contrôle de bus et de port remplit les fonctions suivantes :
1) formation de l'adresse du port et des informations de contrôle correspondantes ;
2) recevoir des informations de contrôle du port, des informations sur l'état de préparation du port et son état ;
3) organisation d'un canal de bout en bout dans l'interface système pour la transmission de données entre le port I/O et le processeur.
Le schéma de contrôle des bus et des ports utilise le bus système pour communiquer avec les ports : le bus d'adresses, le bus de données et le bus d'instructions.
Organisation physique et fonctionnelle du processeur (par exemple, processeur Intel 8086). OU.
En général, l'unité d'organisation effectue les opérations spécifiées par les commandes et génère des adresses effectives.
Euh génère des signaux de contrôle à tous les blocs de l'ordinateur. Les blocs fonctionnels suivants peuvent être distingués dans le cadre de la CU :
1) registre de commandes- un registre de stockage qui stocke le code de commande : le code opération et les adresses des opérandes (situé dans la partie interface du processeur) ;
2) décodeur d'opération- un bloc logique qui, conformément au code opération issu du registre de commandes, sélectionne l'une des nombreuses sorties dont il dispose ;
3) micrologiciel de la mémoire morte (ROM) stocke des impulsions de commande pour effectuer des procédures de traitement de l'information dans les blocs de l'ordinateur ; une impulsion à travers le fil sélectionné par le décodeur de fonctionnement lit la séquence requise de signaux de commande à partir de la ROM du micrologiciel ;
4) nœud de génération d'adresses(situé dans le SHI) - un dispositif de calcul de l'adresse complète d'une cellule mémoire (registre) en fonction des détails provenant de la mémoire du microprocesseur ou du registre de commande ;
5) bus de code de données, d'adresses et d'instructions- une partie du bus d'interface interne du processeur.
Ainsi, l'unité de commande génère des signaux de commande pour que le processeur exécute ses fonctions décrites ci-dessus.
Figure 4.1 - Structure de processeur typique simplifiée
ALU est destiné à effectuer des opérations arithmétiques et logiques de transformation de l'information. Fonctionnellement, dans sa forme la plus simple, l'ALU se compose des éléments suivants :
1) additionneur effectue la procédure d'ajout de codes binaires, a une longueur de mot double (32 bits);
2) registres- des cellules mémoires rapides de différentes longueurs : le registre 1 a 32 bits, le registre 2 - 16 bits ; lors de l'addition, le premier terme est placé dans le registre 1, puis le résultat, dans le registre 2 - le deuxième terme ;
3) schéma de contrôle reçoit des signaux de commande de l'unité de commande via les bus de code d'instructions et les convertit en signaux pour commander le fonctionnement des registres et de l'additionneur.
ALU effectue des opérations arithmétiques uniquement sur nombres binaires un point fixe. Pour traiter les nombres à virgule flottante, un coprocesseur mathématique ou des programmes spécialement conçus sont utilisés.
Des informations plus détaillées sur la structure et le fonctionnement du dispositif de commande et de l'ALU peuvent être trouvées dans / 3 - 5 /.
Registres d'ampli-op- une partie de la mémoire du microprocesseur. Regardons les registres en utilisant l'exemple du processeur Intel 8086, qui ne contient que 14 registres à double octet. Dans les processeurs modernes, ils sont beaucoup plus nombreux et de plus grande taille. Cependant, la mémoire du processeur à 14 registres est utilisée comme modèle de base, notamment pour le langage assembleur.
L'OU comprend les registres suivants :
1) registres à usage général (RON) ou universel: AX - (AH, AL), BX - (BH, BL), CX - (CH, CL), DX - (DH, DL) peuvent être utilisés pour stocker temporairement des données, tandis que vous pouvez travailler avec chaque registre comme un entier, et vous pouvez séparément, avec chaque moitié; mais chacun des RON peut être utilisé comme un RON spécial lors de l'exécution de certaines commandes spécifiques ;
2) registres de décalage: SP, BP, SI, DI sont indivisibles et sont destinés à mémoriser les adresses relatives des cellules mémoire au sein des segments (décalages depuis le début des segments) ;
2.1) SP (Empiler Aiguille) - décalage du haut de la pile ;
2.2) PA (Base Aiguille) - décalage de l'adresse de départ du champ mémoire directement alloué pour la pile ;
2.3) SI (La source Indice) , DI (Destination Indice) sont destinés à stocker les adresses de l'index de la source et de la destination des données lors d'opérations sur des chaînes et similaires.
Mot d'état du processeur (PSW – Processeur État Mot) ou inscrivez-vous drapeaux- a une taille de 2 octets et contient des signes ou des drapeaux à un bit. Il y a 9 drapeaux dans le registre : 6 d'entre eux conditionnel ou statut, reflètent les résultats des opérations effectuées par le système d'exploitation, les 3– directeurs généraux, déterminez le mode d'exécution du programme.
1) Indicateurs d'état.
1.1) FC (Transporter Drapeau) - porter le drapeau. Il est mis à 1 si un « report » du bit de poids fort se produit lors de l'exécution d'opérations arithmétiques et de certaines opérations de décalage.
1.2) PF (Drapeau de parité)- drapeau de parité. Vérifie les 8 bits les moins significatifs des résultats sur les données. Un nombre pair de uns fait que ce drapeau est mis à 1, un nombre impair à 0.
1.3) UN F (Auxiliaire Transporter Drapeau) - drapeau de retenue logique en arithmétique binaire-décimale. Mis à 1 si l'opération arithmétique entraîne le transfert ou l'emprunt du quatrième bit à la droite de l'opérande à un octet. Utilisé pour les opérations arithmétiques sur les codes BCD et ASCII.
1.4) ZF (Zéro Drapeau) - drapeau zéro. Mis à 1 si le résultat de l'opération est 0, sinon ZF est mis à zéro.
1.5) SF (Drapeau de signe)- signer le drapeau. Mis à 1 si le résultat de l'opération arithmétique est négatif, à 0 si le résultat est positif.
1.6) DE (Débordement Drapeau) - indicateur de débordement. Défini sur un en cas de débordement arithmétique lorsque le résultat est hors de la grille de bits.
2) Drapeaux de contrôle.
2.1) TF (Piéger Drapeau) - indicateur de trace. Un seul état de ce drapeau met le processeur en mode d'exécution de programme pas à pas.
2.2) SI (indicateur d'interruption)- indicateur d'interruption. Lorsque ce drapeau est à zéro, les interruptions sont désactivées, et lorsqu'il est unique, elles sont activées (le mécanisme d'interruption sera discuté dans le prochain cours).
2.3) DF (Direction Drapeau) - drapeau de direction. Utilisé dans les opérations de chaîne pour spécifier la direction du traitement des données ; lorsque l'état est unique, les lignes sont traitées "de droite à gauche", lorsque l'état est zéro - "de gauche à droite".
L'emplacement des drapeaux dans le registre PSW est illustré à la figure 4.2. Les bits gratuits sont réservés pour une utilisation future.
Figure 4.2 - Disposition des drapeaux dans le registre PSW
Principes architecturaux de l'organisation des processeurs RISC.
Comme indiqué dans / 2, 14, 15 /, la liste des commandes d'un microprocesseur moderne peut contenir un assez grand nombre de commandes. Cependant, tous ne sont pas utilisés aussi souvent et régulièrement. Cette propriété du jeu d'instructions était une condition préalable au développement de processeurs à architecture RISC. L'idée principale était de réduire la liste des commandes utilisées et, par conséquent, de simplifier l'unité de contrôle du processeur et d'organiser une exécution plus rapide des commandes restantes au détriment des ressources cristal libérées dans ce cas.
Les premiers processeurs avec un jeu d'instructions réduit ont été implémentés au début des années 80 du 20ème siècle / 2 / :
1) En 1980, à l'Université de Californie à Berkeley, sous la direction des professeurs David Patterson et Carlo Sequin, un processeur a été développé, qui a été nommé RISC. Les modèles RISC-I, RISC-II, SOLAR ont été développés.
2) En 1981, à l'Université de Stanford, sous la houlette de John Hennesy, un processeur appelé MIPS (Microprocessor Without Interlocked Pipeline Stages) a été conçu. Plus de détails sur l'essence du pipeline seront examinés dans la prochaine question de la conférence.
Plus tard, les deux modèles avec un jeu d'instructions réduit ont été appelés processeurs RISC. Une caractéristique distinctive de ces processeurs est un grand nombre de RON (environ 256).
Décrivons brièvement les principes de base de l'architecture RISC / 2, 15 /.
1) Même longueur de commande... Cela facilite leur récupération à partir de la mémoire principale. Toutes les instructions sont lues en un cycle d'horloge, ce qui permet de traiter le flux d'instructions en pipeline, c'est-à-dire que la synchronisation du matériel du processeur est effectuée, en tenant compte du transfert séquentiel de contrôle d'une unité matérielle à une autre. Dans les processeurs RISC modernes, la longueur des instructions est de 32 bits.
2) Ensemble réduit d'actions sur les opérandes situés en mémoire... Des méthodes simples d'adressage de la mémoire permettent un accès rapide aux opérandes en mémoire. Le traitement des données mis en œuvre lors de l'exécution des commandes RISC n'est jamais associé à des opérations de lecture (écriture) en mémoire (contrairement à de nombreuses commandes CISC). L'échange d'opérandes entre la mémoire et les registres est effectué par des instructions spéciales LOAD et STORE. Le grand nombre de registres de blocs RON permet de réduire le nombre d'accès mémoire.
3) Effectuer toutes les opérations de calcul sur les données situées uniquement dans le RON. Comme il existe de nombreux registres, toutes les variables scalaires et même les petits tableaux de variables sont le plus souvent situés dans des registres, ce qui permet d'accélérer le traitement des données. L'utilisation de commandes simples facilite leur acheminement. En moyenne, les commandes RISC sont exécutées en un cycle d'horloge.
4) Schémas de contrôle relativement simples... Une diminution de la liste des commandes, l'utilisation de commandes ne mettant en œuvre que des opérations simples, et l'exclusion des accès mémoire dans les commandes de traitement de données ont permis de réduire la consommation de ressources cristal pour le contrôle. Grâce à cela, une grande surface de la matrice est allouée pour accueillir des périphériques pouvant augmenter les performances globales du processeur : pipelines supplémentaires, cache accru du 1er niveau, plus de RON.
Il est important de noter qu'avec la même technologie de production, les processeurs RISC ont des fréquences de fonctionnement plus élevées par rapport aux processeurs CISC, ce qui est un avantage important des processeurs RISC.
Selon / 15 /, les unités matérielles suivantes peuvent être distinguées dans l'architecture des processeurs RISC, qui forment les étages du pipeline :
1) Bloc de chargement des instructions comprend les composants suivants : un bloc pour extraire des instructions de la mémoire, un registre d'instructions où l'instruction est placée après l'extraction, et un bloc pour décoder les instructions. Cette étape est appelée étape de récupération des instructions.
2) RON avec les unités de contrôle de registre forment la deuxième étape du pipeline, qui est responsable de la lecture des opérandes d'instruction. Les opérandes peuvent être stockés dans la commande elle-même ou dans l'un des RON. Cette étape est appelée étape d'échantillonnage de l'opérande.
3) ALU et, si une batterie est implémentée dans cette architecture, avec la logique de contrôle, qui, à partir du contenu du registre d'instructions, détermine le type de micro-opération à effectuer. Lors de l'exécution d'opérations de transitions conditionnelles et inconditionnelles, la source de données peut également être un compteur de commandes. Cette étape est appelée étape exécutive du convoyeur.
4) Ensemble de RON et Logic Logic forment une étape de stockage de données. Ici, les résultats de l'exécution de la commande sont écrits dans le RON ou la mémoire principale.
Les processeurs RISC incluent les microprocesseurs MIPS R4000, R8000, R100000 de MIPS Technologies Inc., UltraSPARC I, UltraSPARC II, UltraSPARC III de Sun, PowerPC d'IBM-Motorola, Alpha AXP de DEC, PA-RISC de Hewlett Packard, les microcontrôleurs de Microchip .. .
Malgré les avantages évidents, les processeurs RISC "sous leur forme pure" ne sont pas largement utilisés sur le marché des ordinateurs personnels, la plupart d'entre eux sont utilisés comme unités centrales de traitement des postes de travail. Cependant, la plupart des processeurs CISC modernes, par exemple Pentium, utilisent les réalisations des architectures RISC, en particulier les cœurs RISC pour effectuer des opérations de calcul.
Les modèles de processeurs RISC se développent et s'améliorent activement. À l'heure actuelle, des produits commercialement importants sont mis en œuvre sur leur base : les systèmes SPARC et MIPS.
Des informations plus complètes sur les processeurs RISC, les caractéristiques de leur architecture et leur fonctionnement peuvent être trouvées dans / 2 /, la littérature spéciale et les sources ouvertes sur Internet.
Moyens architecturaux pour améliorer les performances du processeur. Traitement des informations des convoyeurs.
La performance est l'une des caractéristiques les plus importantes d'un processeur. Selon / 2 /, dans le cas général, il est déterminé par la quantité de travail de calcul effectué par unité de temps. Les facteurs les plus importants affectant les performances comprennent la vitesse d'horloge, le nombre d'instructions du programme et le temps d'exécution moyen d'une seule instruction. Pour une évaluation simplifiée des performances du processeur, une métrique est souvent utilisée qui indique le nombre d'instructions exécutées par seconde. Il est défini comme le quotient de la division de la fréquence d'horloge par le temps d'exécution moyen d'une instruction individuelle par le processeur et est mesuré en MIPS (Meg Insruction Per Second) pour les tâches entières et en MFLOPS (Meg Floating Point Operations Per Second) pour la virgule flottante. calculs. Dans ce cas, les estimations de l'indicateur qui détermine le nombre d'instructions exécutées par seconde sont effectuées pour des opérations avec des opérandes de registre, sans être liées à la vitesse de la mémoire principale. Cependant, ce chiffre ne prend pas en compte les caractéristiques architecturales des processeurs spécifiques. Par conséquent, pour les caractéristiques comparatives de divers processeurs, des estimations de performances relatives sont utilisées, pour obtenir quels programmes de test spéciaux sont utilisés.
Conformément à / 2 /, une augmentation des performances des processeurs est obtenue dans la plupart des cas grâce à l'utilisation de solutions technologiques et architecturales spéciales. Les approches technologiques (amélioration des technologies de production de propriété intellectuelle, augmentation du degré d'intégration) ont été abordées précédemment, dans le deuxième chapitre. Par conséquent, attardons-nous plus en détail sur les méthodes architecturales permettant d'augmenter les performances des processeurs. L'amélioration de l'architecture des processeurs, permettant d'augmenter ses performances, est actuellement associée tout d'abord au développement de moyens de traitement parallèle des données. On distingue ici les domaines suivants :
1) Une augmentation du parallélisme "naturel" - une augmentation du nombre de bits de traitement et de transmission de données (le nombre de bits des processeurs est passé de 4 à 32 et 64 bits).
2) Traitement des données du convoyeur (multiphase) - le processus de calcul est divisé en plusieurs phases, chacune utilisant ses propres moyens et un tampon pour stocker le résultat (étape du convoyeur).
3) Traitement de données multi-éléments - traitement de données parallèle dans plusieurs unités d'exploitation (OU) du processeur.
Les méthodes de traitement parallèle peuvent être combinées. Par exemple, dans un processeur, vous pouvez organiser plusieurs unités opérationnelles, chacune utilisant le pipeline.
Examinons plus en détail les deux dernières directions.
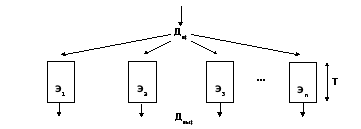
À multiphase traitement, comme le montre la figure 4.3, le processus de traitement des données est divisé en plusieurs étapes (phases), exécutées séquentiellement.
Figure 4.3 - Traitement des données en plusieurs phases
Il existe des tampons entre les phases pour stocker les résultats intermédiaires. Après avoir terminé la première phase, le résultat est stocké dans la mémoire tampon et le traitement de la deuxième phase commence. Les coureurs de la première phase sont libérés et le prochain bloc de données arrive. Si la durée des phases de traitement est la même et est T/ m, alors avec cette méthode, les performances du système augmenteront de m une fois que. Cette méthode correspond au pipeline.
Considérons l'organisation du pipeline au niveau de l'exécution de l'instruction machine / 2 /. Chaque bloc de la chaîne pipeline n'exécute qu'une seule étape d'exécution de la commande. Le traitement complet d'une commande prend plusieurs cycles d'horloge.
Étapes typiques de l'exécution d'une instruction : 1) récupérer l'instruction IF (Instruction Fetch), 2) décoder l'instruction ID (Instruction Decode), 3) lire les opérandes RD (Read Memory), 4) exécuter l'opération EX spécifiée dans l'instruction ( Exécuter), 5) écrire le résultat WB (Write Back). Au cours de l'exécution, la commande se déplace le long du pipeline, libérant l'étape suivante pour la commande suivante. Le contenu des tampons, qui sont utilisés pour stocker les informations transmises le long des étapes du pipeline, est mis à jour à chaque cycle à la fin de l'étape d'exécution de la commande suivante. Les tampons intermédiaires assurent un fonctionnement parallèle indépendant des blocs de la chaîne pipeline : tandis que le bloc suivant commence à exécuter la prochaine étape de commande, le bloc précédent peut commencer à traiter la commande suivante, comme illustré à la Figure 4.4.
|
Cycles du processeur |
||||||||||
|
Commander je | ||||||||||
|
Commander je + 1 | ||||||||||
|
Commander je + 2 | ||||||||||
|
Commander je + 3 | ||||||||||
|
Commander je + 4 | ||||||||||
|
Commander je + 5 | ||||||||||
Figure 4.4 - Traitement des commandes de pipeline
Il convient de noter que le traitement d'instructions pipeline ne réduit pas le temps d'exécution d'une instruction individuelle, qui dans un processeur pipeline reste le même que dans un processeur non pipeline conventionnel. Cependant, du fait que pendant le traitement en pipeline, la majeure partie du processus de calcul est en mode d'exécution simultanée de commandes, la vitesse d'émission des résultats des commandes exécutées séquentiellement augmente proportionnellement au nombre d'étages du pipeline. La durée de l'exécution des différentes étapes de l'exécution de la commande dépend généralement du type de commande et de l'emplacement des opérandes. Le traitement des commandes du pipeline est plus efficace lorsque la durée de toutes les phases d'exécution des commandes est approximativement la même. Malheureusement, il n'est pas toujours possible d'assurer le fonctionnement continu du convoyeur en raison de divers conflits : sur les ressources, selon les données, sur la gestion. Plus de détails sur les conflits - dans / 2, 7 /.
Un processeur dans lequel le processus d'exécution d'une commande est divisé en 5 à 6 étapes est appelé processeur conventionnel. processeur en pipeline... Si vous augmentez le nombre d'étages de convoyeur, chaque étage individuel fera moins de travail et, par conséquent, contiendra moins de logique matérielle. En raison des délais de propagation du signal plus courts dans chaque étage séparé du pipeline, une augmentation de la fréquence de fonctionnement et une augmentation correspondante des performances du processeur sont obtenues. Un processeur avec un pipeline nettement plus profond que 5-6 étapes est appelé super convoyeur... Par exemple, le Pentium II contient 12 étapes, l'UltraSPARC III en a 14 et le Pentium 4 en a 20.
multi-élément
T et le système utilise m T/ m
UNE = B + C; ré = E + F.
superscalairescalairescalaire
Moyens architecturaux pour améliorer les performances du processeur. Traitement de l'information multi-éléments.
Comme le montre l'image 4.5 / 2 /, multi-élément le traitement est effectué sur plusieurs amplificateurs de fonctionnement en parallèle. Chaque élément fait son travail, en traitant une partie des données du début à la fin.
Figure 4.5 - Traitement de données parallèle multi-éléments
Si le temps d'exécution des travaux sur un élément distinct est T et le système utilise méléments, alors avec une certaine idéalisation, on peut s'attendre à ce que le temps moyen pour un tel travail soit T/ m(en fait - moins). Dans les processeurs modernes, ce type de traitement est associé au concept d'architecture superscalaire.
L'exemple le plus simple de parallélisme de calcul est l'exécution de deux instructions dont les opérandes ne sont pas liés l'un à l'autre :
UNE = B + C; ré = E + F.
Par conséquent, les deux commandes peuvent être exécutées en même temps. Pour effectuer des opérations indépendantes, le processeur comprend un ensemble d'unités arithmétiques, dont chacune est généralement mise en pipeline.
Un processeur contenant plusieurs amplificateurs opérationnels qui permet à plusieurs instructions scalaires d'être exécutées en même temps est appelé superscalaire processeur. L'équipe s'appelle scalaire si ses opérandes d'entrée et le résultat sont des nombres (scalaires). Les processeurs traditionnels à ampli-op sont appelés scalaire... Dans un processeur superscalaire, le traitement des instructions est parallélisé non seulement dans le temps (pipeline), mais aussi dans l'espace (plusieurs pipelines). Les performances d'un tel processeur sont évaluées par la vitesse à laquelle les commandes exécutées sortent de tous ses pipelines.
Actuellement, deux méthodes de traitement superscalaire sont utilisées. La première méthode est basée sur un mécanisme purement matériel pour récupérer des instructions de programme non liées à partir de la mémoire (mémoire cache, tampon de prélecture) et les lancer en parallèle pour exécution. Le matériel du processeur est responsable de l'efficacité du chargement des pipelines parallèles, ce qui est le principal avantage de cette méthode de traitement superscalaire. Dans ce cas, le processus de traduction de programmes pour un processeur superscalaire n'est pas différent de la traduction de programmes pour un processeur scalaire traditionnel. Conformément à ce procédé, il est relativement aisé de mettre en oeuvre des microprocesseurs superscalaires de différentes familles qui sont logiciellement compatibles entre eux. Dans ce cas, il n'y a aucun problème avec l'utilisation de logiciels créés précédemment. Tous les processeurs de la famille Pentium sont implémentés de cette manière.
Dans les processeurs mettant en œuvre la deuxième méthode de traitement superscalaire, le compilateur parallélisateur est chargé de programmer l'exécution parallèle de plusieurs instructions. Tout d'abord, il analyse le programme source afin d'identifier les commandes pouvant être exécutées simultanément. Ensuite, le compilateur regroupe ces commandes dans des packages de commandes - mots de commande longs (VLIW), de plus, le nombre de commandes simples dans la commande VLIW est pris égal au nombre d'unités d'exécution du processeur. Étant donné que tout le travail de préparation à l'exécution des commandes VLIW est effectué par le compilateur, les conflits lors de leur exécution sont exclus. Cette méthode de traitement superscalaire est implémentée dans les processeurs VLIW avec une architecture sperscalaire statique. Malheureusement, ces processeurs nécessitent un logiciel spécial. De plus, les programmes compilés pour une génération de microprocesseurs peuvent ne pas fonctionner efficacement sans recompilation sur les processeurs de la prochaine génération. Cela oblige les développeurs de logiciels à développer des versions modifiées fichiers exécutables de son produit pour différentes générations de processeurs. Les idées de VLIW ont été proposées par des ingénieurs et des scientifiques russes dirigés par le professeur B.A. Babayan dans le développement du super-ordinateur domestique "Elbrus-3" (1990). Actuellement, la technologie VLIW est implémentée dans le processeur Elbrus E2K de la société nationale Elbrus International, les processeurs Crusoe de Transmeta, ainsi que dans la famille de processeurs de signal (pour le traitement du signal numérique) TMS320C60xx de Texas Instruments.
Classification et structure des instructions du processeur.
Fonctionnellement, toutes les commandes du processeur peuvent être réparties dans les groupes suivants :
1) commandes d'envoi de données et d'entrée-sortie ;
2) commandes pour les opérations arithmétiques et logiques au niveau du bit ;
3) commandes de transfert de contrôle.
Commandes de transfert de données assurer l'échange d'informations entre les registres du microprocesseur, ainsi que des échanges externes de données lors du transfert vers le processeur depuis la mémoire ou le dispositif d'entrée et du processeur vers la mémoire ou le dispositif de sortie. Ces commandes indiquent généralement le sens de transmission, la source et/ou la destination des données. Par exemple, en assembleur, les commandes de ce groupe incluent la commande forwarding mov, la commande de démarrage CHARGE, commandes d'écriture sur le port et de lecture depuis le port de soufflage, DANS et DEHORS, respectivement, etc. En outre, cela inclut souvent des commandes pour mettre des données sur la pile. POUSSER et extraire les données de la pile POP.
En nombre instructions arithmétiques et logiques au niveau du bit dans la plupart des cas, les commandes incluent les opérations arithmétiques les plus simples, par exemple, ADD (ajouter), SUB (soustraire) et les opérations logiques, par exemple, AND ("AND"), OR ("OR"), etc. Les commandes arithmétiques incluent également les commandes de décalage arithmétique et logique, et les commandes d'opérations logiques incluent les commandes COMPARE (soustraction non destructive). Le nombre de commandes de ce groupe peut comprendre des commandes pour des opérations arithmétiques complexes : multiplication, division (non disponible dans tous les processeurs), instructions de traitement de données en virgule flottante, commandes de traitement multimédia.
Commandes de transfert de contrôle permettent de modifier la séquence d'exécution des commandes en présence de branches de programme : instructions de saut conditionnelles et inconditionnelles (JMP), appel de sous-programmes (CALL) et sortie de ceux-ci (RETURN). Les instructions de branchement conditionnel mettent en œuvre des transferts de contrôle en fonction de la valeur des drapeaux dans le registre PSW. Avec leur aide, le processeur est l'une des branches possibles de la poursuite du programme. Typiquement, un système de commande a plusieurs commandes de branchement conditionnel.
Dans les processeurs modernes, les systèmes de commande, ainsi que les commandes traditionnelles énumérées ci-dessus, contiennent des groupes de commandes qui étendent les fonctionnalités du microprocesseur pour le traitement des informations, le contrôle de son fonctionnement et la mise en œuvre d'un mode de fonctionnement multitâche sécurisé.
Les systèmes d'instructions de processeurs spécifiques peuvent inclure des instructions qui ne correspondent pas à la classification proposée. De telles commandes ne reflètent pas les principes généraux des programmes de construction et sont considérées comme supplémentaires.
L'exécution d'une commande (opération machine) est divisée en étapes plus petites - des micro-opérations (micro-commandes), au cours desquelles certaines actions élémentaires sont effectuées. La composition spécifique des micro-opérations est déterminée par le système de commande et la structure logique de l'ordinateur. Une séquence de micro-instructions qui implémentent une opération donnée (commande) forme le microprogramme d'opération. L'intervalle de temps pendant lequel une ou plusieurs micro-opérations sont exécutées simultanément est appelé cycle machine. Les limites d'horloge sont définies par les signaux d'horloge, qui sont générés par le générateur de signaux d'horloge.
En général, une commande de microprocesseur contient deux parties : opérationnelle et adresse. Conformément à / 1 /, l'accord sur la répartition des bits entre ces parties de la commande et sur le mode de codage des informations détermine la structure (format) de la commande. La partie opérationnelle de la commande contient un code d'opération qui fournit le codage des opérations (où m- le nombre de bits binaires alloués à la partie opérationnelle de la commande) et détermine quels appareils seront impliqués dans le processeur ou en dehors de celui-ci. V k-bit address partie de la commande contient des informations sur les adresses des opérandes impliqués dans l'opération. En général, la partie adresse de la commande doit contenir quatre champs d'adresse UNE1 , UNE2 , UNE3 , UNE4 ... Ils sont destinés à fixer les adresses des opérandes (A1, A2), l'adresse du résultat (A3) et l'adresse de l'instruction suivante (A4). Comme adresses A1,..., A3, les adresses des cellules RAM et les adresses des registres mémoire du microprocesseur peuvent être utilisées, comme adresse A4, uniquement les adresses des cellules RAM. Lors de l'utilisation de l'ensemble complet d'adresses, le format de commande est lourd. Il a été noté que toutes les opérations ne nécessitent pas l'ensemble complet des adresses A1-A4. Selon le nombre d'adresses spécifié, les commandes sont subdivisées en 0-adresse (non adressé), 1-adresse, 2 adresses, 3-adresse et 4 adresses.
Dans presque tous les microprocesseurs, l'adresse A4 est exclue. Cela est dû au fait que la plupart des instructions appartiennent à des sections linéaires d'algorithmes, et de telles instructions peuvent être placées dans des cellules de mémoire avec des adresses séquentiellement croissantes. Dans ce cas, pour obtenir l'adresse de la commande suivante à l'adresse de départ du segment de code, il suffit d'ajouter son offset dans le segment de code, ce qui est pratique à mettre en œuvre à l'aide du pointeur de commande. Cette façon d'adresser les commandes s'appelle Naturel, et les processeurs qui l'implémentent sont appelés processeurs avec une manière naturelle d'adresser les instructions... En cas de violation de l'ordre naturel des commandes (branches, boucles), des commandes de transfert de contrôle spéciales sont utilisées, qui contiennent l'adresse de transition, mais n'utilisent pas les adresses des opérandes. Les processeurs dont le champ d'adresse d'instruction utilise l'adresse A4 sont appelés processeurs avec une manière forcée d'adresser des commandes.
L'utilisation de l'adresse de résultat A3 est également redondante dans de nombreux cas. Ceci est justifié par le fait que le résultat d'opérations arithmétiques et logiques sur deux opérandes peut généralement être placé à la place de l'un des opérandes, qui ne sera probablement pas utilisé à l'avenir. Dans ce cas, dans les commandes à 2 adresses, des chiffres supplémentaires doivent être saisis dans le champ d'adresse, indiquant lequel d'entre eux est la source et qui est le destinataire de l'information. Dans les processeurs à architecture de batterie, le nombre d'adresses dans la partie adresse de l'instruction est réduit à un. Dans ceux-ci, l'un des opérandes situés dans l'accumulateur est implicitement défini par le code de commande et le résultat est placé dans l'accumulateur.
Dans les commandes non adressées, l'opérande est implicitement spécifié. Ces commandes comprennent des commandes de contrôle du processeur (par exemple, démarrer, arrêter, etc.), des instructions pour travailler avec la pile (l'opérande adressé par le pointeur SP est défini implicitement par le code de commande). Les commandes non adressées ont un format extrêmement abrégé, mais elles ne peuvent pas former indépendamment un système de commande complet sur le plan fonctionnel et ne sont utilisées qu'avec celles avec adresse.
Le format des commandes affecte le temps de résolution des problèmes, la consommation de mémoire, la complexité du processeur et dépend de la classe de problèmes à résoudre. En particulier, pour les calculs scientifiques et techniques, dans lesquels un volume important est occupé par des calculs en plusieurs étapes, les commandes à 1 adresse s'avèrent plus efficaces et, lors de l'utilisation d'un processeur de pile, également les commandes sans adresse. Pour les tâches de contrôle où les transferts et les opérations logiques sont une grande partie, les commandes à 2 adresses sont efficaces. Sur la base de ce qui précède, il convient de noter que les commandes sans adresse, à 1 adresse et à 2 adresses sont généralement utilisées dans les processeurs modernes. Les commandes à 3 adresses sont rarement utilisées et les commandes à 4 adresses ne sont pas du tout utilisées.
En raison de la variété des formats d'instructions et de données (nombres, symboles, structures, etc.), ainsi que de leurs emplacements, diverses manières d'adresser des instructions et des opérandes ont été formées, qui seront discutées ci-dessous.
Méthodes d'adressage des données. Direct, direct, indirect, enregistrez les modes d'adressage relatifs.
Les méthodes d'adressage de données définissent les mécanismes de calcul des adresses effectives des opérandes en mémoire et d'accès aux opérandes. Il existe les méthodes d'adressage (modes) / 2, 6 / suivantes :
1)Direct- vous permet de définir des valeurs fixes de l'opérande directement dans la partie adresse de la commande, c'est-à-dire que cela fait partie de la commande (Figure 5.1). Ce mode d'adressage est pratique lorsque l'on travaille avec des constantes.
Figure 5.1 - Adressage direct
Exemples : mov ax, 5564h
ajouter al, 1101001100b
N'oubliez pas qu'un opérande immédiat ne peut être spécifié qu'en tant qu'opérande source. L'inconvénient de l'adressage direct est la nécessité d'étendre le format de commande en spécifiant l'opérande lui-même dans le champ d'adresse de commande.
2)Droit- l'adresse de l'opérande est contenue dans le code de commande (Figure 5.2). Il est utilisé lorsque vous travaillez avec des variables et des constantes, dont l'emplacement en mémoire ne change pas pendant l'exécution de la tâche.
![]()
Figure 5.2 - Adressage direct
Ainsi, le code instruction indique l'offset de l'opérande en mémoire.
Exemple : segment d_s
supposer ds : d_s, cs : c_s
déplacer hache , mm ; 3154h est envoyé à l'adresse mm
Après avoir exécuté la troisième commande dans le registre hache la valeur sera écrite à l'adresse mm en mémoire, c'est-à-dire le nombre 3154h.
3) S'inscrire- celui-ci est contenu dans le registre défini par la commande, c'est-à-dire que l'adresse du registre est indiquée dans le champ d'adresse de la commande.
Exemples : mov ax, cx
L'adressage de registre est facile à distinguer de tous les autres par le fait que tous les opérandes d'instruction sont des registres. Ces instructions sont les plus compactes et s'exécutent plus rapidement que les autres types d'instructions car il n'y a pas d'accès mémoire.
4) Inscription indirecte- est un cas particulier d'adressage indirect, lorsque l'adresse spécifiée dans la commande est un pointeur vers une cellule contenant l'offset de l'opérande en mémoire (Figure 5.3).
En fait, la commande spécifie l'adresse de l'adresse, et le registre de base peut servir de registre d'adresse PA ou registres d'index SI ou DI.
L'adressage indirect est plus efficace que l'adressage direct, puisque seule l'adresse de registre est indiquée dans le champ d'adresse d'instruction, qui est plus court que l'adresse complète de l'opérande en mémoire. Cependant, ce mode d'adressage nécessite un préchargement du registre avec une adresse mémoire indirecte, ce qui consomme du temps supplémentaire.
Exemples : mov hache,
Si dans le registre si contient 10, alors le registre hache placera la valeur à l'offset 10 dans le segment de données.
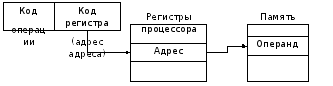
Figure 5.3 - Adressage indirect
L'adressage indirect est pratique à utiliser lors de la résolution de problèmes, en laissant l'adresse de registre inchangée dans la commande, vous pouvez modifier le contenu de la cellule avec cette adresse.
5) Inscrire un parent- est une généralisation des méthodes d'adressage qui permettent le calcul de l'adresse effective ( EA) l'opérande en mémoire comme la somme de la valeur de l'adresse de base et du "offset" disp spécifié dans la commande (Figure 5.4) et (Formule 5.1).
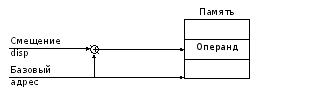
Figure 5.4 - Formation d'une adresse effective lorsque
adressage relatif
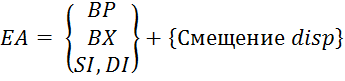 (5.1)
(5.1)
L'adressage relatif est largement utilisé aussi bien pour l'adressage de la mémoire, représentée sous forme de blocs (par exemple, des segments), que pour l'adressage de structures de données particulières : tableaux, enregistrements, etc. Selon la manière d'utiliser le registre adressé dans la commande, le les modes d'adressage de base et d'index sont distingués.
5.1) Indice- est utilisé pour traiter des tableaux de données ordonnés, chacun étant déterminé par son propre numéro. Ensuite, l'adresse de base du tableau est définie par l'offset disp spécifié dans la commande, et la valeur d'index (le numéro de l'élément du tableau) est déterminée par le contenu du registre d'index (formule 5.2).
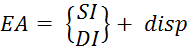 (5.2)
(5.2)
Exemple : segment d_s
mas db 3,5,1,8,9, '$'
supposer ds : d_s, cs : c_s
mov si, 0; to si - numéro d'élément du tableau
m1 : mov ah, mas ; masse offset
; dans ah - la valeur de l'élément du tableau mas avec
; nombre en si
L'adressage indexé est pratique lorsque vous devez écrire ou lire une liste de données à partir de cellules de mémoire séquentielles non pas dans une rangée, mais avec une étape spécifiée dans l'index.
5.2) Base- utilisé pour accéder aux structures de données de longueur variable. Ensuite, l'adresse de base, qui détermine le début d'un ensemble d'éléments, est stockée dans le registre de base, et le décalage dans la commande détermine la distance à un certain élément (formule 5.3).
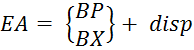 (5.3)
(5.3)
Ce mode d'adressage est utile pour les enregistrements - structures de données contenant des champs de longueurs différentes et éventuellement de types différents.
Considérons un exemple d'organisation d'un enregistrement sur les employés d'un certain département et d'accès à celui-ci et à ses champs. Admettons que tous les champs sont symboliques.
Structure des travailleurs ; informations sur les employés
nam db 30 dup (""); nom, prénom, patronyme
position db 30 dup (""); position
age db 2 dup (‘’); age
debout db 2 dup (‘’); ancienneté
salaire db 5 dup (‘’); salaire en roubles
; description d'un employé
travailleur sotr1<‘Иванов Пётр Сергеевич’,
« Programmeur », « 30 », « 8 », « 15000 »>
supposer ds : d_s, cs : c_s
; charge dans bx l'adresse du début de l'enregistrement (adresse de base)
Léa bx , sotr 1
; dans ax - valeur à l'adresse bx + décalage par champ d'âge
; c'est-à-dire que dès le début de l'enregistrement, on retrouve les cellules,
déplacer hache , mot ptr [ bx ]. âge
Dans les enregistrements avec des champs de longueurs différentes, le contenu du registre adressé correspond au début de l'enregistrement et le décalage dans la commande correspond à la distance dans l'enregistrement.
Méthodes d'adressage des données. Modes d'adressage registre, index de base, index de base relatif.
6) Index de base- permet d'accéder aux éléments du tableau pointé par le pointeur. L'adresse de base du tableau est définie par le pointeur de base (registre de base) et le numéro de l'élément du tableau est défini par le contenu du registre d'index (formule 5.4).
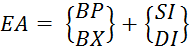 (5.4)
(5.4)
Exemple : mov ax, bx
Si dans bx contient 100, et dans si est 52, alors à l'adresse (décalage) 152 dans le segment de données se trouvent les données souhaitées.
Ce mode d'adressage est pratique à utiliser lorsque vous travaillez avec des structures de données complexes, car il vous permet de modifier deux composants d'adresse.
7) Indice de base relatif- utilisé pour adresser des éléments dans le tableau d'enregistrements spécifié. L'adresse de base du tableau est spécifiée par le pointeur de base, le numéro de l'enregistrement (c'est-à-dire l'élément du tableau) est déterminé par le contenu du registre d'index et le décalage dans la commande indique la distance à l'enregistrement (formule 5.5 ).
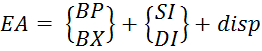 (5.5)
(5.5)
; décrire un tableau de 5 employés avec des valeurs par
; défaut
mas_sotr travailleur 5 dup (<>)
supposer ds : d_s, cs : c_s
; dans bx - l'adresse du début du tableau des employés
Léa bx , mas _ sotr
; en si - décalage du deuxième enregistrement
déplacer si , ( taper ouvrier )*2
; en hache - ancienneté du deuxième salarié
mov hache, .debout
Ainsi, pour accéder à un champ spécifique d'un tableau d'enregistrements, vous devez d'abord déterminer le début du tableau, y trouver l'enregistrement requis et déjà dans celui-ci - le champ requis.
Le choix du mode d'adressage dépend de la tâche spécifique et dans de nombreux cas est évident. Cependant, des situations surviennent lorsque plusieurs méthodes d'adressage peuvent être utilisées pour faire référence aux mêmes éléments de données. En définitive, lors de l'écriture d'un programme, l'utilisateur choisit lui-même un mode d'adressage spécifique.
Méthodes d'adressage des commandes.
Selon le segment du code dans lequel se trouve la commande requise et si son adresse est explicitement indiquée ou non, les modes d'adressage de commande suivants sont distingués :
1) Intra-segment droit- l'adresse de saut effective est calculée comme la somme du contenu actuel du pointeur de commande IP et d'un décalage relatif de 8 ou 16 bits. Ce mode est autorisé dans les sauts conditionnels et inconditionnels. Par exemple,
Si le contenu des registres euh et Al pas égal (commande jn), puis la transition vers la commande intitulée rencontré.
2) Intersegment droit- la commande spécifie un couple : segment et offset. Le segment est chargé dans le registre de segment CS et l'offset est chargé dans le registre IP. Ce mode n'est autorisé que dans les commandes de saut inconditionnel. Par exemple, appelez far ptr quickSort (appelez la procédure quickSort située dans un autre segment de code).
Ainsi, avec l'adressage direct, le champ d'adresse de la commande contient l'adresse de saut - l'adresse à laquelle se trouve la prochaine commande exécutée.
3) Intra-segment indirect- l'offset de l'adresse de saut est le contenu d'un registre ou d'une cellule mémoire spécifié dans n'importe quel mode d'adressage de données, sauf direct. Le contenu du pointeur d'instruction IP est remplacé par le contenu correspondant du registre ou de l'emplacement mémoire. Cette méthode n'est autorisée que dans les commandes de saut inconditionnel. Par exemple, jmp (aller à la commande dont l'adresse est dans la cellule à l'adresse indiquée dans le registre bx).
4) Intersegment indirect - le contenu des registres CS et IP est remplacé par le contenu de deux mots mémoire adjacents, dont l'adresse est spécifiée dans n'importe quel mode d'adressage de données, sauf direct et registre. Le mot de poids faible est chargé dans le registre IP, le mot de poids fort est chargé dans le registre CS. Ce mode n'est valable que dans les commandes de saut inconditionnel. Par exemple, appelez far ptr (un appel à une procédure située à l'adresse spécifiée dans le registre BP plus 4 octets supplémentaires).
Les méthodes d'adressage des commandes envisagées sont utilisées dans presque tous les systèmes de commande, élargissant ou raccourcissant la liste des commandes pour un microprocesseur particulier.
Comme indiqué précédemment, l'une des caractéristiques importantes de tout processeur est la capacité de ses registres internes, ainsi que des bus d'adresses et de données externes. Par exemple, le processeur Intel 8086 a une architecture 16 bits et la même largeur de bus de données. Ainsi, le nombre maximum qu'un processeur peut gérer est ![]() ... Cependant, le bus d'adresse du processeur Intel 8086 contient 20 lignes, ce qui correspond à un espace d'adressage de Mo. Pour obtenir une adresse physique de 20 bits d'une cellule mémoire, ajoutez l'adresse de début du segment mémoire dans lequel se trouve cette cellule et le décalage de cette cellule par rapport au début du segment (Figure 5.5).
... Cependant, le bus d'adresse du processeur Intel 8086 contient 20 lignes, ce qui correspond à un espace d'adressage de Mo. Pour obtenir une adresse physique de 20 bits d'une cellule mémoire, ajoutez l'adresse de début du segment mémoire dans lequel se trouve cette cellule et le décalage de cette cellule par rapport au début du segment (Figure 5.5).
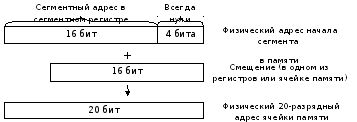
Figure 5.5 - Formation de l'adresse physique d'une cellule mémoire
L'adresse de segment sans les 4 bits les moins significatifs (c'est-à-dire divisée par 16) est stockée dans l'un des registres de segment (SS, DS, CS, ES).
Lors du calcul de l'adresse physique, le processeur multiplie le contenu du registre de segment par 16 et ajoute un décalage à l'adresse de 20 bits résultante.
Les processeurs 32 bits modernes ont un bus d'adresses 32 bits, ce qui correspond à un espace d'adressage de Go. Cependant, le procédé de formation d'adresse physique décrit ci-dessus ne permet pas d'aller au-delà de 1 Moctet. Pour pallier cette limitation, les processeurs 32 bits utilisent deux modes de fonctionnement : réel et sécurisé. V mode réel le processeur fonctionne pratiquement de la même manière que le plus rapide Intel 8086 et ne peut accéder qu'à 1 Mo d'espace d'adressage. La mémoire restante, même si elle est installée sur l'ordinateur, ne peut pas être utilisée. V mode protégé des segments et des décalages sont également utilisés, mais les adresses de début de segment physique sont extraites des tables de descripteurs de segment indexées à l'aide des mêmes registres de segment. Chaque descripteur de segment est de 8 octets, dont 4 octets (32 bits) sont alloués pour l'adresse de segment. Ce mécanisme permet une utilisation complète de l'espace d'adressage de 32 bits. Les processeurs 64 bits utilisent également l'organisation de la mémoire segmentée et peuvent utiliser l'organisation mémoire segment-page / 1 / ; l'adresse physique a 40, 44, 48, 64 bits. Ainsi, la quantité d'espace d'adressage dans les microprocesseurs 64 bits peut aller de 1 To (1 téraoctet - octet) à plusieurs Eoctets (1 exaoctet - octet).
Dans les chapitres précédents, il a été mentionné que le processeur, d'une part, coordonne le fonctionnement des différents appareils de l'ordinateur, d'autre part, il effectue lui-même des calculs conformément au programme utilisateur (principe du contrôle du programme). Ensuite, nous examinerons comment le processeur exécute les instructions et interagit avec d'autres appareils.
Transfert de contrôle. Transitions et procédures.
D'après / 8 /, flux de contrôle Est une séquence dans laquelle les commandes sont exécutées dynamiquement (pendant l'exécution du programme). La plupart des commandes ne modifient pas le flux de contrôle : après l'exécution d'une commande, la commande qui la suit en mémoire est exécutée. Le compteur de commandes (IP) après l'exécution de chaque commande est augmenté d'un nombre correspondant à la longueur de la commande. Le changement dans le flux de contrôle se produit lorsqu'il y a des instructions de saut (conditionnelles et inconditionnelles), des appels de procédure, des coroutines, ainsi que lorsque des exceptions et des interruptions se produisent.
1)Commandes de saut... Lorsque les commandes de saut sont exécutées, une nouvelle valeur est écrite de force dans le compteur de commandes IP - une nouvelle adresse en mémoire, à partir de laquelle les commandes seront exécutées.
Commander saut inconditionnel fournit un saut à une adresse donnée sans vérifier aucune condition. Par exemple, jmp met signifie sauter à la commande qui commence par l'adresse rencontré dans le texte du programme. Dans ce cas, toutes les commandes qui le précèdent sont ignorées.
Branche conditionnelle(branchement) ne se produit que lorsqu'une certaine condition est remplie, sinon la prochaine commande de programme dans l'ordre est exécutée. La condition sur la base de laquelle la transition est effectuée sont le plus souvent les signes du résultat de l'exécution de la commande arithmétique ou logique précédente. Chacune des caractéristiques est fixée dans son propre bit du registre des drapeaux PSW. Une telle approche est également possible, lorsque la décision de transition est prise en fonction de l'état d'un des registres généralistes, où le résultat de l'opération de comparaison / 3 / est placé au préalable. Regardons quelques exemples :
|
jz m1 m1 : ajouter al, 2 |
cmp ah, al je m1 m1 : ajouter al, 2 |
Le fragment de gauche illustre la vérification du contenu des registres AH et AL pour l'égalité à l'aide de drapeaux, en particulier le drapeau zéro ZF. La soustraction du contenu des registres est effectuée en premier: si leurs valeurs sont égales, le résultat est nul et la valeur du drapeau ZF change. La commande JZ vérifie si le drapeau ZF vaut 1, puis la transition vers la commande d'adresse M1 (add al, 2) est effectuée, sinon la commande d'addition add ah, 3 est exécutée. La commande d'adresse M2 est exécutée dans tous les cas. L'extrait de droite effectue le même test, mais en utilisant la commande de comparaison (cmp ah, al) et la commande de saut par égalité (je m1).
2) Procédures... Selon / 3,8 /, la procédure est un moyen important de structurer les programmes. Il peut être appelé à n'importe quel moment du programme. Mais contrairement aux commandes de saut, une fois la procédure exécutée, le contrôle revient à la commande suivant la commande d'appel de procédure.
Le mécanisme procédural est basé sur des commandes d'appel de procédure, qui fournissent un saut du point courant du programme à la commande initiale de la procédure, et renvoient des commandes de la procédure, pour revenir au point immédiatement après la commande d'appel. Pour travailler avec des procédures, une pile (mémoire supplémentaire organisée sous forme de file d'attente) est utilisée, dans laquelle la commande d'appel place la valeur courante du compteur de commandes (IP) lors des transitions intra-segment (ou les valeurs du registres IP et CS pendant les transitions entre segments) - l'adresse du point de retour. Lorsque la procédure se termine, les anciennes valeurs des registres correspondants sont restaurées à partir de la pile. La procédure est limitée aux instructions PROC et ENDP.
Une procédure récursive est particulièrement intéressante, c'est-à-dire une procédure qui s'appelle elle-même soit directement, soit par l'intermédiaire d'une chaîne d'autres procédures. Pour de telles procédures, une pile est également utilisée, dans laquelle, en plus de l'adresse de retour, des paramètres et des variables locales pour chaque appel sont stockés.
Prenons comme exemple un programme qui utilise un appel de procédure. Etant donné que la procédure est située dans le même segment de code que le programme principal et est décrite comme une procédure d'appel proche (directive NEAR), la transition sera intra-segment.
pile de segments s_s "pile"
supposer ss : s_s, ds : d_s, cs : c_s
appel pr 1 ; appel de sous-programme
déplacer euh ,4 ch
pr1 procà proximité; début du sous-programme (près de l'appel)
pousser la hache ; pousser le contenu du registre AX sur la pile
pop ax ; récupère le contenu du registre AX de la pile
ret ; commande pour revenir à la commande suivante après
; appel de procédure
pr1 endp; fin du sous-programme
Lorsque l'appel à la procédure PR1 (appel de commande pr1) est exécuté, l'adresse de retour est poussée sur la pile - le contenu du compteur de commandes IP contenant sur ce moment l'adresse de la commande à exécuter après celle en cours (mov ah, 4ch). La valeur du registre IP est écrasée par une nouvelle valeur — l'adresse de la première commande de la procédure. Lorsque la commande retour de la procédure (ret) est atteinte depuis la pile, l'ancienne valeur est écrite dans le registre IP, qui fournit un retour au programme principal pour la commande mov ah, 4ch, qui suit immédiatement la commande de la procédure appel.
L'interaction entre les procédures appelante et appelée est illustrée à la Figure 5.6 / 8 /.
Transfert de contrôle. Coroutines. Exceptions et interruptions
Coroutines... Dans la séquence habituelle des appels, il existe une distinction claire entre la procédure appelée et la procédure appelante. La procédure appelée recommence à chaque fois depuis le début, quel que soit le nombre de fois où elle est appelée. Pour sortir de la procédure appelée, utilisez la commande RET, comme décrit dans le paragraphe précédent. Soit deux procédures A et B, chacune appelant l'autre en tant que procédure. Lors du retour de B vers A, la procédure B effectue une transition vers l'instruction suivant la commande pour appeler la procédure B. Lorsque la procédure A transfère le contrôle à la procédure B, elle ne revient pas au tout début de B (sauf pour la première fois), mais à l'endroit où il s'est produit l'appel précédent A. Les procédures qui fonctionnent de cette manière sont appelées coroutines.
Figure 5.6 - Interaction entre l'appelant et l'appelé
procédures
En règle générale, les coroutines sont utilisées pour effectuer un traitement parallèle des données sur un seul processeur. Les commandes CALL et RET habituelles ne conviennent pas pour appeler des coroutines, car l'adresse de saut est prise dans la pile, comme lors du retour, mais, contrairement au retour, lors de l'appel d'une coroutine, l'adresse de retour est placée à un certain endroit afin de retourner plus tard. Pour ce faire, vous devez d'abord extraire l'ancienne adresse de retour de la pile et la mettre dans le registre interne, puis pousser le compteur de commandes IP sur la pile et, enfin, copier le contenu du registre interne dans le compteur de commandes. Puisqu'un mot est extrait de la pile et qu'un autre est poussé sur la pile, l'état du pointeur de pile ne change pas. Le schéma d'interaction des coroutines est illustré à la figure 5.7 / 8 /.
Figure 5.7 - Interaction des coroutines
4) Exceptions et interruptions fournir un transfert forcé de contrôle à une procédure spéciale - gestionnaire d'interruption système qui effectue certaines actions. Après avoir terminé les actions, le gestionnaire d'interruption rend le contrôle au programme interrompu. Il doit continuer à exécuter le processus interrompu dans le même état qu'il était lorsqu'il a été interrompu. Un gestionnaire d'interruption diffère d'une routine régulière en ce qu'au lieu d'être associé à un programme spécifique, il est situé dans une zone de mémoire fixe.
Exception est un type spécial d'appel de procédure qui se produit dans une certaine condition - important mais rarement vu. Les conditions les plus courantes pouvant provoquer des exceptions sont le débordement et la disparition de bits significatifs lors d'opérations en virgule flottante, le débordement lors d'opérations avec des entiers, une violation de sécurité, un opcode indéfini, un débordement de pile, une tentative de démarrage d'un IOC inexistant, une tentative d'appel d'un mot depuis une cellule avec une adresse impaire, division par zéro. Si le résultat est dans la plage acceptable, aucune exception n'est levée. Il est important de noter que ce type d'interruption est déclenché par une sorte de condition exceptionnelle causée par le programme lui-même et détectée par le matériel ou le micrologiciel. Les exceptions, à leur tour, sont subdivisées en Défaillance, pièges et se bloque.
crash Est une exception qui est signalée à la limite de la commande précédant la commande qui a provoqué l'exception. Après avoir signalé un échec, l'état de l'ordinateur est restauré dans une situation où la commande peut être redémarrée. Un exemple d'échec est un appel à un dispositif de soufflage d'air inexistant.
Piéger Est une exception signalée à la limite de la commande immédiatement après la commande pour laquelle l'exception a été levée. Par exemple, un débordement d'entier.
Résiliation anormale Est une exception qui ne vous permet pas de déterminer avec précision la commande qui l'a appelée, ni de redémarrer le programme dans lequel cette exception s'est produite. Les terminaisons anormales sont utilisées pour signaler erreurs graves: erreurs matérielles, valeurs incohérentes ou invalides dans les tables système.
Interruptions- ce sont des changements dans le flux de contrôle, causés non pas par le programme lui-même, mais par certains événements asynchrones, et généralement associés au processus d'E/S. Les interruptions permettent d'effectuer des opérations d'E/S indépendamment du processeur. Étant donné que la vitesse du microprocesseur est supérieure à celle du dispositif de soufflage d'air, le processeur a la capacité d'exécuter d'autres programmes ou d'effectuer d'autres fonctions au lieu de surveiller en permanence l'état des périphériques qui lui sont connectés. Lorsque l'IOD demande un service au processeur, il l'en informe en générant une requête correspondante (signal), par laquelle le processeur peut interrompre l'exécution du programme en cours. Les interruptions du périphérique d'E/S sont contrôlées par le contrôleur d'interruptions, qui est connecté au processeur et structurellement inclus dans sa composition.
La différence entre les exceptions et les interruptions est que les exceptions sont synchrones au programme et les interruptions sont asynchrones. Les exceptions sont levées directement par le programme et les interruptions sont levées indirectement. Si vous redémarrez le programme à plusieurs reprises avec les mêmes données d'entrée, des exceptions seront levées à chaque fois aux mêmes endroits dans le programme, mais pas les interruptions.
La présence d'un signal d'interruption ne doit pas provoquer l'interruption d'un programme en cours d'exécution ; le processeur peut disposer d'un système de protection contre les interruptions : désactiver le système d'interruption, interdire ou masquer les signaux d'interruption individuels. Le contrôle logiciel de ces outils permet au système d'exploitation de réguler le traitement des signaux d'interruption. Le processeur peut traiter les interruptions dès leur arrivée, reporter leur traitement pendant un certain temps, les ignorer complètement. Par exemple, si l'indicateur de trace TF est défini sur un, le processeur exécute une instruction de programme, puis génère une interruption de type 1, c'est-à-dire que le programme est exécuté par étapes. Si l'indicateur d'interruption IF est effacé, le processeur ne répond pas aux interruptions externes (sauf pour les interruptions non masquables). Pour masquer certains types d'interruptions, un registre de masque est utilisé. Il est contrôlé par les commandes CLI (désactiver les interruptions) et STI (activer les interruptions).
Chaque type d'interruption ou exception est associé à un numéro d'identification compris entre 0 et 255 et à un gestionnaire correspondant. Les exceptions et les interruptions non masquables sont numérotées de 0 à 31, et les interruptions masquées sont numérotées de 32 à 255. Toutes ces valeurs ne sont pas actuellement utilisées par les processeurs ; les numéros non attribués sont réservés pour une utilisation future. Les numéros d'interruption, les exceptions et les adresses (vecteurs) des gestionnaires correspondants sont stockés dans une table spéciale - table vectorielle d'interruption situé en mémoire. Lorsqu'une interruption ou une exception se produit, par son numéro dans la table de vecteurs d'interruption, l'adresse de la routine de traitement d'interruption ou d'exception correspondante, vers laquelle la transition est effectuée, est déterminée. Examinons de plus près comment l'appel et le retour d'un gestionnaire d'interruption ou d'exception sont effectués.
Les mécanismes de gestion des interruptions et des exceptions sont très similaires, mais il existe quelques différences liées au retour du gestionnaire. Le mécanisme de gestion des interruptions comprend les étapes suivantes :
1) Établir le fait de l'interruption.
2) Stocker dans la pile l'état du processus interrompu, qui est déterminé par le contenu du registre des drapeaux PSW, le compteur de commandes IP, le registre de segment CS. Si nécessaire, le contenu des registres est également mémorisé, qui sera utilisé par la routine d'interruption et, par conséquent, modifié. Certains types d'exceptions et d'interruptions envoient également un code d'erreur sur la pile afin de diagnostiquer la cause de l'exception.
3) Détermination de l'adresse de la procédure de traitement d'interruption par le numéro d'interruption dans la table des vecteurs d'interruption et mise en œuvre de la transition vers ce gestionnaire en chargeant l'adresse dans les registres CS et IP.
4) Traitement des interruptions. La routine de service d'interruption exécute ses instructions.
5) Restauration de l'état du programme interrompu. Après l'exécution réussie de la procédure de gestion des interruptions, en atteignant la commande IRET (cette commande met fin aux gestionnaires d'interruptions), l'ancien contenu des registres qui y est stocké (l'ancien état) est restauré à partir de la pile, y compris, et adresse de retour- les valeurs des registres CS et IP.
6) Retournez au programme interrompu. L'adresse de retour est utilisée pour sauter au processus interrompu. Les retours doivent être faits à la commande suivant la commande exécutée avant que l'interruption ne se produise. Une routine d'interruption avec cette propriété est appelée transparent.
Si un échec se produit, l'adresse de retour est l'adresse de la commande qui a causé l'échec, donc le retour est fait à nouveau à cette commande pour tenter de la ré-exécuter (redémarrer). La gestion des interruptions est similaire à la gestion des interruptions. En cas de terminaisons anormales, le processus de calcul est terminé sans possibilité de restaurer l'état d'origine du programme dans lequel cette exception s'est produite.
Étant donné que les signaux d'interruption se produisent à des moments arbitraires, il peut y avoir plusieurs signaux d'interruption au moment de l'interruption, qui ne peuvent être traités que de manière séquentielle. Pour cela, les interruptions sont prioritaires. Il existe deux disciplines pour traiter les interruptions prioritaires : 1) une interruption avec une priorité plus élevée peut interrompre le traitement d'une interruption avec une priorité inférieure, et 2) une interruption avec une priorité inférieure est traitée jusqu'à la fin, après quoi une interruption avec un une priorité plus élevée est traitée.
Dans le chapitre suivant, nous examinerons les problèmes liés à l'organisation de la mémoire des machines virtuelles.
Caractéristiques architecturales des processeurs Pentium.
Selon / 2 /, le microprocesseur Pentium (1993) est le premier processeur superscalaire pour ordinateurs personnels. Comprend les blocs fonctionnels suivants :
1) bloc ShI ;
2) deux pipelines à 5 étages (U et V) pour exécuter des instructions de calcul d'entiers ;
3) des caches séparés d'instructions et de données du niveau L1 d'un volume de 8 Ko chacun ;
4) un bloc de calculs à virgule flottante FPU, organisé sous forme de pipeline ;
5) bloc de prédiction de branchement;
6) unité de contrôle de mémoire.
La plupart des commandes sont exécutées en un cycle d'horloge. En cas d'exécution de commandes complexes, le microcode étendu de la ROM des microprogrammes de commandes complexes est utilisé.
Les pipelines Pentium implémentent les 5 étapes traditionnelles d'exécution d'instructions (extraction, décodage d'une opération, lecture d'opérandes, écriture de résultats). Lors du calcul des opérations à virgule flottante, trois étapes supplémentaires sont ajoutées : X1 - conversion de données au format de complexité étendue, X2 - exécution de la commande FPU, WF - arrondir le résultat et l'écrire dans le fichier de registre FPU. Le pipeline U peut exécuter à la fois des instructions en nombres entiers et en virgule flottante. Cependant, les instructions arithmétiques à virgule flottante ne peuvent pas être associées à des instructions entières. De plus, le pipeline U contient un décaleur multi-bits utilisé pour effectuer des décalages arithmétiques, logiques, cycliques, des opérations de multiplication et de division. Pipeline V exécute uniquement des instructions entières.
L'utilisation de caches indépendants garantit un accès simultané et sans conflit. Le cache d'instructions est lié au tampon de prélecture par un bus de 256 bits. Si la commande sélectionnée est absente dans la mémoire cache, alors la commande requise est lue à partir de la mémoire principale et chargée dans le tampon de prélecture avec écriture simultanée dans le cache de commandes.
Le cache de données est connecté aux pipelines U et V à l'aide de deux bus 32 bits, ce qui permet d'y accéder simultanément depuis chaque pipeline.
L'unité de contrôle de mémoire effectue une formation en deux étapes de l'adresse physique de la cellule mémoire, d'abord dans le segment, puis dans la page. Un matériel spécial est utilisé pour contrôler le fonctionnement du cache externe.
Une innovation architecturale du Pentium est un mode spécial de gestion du système (SMM - System Management Mode), conçu pour mettre le système dans un état de consommation d'énergie réduite. Ce mode n'est pas disponible pour les applications et est contrôlé par le programme à partir de la ROM sur la puce du processeur. En mode SMM, le Pentium utilise un espace mémoire différent isolé des autres modes.
Le bloc ShI assure la communication entre le processeur et d'autres appareils via le bus système, qui comprend un bus de données 64 bits et un bus d'adresses 32 bits et un bus de contrôle. Le processeur Pentium prend en charge les systèmes avec jusqu'à 4 Go de mémoire physique.
Le développement des processeurs Pentium est associé tout d'abord à l'amélioration de leur technologie de production, à l'extension du jeu d'instructions, à l'amélioration des algorithmes de prédiction de branchement, des méthodes de chargement des pipelines et des méthodes d'interaction avec la mémoire cache.
Une particularité des Pentium 6ème (Pentium Pro, Pentium II, Pentium III) et 7ème (Pentium IV) générations des premiers modèles Pentium est une approche différente de la mise en œuvre du principe de traitement multiopérationnel des données. Il consiste en ce qu'au lieu d'augmenter le nombre de pipelines d'exécution d'instructions, ce qui nécessite des coûts matériels importants, on utilise un pipeline avec un grand nombre d'unités d'exécution. Par exemple, le traitement des instructions dans le Pentium IV est effectué par un pipeline à 20 étages (hyperpipeline), qui peut être conditionnellement divisé en 3 pipelines relativement indépendants :
1) Le pipeline d'entrée du traitement ordonné, qui fournit des instructions de récupération de la mémoire, les décodant en instructions RISC internes et éliminant les fausses relations pour les données et les ressources.
2) Le pipeline de traitement désordonné, qui met en œuvre l'exécution réelle des commandes. Chargement plus intensif des pipelines du processeur superscalaire en cas de traitement non ordonné. Pour garantir une exécution correcte du programme, les résultats des instructions dans le désordre doivent être écrits aux adresses cibles dans le même ordre qu'ils apparaissent dans le programme source. Ce travail est effectué par une unité de traitement spéciale - un bloc de stockage temporaire des résultats exécutés à tour de rôle.
3) Un pipeline pour sortir les résultats de l'exécution de la commande, qui écrit les résultats dans les registres architecturaux du processeur et de la mémoire dans l'ordre fourni par le programme.
Le fonctionnement efficace de l'hyperpipeline Pentium IV est également assuré par l'exécution spéculative d'instructions, lorsque des actions non prévues par le code du programme sont effectuées pour charger en continu le pipeline.
L'unité de prédiction de branchement utilise un algorithme de prédiction de branchement plus avancé par rapport aux processeurs Pentium antérieurs. Les adresses d'instruction de branchement et les marques de branchement avec un historique détaillé sont stockés dans une mémoire tampon (4 Ko) du bloc de prédiction de branchement.
Une autre différence importante entre le processeur Pentium IV et les modèles antérieurs est l'utilisation d'un cache de trace dans sa structure au lieu du cache d'instructions. Les sentiers Sont des séquences de micro-instructions dans lesquelles sont décodées des instructions x86 appartenant à une ou plusieurs branches du programme source. Le cache peut contenir jusqu'à 12 Ko de micro-instructions. Le cache de trace n'inclut pas les commandes qui ne seront jamais utilisées. Le cache de trace ainsi que l'unité d'extraction forment un dispositif de prétraitement.
L'utilisation d'un hyperpipeline, d'un cache de trace et d'un cœur d'exécution plus efficace a permis au Pentium IV de réaliser des gains de performances significatifs.
Modèle de programmation des processeurs Pentium.
La caractéristique unificatrice des microprocesseurs Pentium considérés est qu'ils ont tous, malgré d'importantes différences d'architecture, le même modèle logiciel. La totalité de tous les registres de processeur accessibles par programme le forme modèle de programme/ 2 /. Il montre les ressources du processeur qu'un programmeur peut utiliser.
Le modèle logiciel est subdivisé en application et système. Partie modèle de programmation appliqué Le processeur (PPM) comprend un ensemble complet de registres disponibles pour les programmeurs d'applications ; caractéristiques d'organisation de la mémoire et méthodes d'adressage disponibles; types de données et de commandes. Modèle de programmation système(SPM) combine ses logiciels disponibles ressources système qui donnent accès à des mécanismes de sécurité et de multitâche intégrés. Le processeur SPM est principalement utilisé par les programmeurs système.
Tous les microprocesseurs existants aujourd'hui peuvent être conditionnellement divisés en 4 groupes :SCRC (ComplexeInstructionRéglerCommander) - avec un ensemble complet d'instructions;RISC (RéduitInstructionRéglerCommander) - avec un jeu d'instructions tronqué;VLIW (TrèsLongueEntierMot) - avec un mot de commande extra-large ;DIVERS (Le minimumInstructionRéglerCommander) - avec un minimum d'instructions.
Les principaux représentants des transformateurs tels queSCRC - Cabinet MP Intelligencesont présentés dans le tableau 3.2.
Type de député RISC contiennent un ensemble abrégé d'instructions les plus couramment utilisées dans les programmes. Dans le cas où il est nécessaire d'exécuter une instruction complexe, le MP l'assemble à partir d'instructions simples. Une caractéristique de ces MP est que toutes les commandes simples sont exécutées dans le même laps de temps égal à un cycle machine.
REMARQUE
Les processeurs RISC sont fabriqués par diverses sociétés : IBM (Power PC), DEC (Alpha), HP (PA), Sun (Ultra SPARC) et autres.
Le représentant le plus célèbreRISC processeurs - MPPowerPC (PerformanceOptimiséAvecAmélioréordinateur) est utilisé dans les solutions de bureau et professionnelles de l'entreprisePomme, mais récemment Yabloko a annoncé le passage à l'architectureIntelligence... député RISCse caractérisent par des performances élevées, mais le logiciel n'est pas compatible avec les processeursSCRC... Par conséquent, pour exécuter des applications développées pourIBMordinateurordinateurs compatibles sur des machines telles quePommeMacintoshun "émulateur" est nécessaire, ce qui réduit drastiquement leur efficacité.
Tableau 3.2. Caractéristiques des microprocesseurs Intel
|
Modèle |
Décharge- la cohérence des données / adresses (bit) |
L'horloge La fréquence (MHz) |
Espace d'adressage (octets) |
Composition de l'équipe |
Diplôme d'intégration / technologie des procédés |
Tension Alimentation (V) |
Année d'émission |
|
4004 |
4 /4 |
0,108 |
2 300/10 m |
1971 |
|||
|
8080 |
8 /8 |
64K |
10 000 / 6 m |
1974 |
|||
|
8086 |
16 /16 |
4.77 et 8 |
70 000 / 3 m |
1979 |
|||
|
8088 |
8 , 16 /16 |
4.77 et 8 |
70 000 / 3 m |
1978 |
|||
|
80186 |
16/20 |
8 et 10 |
140 000 |
1981 |
|||
|
80286 |
16/24 |
8-20 |
16M |
180 000/ 1,5 µm |
1982 |
||
|
80386 |
32/32 |
16-50 |
4g |
275 000 / 1 m |
1985 |
||
|
80486 |
32/23 |
25-100 |
1.2 million / 1 micron |
1989 |
|||
|
Pentium |
64/32 |
60-233 |
3,3 millions / 0,5 et 0,35 µm |
1993 |
|||
|
Pentium Pro |
64/32 |
150-200 |
5,5 millions / 0,5 et 0,35 µm |
1995 |
|||
|
Pentium MMX |
64/36 |
166-233 |
57 (MMX) |
5 millions / 0,35 µm |
1997 |
||
|
Pentium II (noyau Katmai) |
64/36 |
233-600 |
MMX + (MMX2) |
7,5 millions / 0,25 µm |
1997 |
||
|
Celeron (noyau Mendocino) |
64/32 |
300-800 |
MMX2 |
19 millions / 0,25 et 0,22 µm |
1998 |
||
|
Pentium III (mine de cuivre) |
64/36 |
500-1000 |
MMX + 70 |
28 millions / 0,18 µm |
1,65 |
1999 |
|
|
Pentium III Xeon |
64/36 |
500-1000 |
MMX2 |
30 millions / 0,18 et 0,13 µm |
1,65 |
1999 |
|
|
Pentium 4 (Willamette) |
64/36 |
1000-3500 |
64g |
MMX 2 + 144 |
42 millions / 0,13 µm |
1,1-1,85 |
2000 |
Type de député VLIW contrairement au superscalaireSCRCles processeurs ont une implémentation de circuit beaucoup plus simple et reposent sur un logiciel. Les programmeurs n'ont pas accès auxVLIW-commandes, de sorte que tous les programmes d'application et système opérateur exécuté sur un logiciel spécial de bas niveau (CodeMorphing) qui traduit les instructionsSCRC-processeur en commandesVLIW... Matériel simplifiéVLIWvous permet de réduire considérablement la taille du MP et de réduire la production de chaleur et la consommation d'énergie.
VLIWles processeurs sont fabriqués par la sociétéTransméta- MP sous la marqueCrusoé, premier député VLIW de Intelligence sur le noyau Mercedutilisé l'ensemble des instructionsAI-64, cette technologie s'appelleÉPIQUE (ExplicitementParallèleInstructionL'informatique- calculs avec parallélisme explicite d'instructions).
REMARQUE
À Les processeurs VLIW peuvent être attribués au MP Elbrus 2000 - E 2k, attendu en 2002, développé par la société russe Elbrus. Il avait une petite taille (il était complètement caché derrière la pièce de 1 rouble). À l'heure actuelle, tous les développements de l'entreprise, ainsi que ses employés, travaillent au profit d'Intel.
Une grande partie du calcul scientifique et technique implique de travailler avec des vecteurs au lieu de scalaires, ce qui simplifie grandement les calculs. Considérons deux modèles d'organisation des calculs de grands programmes scientifiques -processeur massivement parallèle (déployer processeur ) et processeur vectoriel (vecteur processeur ). Un processeur massivement parallèle se compose d'un grand nombre de processeurs similaires qui effectuent les mêmes calculs sur différents ensembles de données. C'est une structure composée de plusieurs secteurs, représentant un treillisNxNéléments processeur/mémoire. Chaque secteur a sa propre unité de contrôle.
REMARQUE
Le premier processeur massivement parallèle au monde - ILLIAC IV (Université de l'Illinois), avait un réseau de 8x8 éléments processeur / mémoire (un secteur, il était censé construire 4 secteurs) avec une vitesse de 50 millions d'opérations par seconde. Les processeurs vectoriels sont produits par le célèbre Cray Research, qui a été fondé par Seymour Cray.
La différence processeur vectoriel est que toutes les opérations d'addition sont effectuées dans un bloc de sommation, qui a une structure en pipeline. Ce processeur aregistre vectoriel constitué d'un ensemble de registres standard. Ces registres sont chargés séquentiellement à partir de la mémoire avec une seule instruction. La commande d'addition ajoute les éléments de deux de ces vecteurs par paires, en les chargeant à partir de deux registres vectoriels dans un additionneur avec une structure vectorielle. En conséquence, un vecteur quitte l'additionneur.
Description et objectif des sous-traitants
Définition 1
CPU (CPU) - le composant principal d'un ordinateur qui effectue des opérations arithmétiques et opérations logiques défini par le programme, contrôle le processus de calcul et coordonne le travail de tous les appareils PC.
Comment processeur plus puissant, plus la vitesse du PC est élevée.
Commenter
L'unité centrale de traitement est souvent appelée simplement processeur, CPU (Central Processing Unit) ou CPU (Central Processing Unit), moins souvent - un cristal, une pierre, un processeur hôte.
Les processeurs modernes sont des microprocesseurs.
Le microprocesseur se présente sous la forme d'un circuit intégré- une fine plaque rectangulaire de silicium cristallin d'une superficie de plusieurs millimètres carrés, sur laquelle sont placés des circuits avec des milliards de transistors et des canaux pour le passage du signal. La plaque de cristal est placée dans un boîtier en plastique ou en céramique et reliée par des fils d'or avec des broches métalliques pour la connexion à la carte mère du PC.
Figure 1. Microprocesseur Intel 4004 (1971)

Figure 2. Microprocesseur Intel Pentium IV (2001). Gauche - vue de dessus, droite - vue de dessous
Le CPU est conçu pour exécuter automatiquement le programme.
Périphérique de processeur
Les principaux composants d'un processeur sont :
- Unité arithmétique et logique(ALU) effectue des opérations mathématiques et logiques de base ;
- dispositif de contrôle(UU), dont dépend la cohérence du travail des composants de la CPU et sa connexion avec d'autres appareils;
- bus de données et bus d'adresse;
- registres, dans laquelle la commande en cours, les données initiales, intermédiaires et finales (résultats des calculs ALU) sont temporairement stockées ;
- compteurs de commandes;
- mémoire cache stocke les données et les commandes fréquemment utilisées. L'accès à la mémoire cache est beaucoup plus rapide qu'à la RAM, par conséquent, plus elle est grande, plus la vitesse du processeur est élevée.
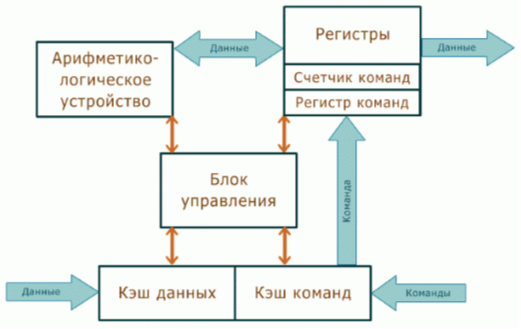
Figure 3. Schéma simplifié du processeur
Comment fonctionne le processeur
Le CPU fonctionne sous le contrôle d'un programme qui réside dans la RAM.
ALU reçoit des données et exécute l'opération spécifiée, en écrivant le résultat dans l'un des registres libres.
La commande en cours se trouve dans le registre de commandes spécial. Lorsque vous travaillez avec la commande actuelle, la valeur du soi-disant compteur de commandes augmente, qui pointe alors vers la commande suivante (la seule exception peut être la commande de saut).
La commande consiste en un enregistrement de l'opération (à effectuer), des adresses des cellules des données sources et du résultat. Aux adresses spécifiées dans la commande, les données sont prises et placées dans des registres ordinaires (au sens pas dans le registre de commande), le résultat résultant est également d'abord placé dans le registre, puis seulement déplacé à son adresse spécifiée dans la commande.
Spécifications du processeur
Fréquence d'horloge indique la fréquence à laquelle le CPU fonctionne. Plusieurs opérations sont effectuées pour 1 $ d'horloge. Plus la fréquence est élevée, plus la vitesse du PC est élevée. Fréquence d'horloge processeurs modernes mesuré en gigahertz (GHz) : 1 $ GHz = 1 milliard de cycles d'horloge par seconde.
Pour améliorer les performances du processeur, ils ont commencé à utiliser plusieurs cœurs, chacun étant effectivement un processeur distinct. Plus il y a de cœurs, meilleures sont les performances du PC.
Le processeur est connecté à d'autres dispositifs (par exemple, à la mémoire principale) via les bus de données, d'adresses et de contrôle. La largeur du bus est un multiple de 8 (puisqu'il s'agit d'octets) et diffère pour différents modèles et est également différent pour le bus de données et le bus d'adresse.
La largeur du bus de données indique la quantité d'informations (en octets) pouvant être transférée en 1 $ fois (pour 1 $ d'horloge). La quantité maximale de RAM avec laquelle la CPU peut fonctionner dépend de la largeur de bit du bus d'adresse.
De la fréquence bus système la quantité de données qui est transmise sur une période de temps dépend. Pour les PC modernes, pour un cycle d'horloge à 1 $, vous pouvez transférer plusieurs bits. La bande passante du bus est également importante, qui est égale à la fréquence du bus système multipliée par le nombre de bits pouvant être transférés pour 1 $. Si la fréquence du bus système est de 100 $ MHz et que 2 $ de bits sont transférés par horloge à 1 $, alors la bande passante est de 200 $ Mbit/s.
La bande passante des PC modernes se mesure en gigabits (ou dizaines de gigabits) par seconde. Plus le nombre est élevé mieux c'est. La quantité de mémoire cache affecte également les performances du processeur.
Les données pour le fonctionnement de la CPU proviennent de la RAM, mais depuis Étant donné que la mémoire est plus lente que le processeur, elle peut souvent être inactive. Pour éviter cela, la mémoire cache est placée entre le CPU et la RAM, qui est plus rapide que la RAM. Cela fonctionne comme un tampon. Les données de la RAM sont envoyées au cache puis au CPU. Lorsque le CPU a besoin des données suivantes, alors si elles se trouvent dans la mémoire cache, elles en sont extraites, sinon la RAM est accédée. Si le programme exécute séquentiellement une commande après l'autre, alors lorsqu'une commande est exécutée, les codes des commandes suivantes sont chargés de la mémoire principale dans le cache. Cela accélère considérablement le travail, car L'attente du processeur est réduite.
Remarque 1
Il existe trois types de mémoire cache :
- Le cache $ 1 $ -th level est le plus rapide, il est situé dans le cœur du CPU, donc il est petit (8-128 Ko).
- Le cache $ 2 $ -th level est dans le CPU, mais pas dans le noyau. Il est plus rapide que la RAM, mais plus lent que le cache de niveau 1 $. Tailles de 128 $ Ko à plusieurs Mo.
- Le cache de niveau $ 3 $ est plus rapide que la RAM, mais plus lent que le cache de niveau $ 2 $.
La vitesse du processeur et, par conséquent, de l'ordinateur dépend de la quantité de ces types de mémoire.
Le CPU ne peut supporter qu'un certain type de RAM : $ DDR $, $ DDR2 $ ou $ DDR3 $. Plus ça marche vite RAM, plus les performances du processeur sont élevées.
La caractéristique suivante est le socket (socket) dans lequel le CPU est inséré. Si le CPU est conçu pour un certain type de socket, il ne peut pas être installé dans un autre. Pendant ce temps, il n'y a qu'un seul socket CPU sur la carte mère et il doit correspondre au type de ce processeur.
Types de processeurs
Intel est le principal fabricant de processeurs pour PC. Le premier processeur PC était le processeur à 8086 $. Le modèle suivant était de 80286 $, puis de 80386 $, au fil du temps, le chiffre de 80 $ a été abandonné et le processeur a commencé à être appelé à trois chiffres : 286 $, 386 $, etc. La génération de processeurs est souvent appelée la famille $ x86 $. D'autres modèles de processeurs sont également disponibles, par exemple la famille Alpha, Power PC, etc. Les fabricants de processeurs sont également AMD, Cyrix, IBM, Texas Instruments.
Dans le nom du processeur, on retrouve souvent les symboles $ X2 $, $ X3 $, $ X4 $, ce qui signifie le nombre de cœurs. Par exemple, dans le nom Phenom $ X3 $ $ 8600 $ les symboles $ X3 $ indiquent la présence de trois cœurs.
Ainsi, les principaux types de CPU sont 8086 $, 80286 $, 80386 $, 80486 $, Pentium, Pentium Pro, Pentium MMX, Pentium II, Pentium III et Pentium IV. Celeron est une version allégée du processeur Pentium. Le nom est généralement suivi de la vitesse d'horloge du processeur. Par exemple, Celeron 450 $ désigne le type de processeur Celeron et sa vitesse d'horloge est de 450 $ MHz.
Le processeur doit être installé sur carte mère avec la fréquence du bus système correspondant au processeur.
V derniers modèles Le processeur a mis en œuvre un mécanisme de protection contre la surchauffe, c'est-à-dire Lorsque la température dépasse la température critique, le processeur passe à une fréquence d'horloge inférieure, à laquelle moins d'énergie est consommée.
Définition 2
Si dans système informatique plusieurs processeurs parallèles, alors de tels systèmes sont appelés multiprocesseur .
L'IBM PC d'origine et l'IBM PC XT utilisaient un microprocesseur Intel-8088. Au début des années 80, ces microprocesseurs ont été produits avec une fréquence d'horloge de 4,77 MHz, puis des modèles avec une fréquence d'horloge de 8, 10 et 12 MHz ont été créés. Les modèles avec des performances accrues (vitesse d'horloge) sont parfois appelés TURBO-XT. Désormais, les microprocesseurs tels que l'Intel-8088 sont produits en petites quantités et pour être utilisés non pas dans un ordinateur, mais dans divers appareils spécialisés.
Le modèle IBM PC AT utilise le microprocesseur Intel-80286 plus puissant et ses performances sont environ 4 à 5 fois supérieures à celles de l'IBM PC XT. Les versions originales de l'IBM PC AT fonctionnaient sur des microprocesseurs avec une fréquence d'horloge de 12 à 25 MHz, c'est-à-dire qu'elles fonctionnaient 2 à 3 fois plus rapidement. Le microprocesseur Intel-80286 a légèrement plus de fonctionnalités que l'Intel-8088, mais ces fonctionnalités supplémentaires sont rarement utilisées, donc la plupart des programmes basés sur AT fonctionneront également sur le XT. Désormais, les microprocesseurs tels que l'Intel-80286 sont également considérés comme obsolètes et ne sont pas produits pour être utilisés dans les ordinateurs.
1988-1991 la plupart des ordinateurs produits étaient basés sur un microprocesseur Intel-80386 assez puissant, développé par par Intel en 1985. Ce microprocesseur (également appelé 80386DX) est 2 fois plus rapide qu'un 80286 à la même vitesse d'horloge. La plage de fréquence d'horloge typique du 80386DX est de 25 à 40 MHz. En outre, Intel a également développé le microprocesseur Intel-80386SX, il n'est pas beaucoup plus cher que Intel-80286, mais il a les mêmes capacités que Intel-80386, mais à une vitesse inférieure (environ 1,5 à 2 fois).
Le microprocesseur Intel-80386 est non seulement plus rapide que l'Intel-80286, mais il a également beaucoup plus de capacités, en particulier, il contient des outils puissants pour les opérations 32 bits (par opposition aux 80286 et 8088 16 bits).
Ces outils sont largement utilisés par les fabricants de logiciels, de sorte que de nombreux programmes actuellement publiés sont destinés à être utilisés uniquement sur des ordinateurs équipés de microprocesseurs Intel-80386 ou supérieurs.
Lors de la création du microprocesseur Intel-80386, Intel l'a considéré comme le microprocesseur le plus avancé, offrant des performances suffisantes pour la plupart des tâches. Cependant, il a reçu la plus large distribution depuis 1990-1991. L'environnement d'exploitation Windows de Microsoft a considérablement augmenté les besoins en ressources informatiques sur l'ordinateur et, dans de nombreux cas, le fonctionnement des programmes Windows sur un ordinateur équipé d'un microprocesseur Intel-80386 s'est avéré trop lent. Par conséquent, au cours de 1991-1992. la plupart des fabricants d'ordinateurs sont passés au microprocesseur Intel-80486 (ou 80486DX) plus puissant. Ce microprocesseur diffère peu de l'Intel-80386, mais ses performances sont 2 à 3 fois supérieures. Parmi ses fonctionnalités, citons la mémoire cache intégrée et le coprocesseur mathématique intégré. Intel a également développé une variante moins chère mais moins puissante -80486SX et des variantes plus chères et plus rapides -80486DX2 et DX4. Les fréquences d'horloge du 80486 se situent généralement dans la plage de 25 à 50 MHz, le 80486DX2 de 50 à 60 MHz et le DX4 jusqu'à 100 MHz.
En 1993, Intel a sorti un nouveau microprocesseur Pentium (précédemment annoncé comme 80586). Ce microprocesseur est encore plus puissant, notamment lors de calculs sur des nombres réels. Comme Intel-80486, il contient un coprocesseur mathématique intégré, et il est beaucoup plus efficace que celui d'Intel-80486. Pour augmenter les performances, d'autres améliorations ont été apportées au Pentium : une autoroute de transmission de données plus rapide et plus large (bus de données), une grande taille de la mémoire cache intégrée, la possibilité d'exécuter deux instructions en même temps, etc. L'horloge la fréquence des microprocesseurs Pentium produits est de 60 à 233 MHz. Dans le même temps, les microprocesseurs Pentium fonctionnent 1,5 à 2 fois plus vite que les 80486 microprocesseurs avec la même fréquence d'horloge, et pour les tâches nécessitant des calculs intensifs sur des nombres réels, 3 à 4 fois plus vite.
Fin 1996 - début 1997, Intel a lancé le processeur amélioré Pentium MMX (MMX - Multimedia Extension). Bien qu'elle semble peu différente de son prédécesseur, l'architecture des équipes a subi des changements importants. Dans le jeu d'instructions du microcircuit, 57 nouveaux sont apparus. Ils sont conçus pour effectuer des tâches liées au traitement de données audio, vidéo, graphiques et de télécommunications.
Afin d'accueillir de nouvelles fonctionnalités dans le package Pentium existant, la société a dû faire quelques compromis, à savoir que les processeurs avec MMX ne peuvent pas exécuter simultanément les instructions MMX et les opérations à virgule flottante, car les instructions MMX et les nombres à virgule flottante sont utilisés de la même manière dans les mêmes registres. du coprocesseur intégré. Et cela a été fait pour préserver l'entière compatibilité du Pentium ММХ avec le logiciel existant. Ce n'est pas un gros problème car peu de programmes utilisent le coprocesseur. Cependant, s'il existe des applications qui nécessitent que le processeur bascule fréquemment entre les opérations à virgule flottante et MMX, elles s'exécuteront plus lentement sur un processeur MMX que sur un processeur ordinaire avec la même vitesse d'horloge.
Intel Corporation a officiellement présenté le processeur Pentium II le 7 mai 1997. Le processeur est disponible avec une fréquence d'horloge de 233 MHz et 300 MHz, et est conçu pour une alimentation de 2,8 V. La principale nouveauté est que le Pentium II n'est pas compatible avec les cartes mères existantes pour le Pentium. Nouveau processeur sera monté dans une cartouche S.E.C (Single Edge Contact). Le boîtier de la cartouche entièrement fermé protège les composants et la plaque du dissipateur thermique permet d'utiliser n'importe quel dissipateur thermique pour la dissipation thermique passive ou active. Grâce à cela, la dissipation thermique pour un modèle avec une fréquence d'horloge de 233 MHz ne dépasse pas 38,2 W (à titre de comparaison : le Pentium 200 MHz émet 37,9 W). La cartouche S.E.C s'adaptera à l'emplacement 1, qu'Intel a introduit comme nouvelle norme technologique pour le facteur de forme des ordinateurs.
En janvier 1999, Intel a officiellement présenté son microprocesseur pour PC Pentium III. Selon le porte-parole de la société Seth Walker, le Pentium III devrait faire avancer la technologie sur plusieurs fronts, notamment la vitesse d'horloge (les premiers modèles de processeur fonctionneront à 450 et 500 MHz), le traitement graphique, la vitesse et la fiabilité d'Internet. Le plan de développement ultérieur de la famille de produits Pentium III prévoit le passage de la norme technologique de 0,25 micron à 0,18 micron (le nom de travail du microprocesseur correspondant est Coppermine). Le passage de 0,25 micron à 0,18 micron entraînera une augmentation de ses performances et une diminution de la consommation électrique. Cela portera la vitesse des cristaux jusqu'à 600 MHz et plus. Les vitesses d'horloge des premiers processeurs Pentium III de 0,25 micron seront de 450 et 500 MHz. De nouvelles instructions ont été ajoutées au processeur. Ce jeu d'instructions, nommé Katmai New Instructions, vise à améliorer les performances graphiques. En outre, cela aidera à accélérer la vidéo, l'audio, la reconnaissance vocale et d'autres technologies similaires. En mars 2001, Intel a lancé le processeur Xeon 900 MHz, le dernier membre de la famille Pentium III. Ce processeur est équipé d'un cache L2 de 2 Mo pour des performances améliorées.
En novembre 2000, Intel a confirmé son intention de sortir le microprocesseur Pentium 4 et a annoncé son intention de migrer les PC de bureau grand public du Pentium III vers le Pentium 4 d'ici la fin 2001. Le processeur Pentium 4 est basé sur la microarchitecture Intel NetBurst. Il s'agit de la première microarchitecture de bureau fondamentalement nouvelle que la société a développée au cours des cinq dernières années depuis la sortie de la microarchitecture Pentium Pro P6 en 1995. L'architecture NetBurst utilise plusieurs nouvelles technologies : la technologie Hyper Pipelined avec une profondeur de pipeline deux fois supérieure à celle du Pentium III ; Moteur d'exécution rapide, qui améliore les performances lorsque vous travaillez avec des données entières en s'exécutant à une fréquence d'horloge deux fois supérieure à celle du cœur principal ; et le cache de trace d'exécution stockant les instructions déjà « décodées » ; ainsi, le retard dans l'analyse des sections de code réexécutées est éliminé.
Le processeur Pentium 4 contient 42 millions de transistors sur une puce, est équipé d'un cache de 256 Ko et dispose de 144 nouvelles instructions, appelées Streaming SIMD-2 Extensions (SSE2), qui accélèrent le traitement des blocs de données à virgule flottante. Comme base pour les plates-formes basées sur Pentium 4, Jeu de puces Intel 850. Jusqu'à présent, il s'agit du seul chipset du marché conçu pour le nouveau processeur. Le chipset prend en charge la RAM Rambus Direct (RDRAM) double canal avec une bande passante de 1,6 Go/s par canal et un bus système de 400 MHz avec une bande passante allant jusqu'à 3,2 Go/s. En fait, la fréquence d'horloge du bus système est de 100 MHz, et quatre opérations sont effectuées par cycle d'horloge (une solution similaire est utilisée dans AGP 4x). Intel a également présenté la première carte de bureau ATX D850GB basée sur le nouveau chipset. Actuellement, il existe des versions 1,4, 1,5 et 1,7 GHz du Pentium 4. Elles sont fabriquées à l'aide de la technologie 0,18 micron.
Selon des analystes de premier plan, en 2001, les fabricants de puces électroniques franchiront le cap des 2 GHz : de nouvelles technologies pour la production de microcircuits semi-conducteurs, notamment le dépôt sur films polymères et la super-miniaturisation, permettront aux fabricants de franchir la ligne des 2 GHz.
Structure du microprocesseur.
Un microprocesseur est un dispositif semi-conducteur composé d'un ou plusieurs LSI contrôlés par logiciel, comprenant tous les moyens nécessaires au traitement et au contrôle de l'information, et est conçu pour fonctionner avec la mémoire et les dispositifs d'entrée-sortie d'informations.
Le microprocesseur se compose de trois unités principales :
Arithmétique-logique
Bloc d'enregistrement
Appareils de controle
Unité arithmétique et logique (ALU) - effectue toutes les conversions de données arithmétiques et logiques.
Un dispositif de commande est une unité électronique d'un ordinateur qui comprend des dispositifs, des blocs, des éléments électroniques et des circuits, en fonction du contenu de la commande en cours.
Registre - une cellule mémoire sous la forme d'un ensemble de déclencheurs conçus pour stocker une donnée en code binaire.
Le nombre de bits dans le registre est déterminé par la capacité du microprocesseur
Registres à usage général - forment une super-opération et sont utilisés pour stocker les opérandes impliqués dans les calculs, ainsi que les résultats des calculs.
L'opérande est appelé - les données initiales, sur lesquelles diverses opérations sont effectuées dans l'unité arithmétique.
Registre de commande - sert à stocker la commande en cours d'exécution à l'heure actuelle.
Compteur de commandes - un registre indiquant l'adresse de la cellule mémoire où la prochaine commande est stockée.
Pile (mémoire de pile) - une collection de registres interconnectés pour stocker des données ordonnées. Le premier est extrait de la pile étant donné le dernier qui y est arrivé, et vice versa.